







论文笔记 | 【CVPR-2023】Activating More Pixels in Image Super-Resolution Transformer
抛砖引玉了,如有不同意见欢迎讨论。
目录

在超分Transformer中激活更多像素。
澳门大学、中科大、上海人工智能实验室的,董超老师的团队。
CVPR2023。
1 Motivation
LAM:一种为SR任务设计的归因方法,能显示模型在进行超分辨率重建的过程中哪些像素起到了作用。一般来说,被利用像素的范围越大,重建的效果往往越好。

被利用像素的范围:定性看红色区域的范围;定量看DI(diffusion index),越大越好。
这个结论在EDSR和RCAN很显著,但是在SwinIR和RCAN相比就不成立。
-
问题:SwinIR的性能更好,但是使用的像素范围更小。
本文认为:SwinIR结构拥有更强的局部表征能力,能够使用更少的信息来达到更高的性能。 -
问题:SwinIR虽然性能好,但是恢复出的图像纹理是错的。
本文认为:是因为SwinIR的信息使用范围有限,窗口自注意力机制限制了信息的使用范围。SwinIR依然有较大提升空间,如果更多的像素能够被利用,那么应该会取得更大的性能提升。 -
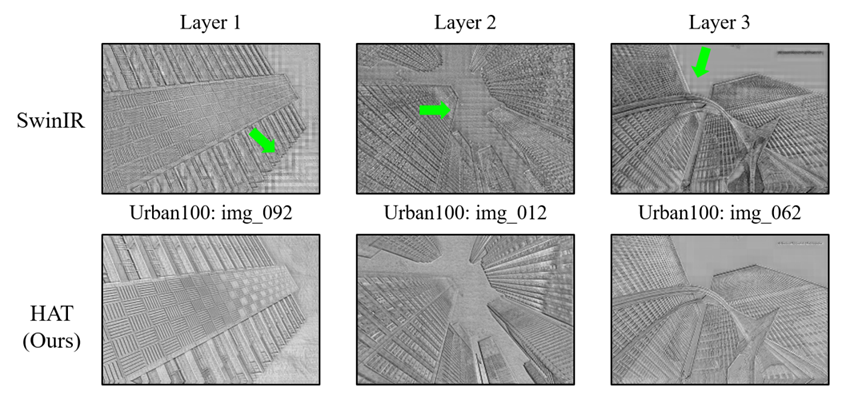
