








 本文介绍了对SwinIR的三项关键改进:引入ChannelAttention增强全局能力,提出overlappingcross-attention模块促进跨窗口信息交互,以及预训练策略以弥补Transformer的局限。作者通过解决SwinIR的不足,提升模型性能并减少blockartifacts。
本文介绍了对SwinIR的三项关键改进:引入ChannelAttention增强全局能力,提出overlappingcross-attention模块促进跨窗口信息交互,以及预训练策略以弥补Transformer的局限。作者通过解决SwinIR的不足,提升模型性能并减少blockartifacts。
code:https://github.com/XPixelGroup/HAT
paper: https://arxiv.org/abs/2309.05239
1. 概述
本文是对Swinir的改进,目前很多图像超分Benchmark的SOTA。相对于SwinIR的改进主要有三个地方:1. 引入Channel Attention,以获得更好的全局能力;2. 提出了overlapping cross-attention模块,来进行跨window的信息交互;3. 提出一个预训练策略。
2. 引言
2.1 阐明swinir存在的问题
-
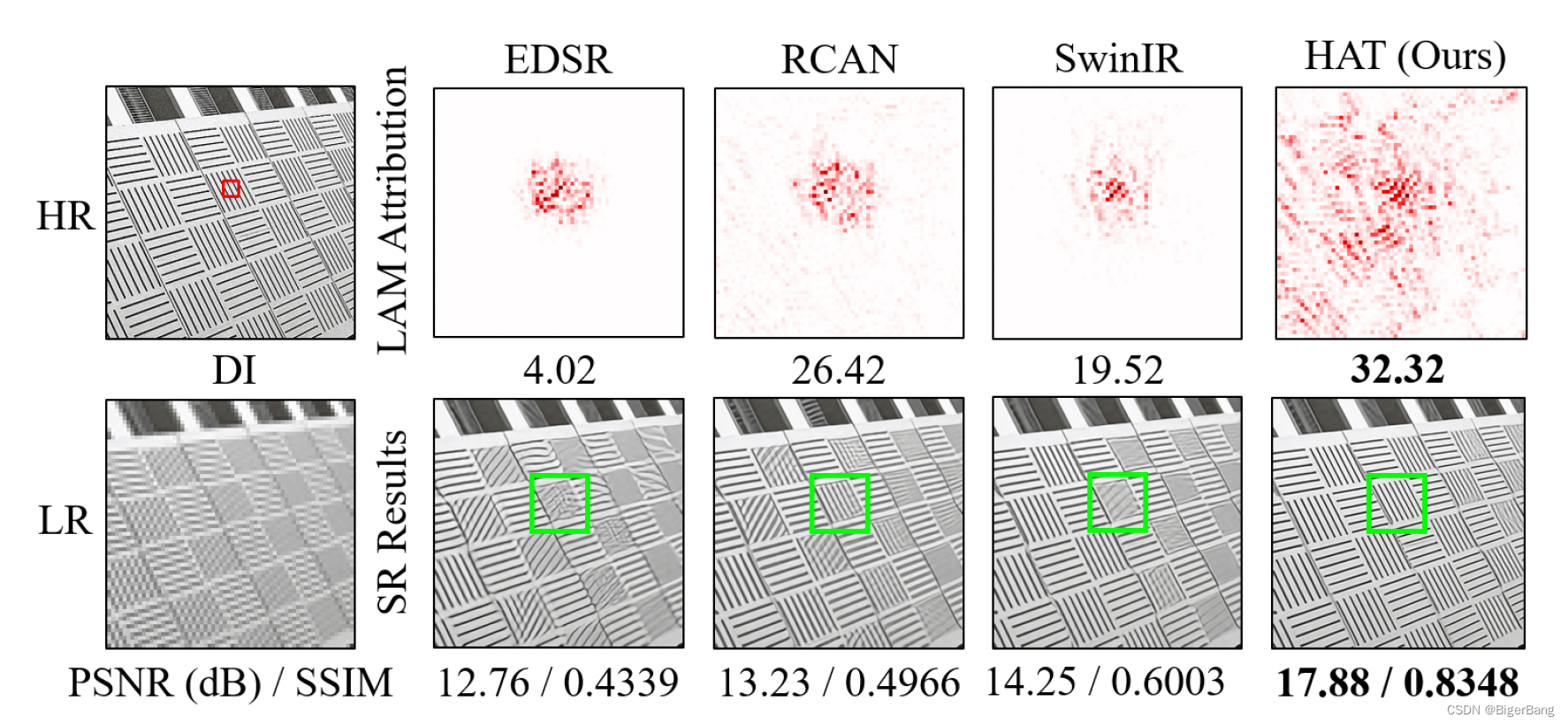
SwinIR在SR任务上取得了突破,然而为什么Transformer-based方法要比CNN-based方法好,却很难说清楚。一个直观的解释是Transformer方法可以受益于self-attention机制,并能够利用远距离信息。作者通过LAM分析发现,与RCAN相比,SwinIR并没有利用更大range的信息,这是反直觉的。同时可以说明SwinIR具备比CNN强的映射能力,可以利用更少的信息取得更好的效果。但是由于利用的pixel的范围有限,SwinIR可能会restore出错误的纹理。如下图所示。
-
尽管平均性能优于RCAN,但是有一些结果也比RCAN差
-
这说明Swin transformer建模局部信息的能力很强,但是探索的信息范围需要扩大
-
在SwinIR的特征图上发现了block artifacts,这是由于窗口划分造成的,这说明移动窗口机制并不能有效的建立跨窗口的交互。。

2.2 本文的贡献:
-
设计了一个Hybrid Attention,结合了channel attention, self-attention和overlapping cross-attention;
channel attention:具备很好地获取全局信息的能力
self-attention: 强大的表达能力(representative ability) -
提出一个预训练策略
因为transformer不具备cnn的归纳偏置,所以需要大规模数据进行预训练,才能解锁潜力。
3. 方法介绍