另外,文章发现,SwinIR网络前几层产生的中间特征会出现明显的块状效应。
文章认为,这是由于模型在计算自注意力时的窗口划分导致的,因此认为现有结构进行跨窗口信息交互的方式也应该被改进。
2 Contribution
- 1)设计了一种HAT(混合注意力transformer),结合自注意力、通道注意力和设计的重叠交叉注意力,激活更多的像素以更好地重建。
- 2)同任务预训练策略,进一步挖掘SR-Transformer的潜力。表明了大规模数据集预训练对任务的重要性。
- 3)SOTA。
3 Method
3.1 Overview
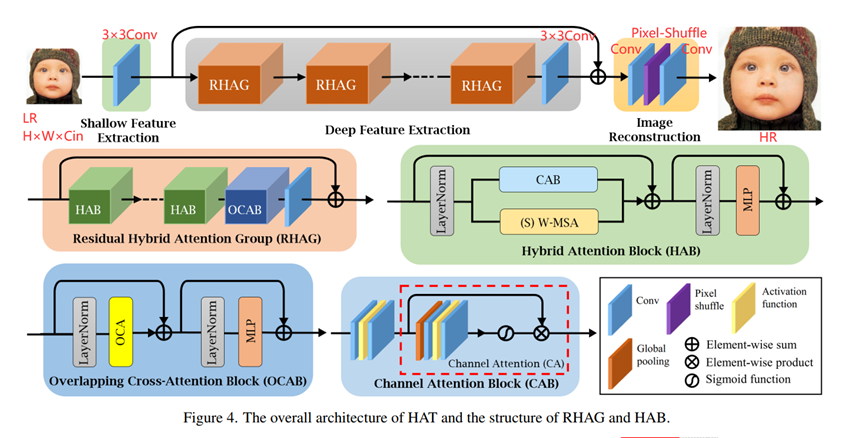
3.2 HAB (Hybrid Attention Block)
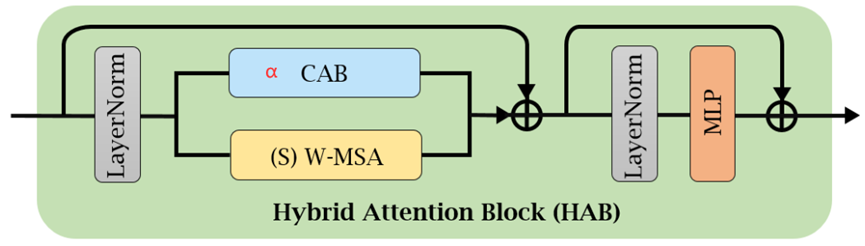
和SwinT Block一样,串联了CAB模块。
通道注意力: 利用全局信息;自注意力:强大表征能力。HAB同时结合两者优势。
SwinT模块的输入输出是同维度,CAB模块也是,所以可以直接实现三个矩阵相同位置元素叠加。
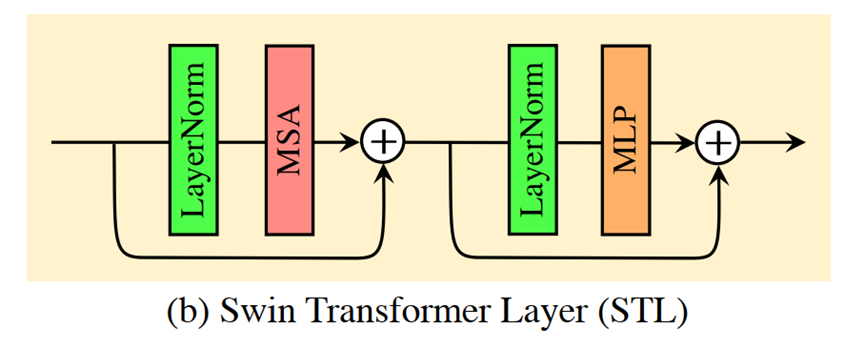
(SwinT:)
3.2.1 Channel Attention
本质:对特征的各个通道的重要性进行学习,分配不同的权重。
代表模型:Squeeze-and-Excitation Networks (SENet)
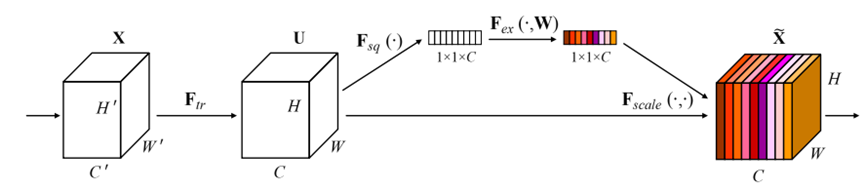
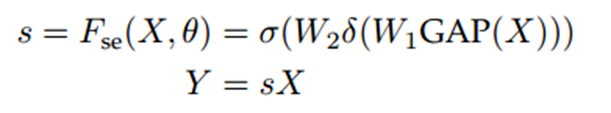
对于H×W×C的input元素特征图:
压缩:全局平均池化,压缩通道 [H, W] -> [1, 1]
激励:全连接层1 -> Relu -> 全连接层2 -> sigmoid (学习各个通道权重的重要性,激活函数)
维度变换:[H×W×C] ->[1×1×C]->[1×1×n1]->[1×1×C]
3.2.2 CAB

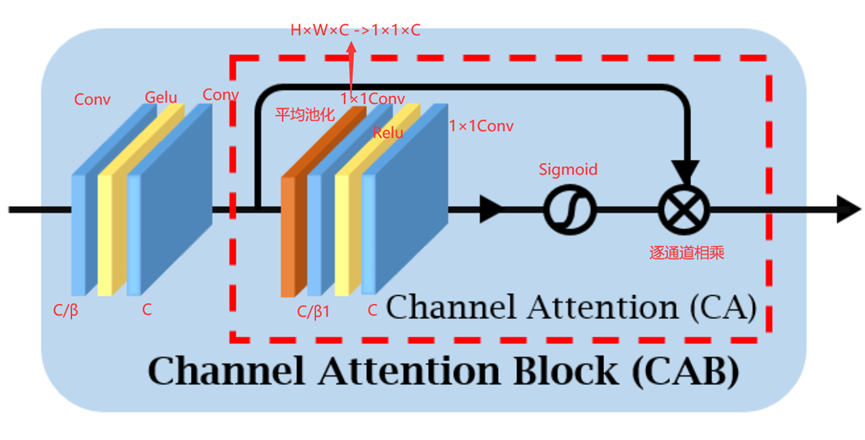
经过卷积,gelu,卷积。这部分,不知道要做什么。但是压缩通道是为了节省参数。
后面是CA模块。平均池化是压缩特征尺度,区别于上面的全连接层,这里使用1*1卷积来学习通道权重。
3.2.3 OCAB (Overlapping Cross-Attention Block)

也是仿照Swin-T模块,替换自注意力机制变成自己设计的OCA模块,Overlapping Cross-Attention,重叠交叉注意力。
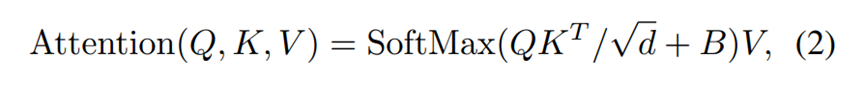
普通注意力:
QKV是由同一个X矩阵(HWC),分别乘上不同的CC矩阵,变成XQ,XK,XV,然后按照窗口划分QKV,在窗口内使用公式计算。
OCA:
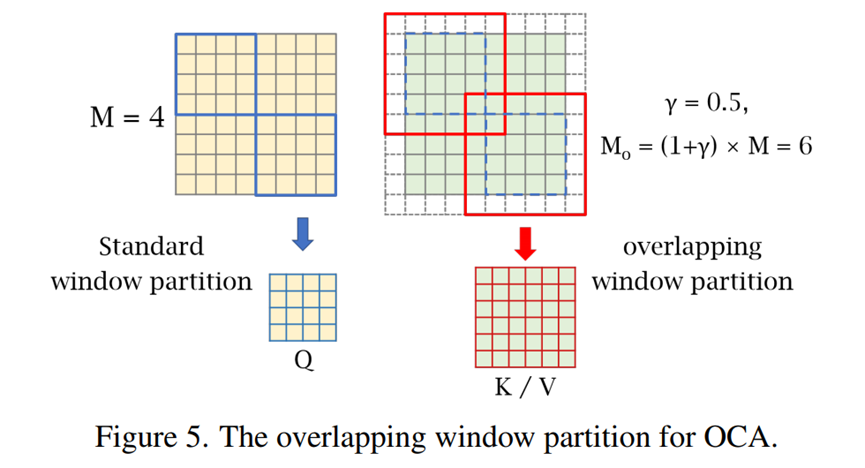
同样一个XQ矩阵,划分成MM大小的窗口,窗口内计算Q。
XK和XV的窗口划分要更大。先在周围做一圈零填充,宽度是γM/2。
然后划分成M0M0,step=M的窗口,作为K和V,再与Q计算注意力。M0通过公式计算得到。
维度不一样的问题,使用广播机制扩充Q的维度。
结果:允许attention跨窗口计算,加强了相邻窗口的信息交互,减弱块效应。
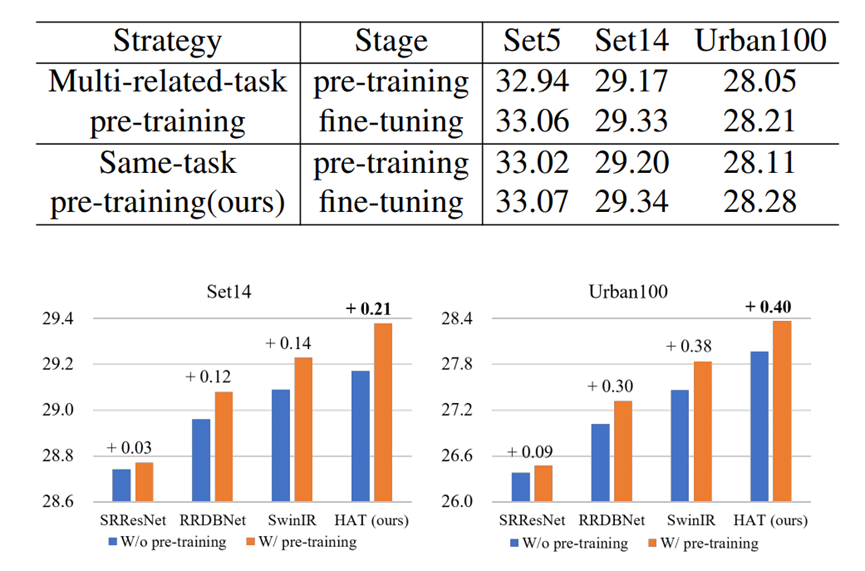
3.3 The Same-task Pre-training
之前工作:
various low-level tasks / different degradation levels of a specific task
本文:
同任务、大规模数据集ImageNet预训练。
比如:×4模型。先在ImageNet进行×4的预训练,然后在特定数据集微调(使用小学习率)。
文章认为,是因为Transformer需要更多的数据和迭代学习任务的一般知识。
4 Experiment
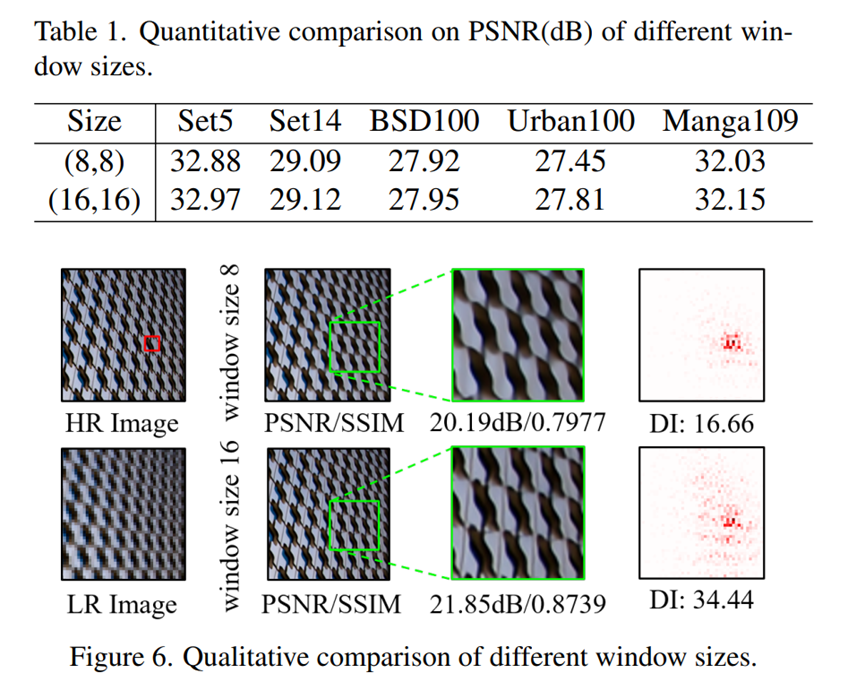
首先做了一个实验。在SwinIR验证,自注意力的窗口越大,越有利于性能的提升。
所以选用了16的窗口大小。
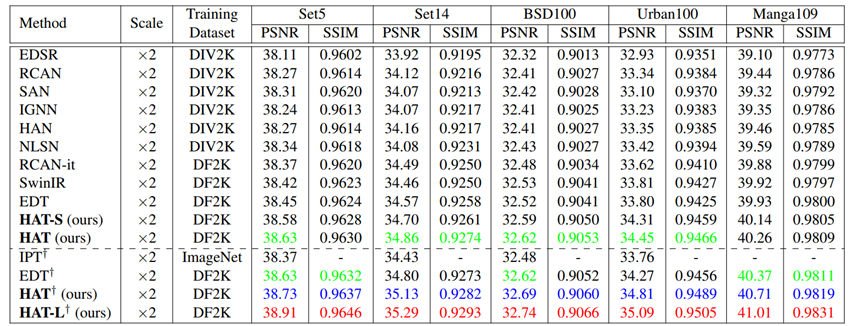
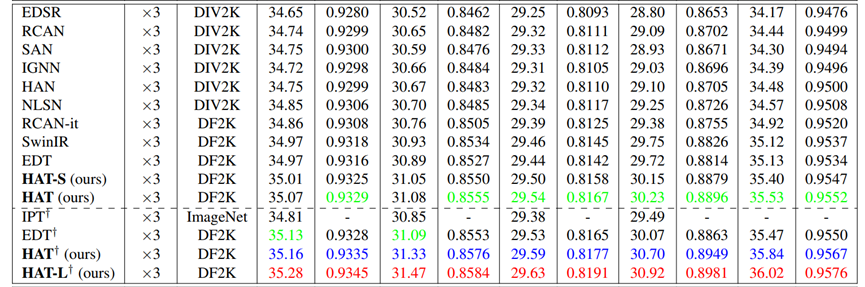
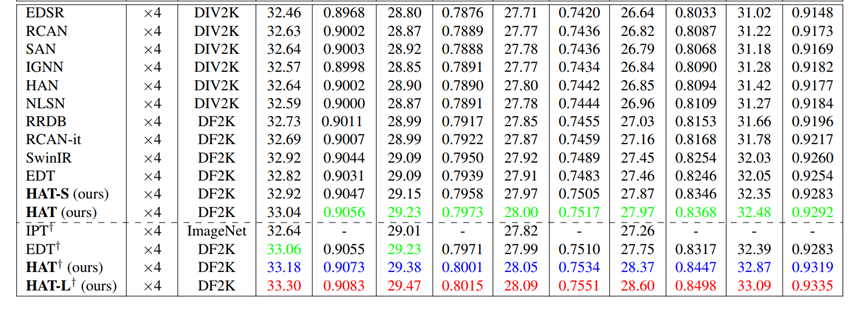
主实验:
训练数据集:DF2K ( DIV2K + Flicker2K )
RHAG:6
HAB:6
Channel:180
Attention head number:6
Window size:16
α(HAB):0.01
β(CAB):3
重叠比γ:0.5
另提供2个版本的模型:
HAT-L:RHAG:12(ori:6)
HAT-S:channel:144(ori:180)
5 Ablation study
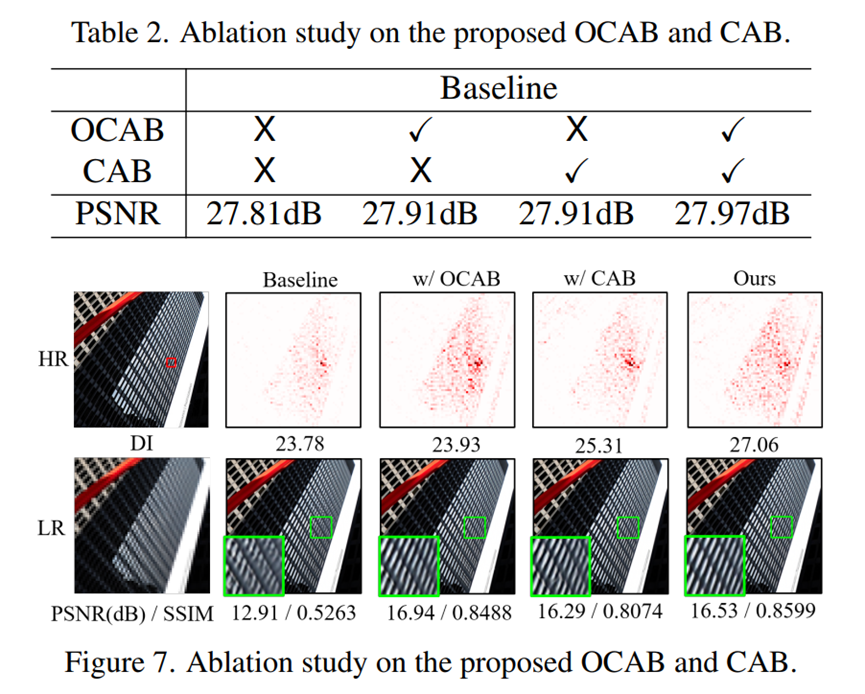
OCAB、CAB
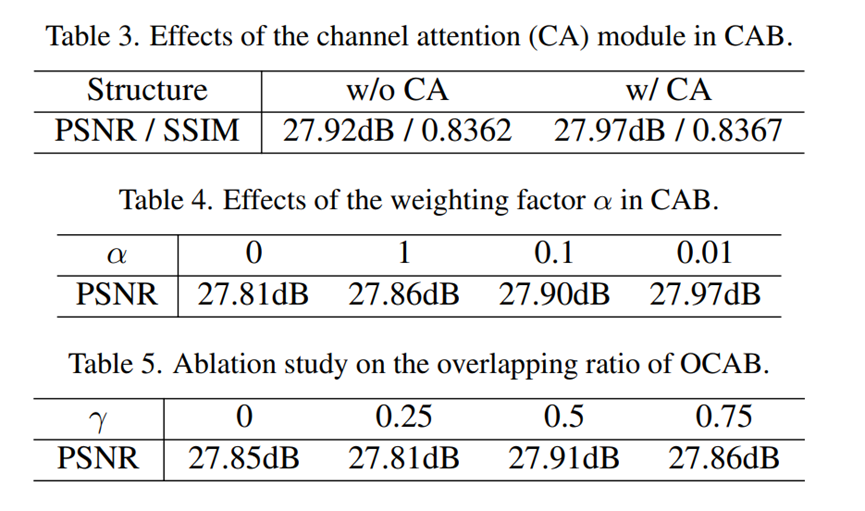
Channel attention、α、γ
Pre-training strategy

















 251
251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









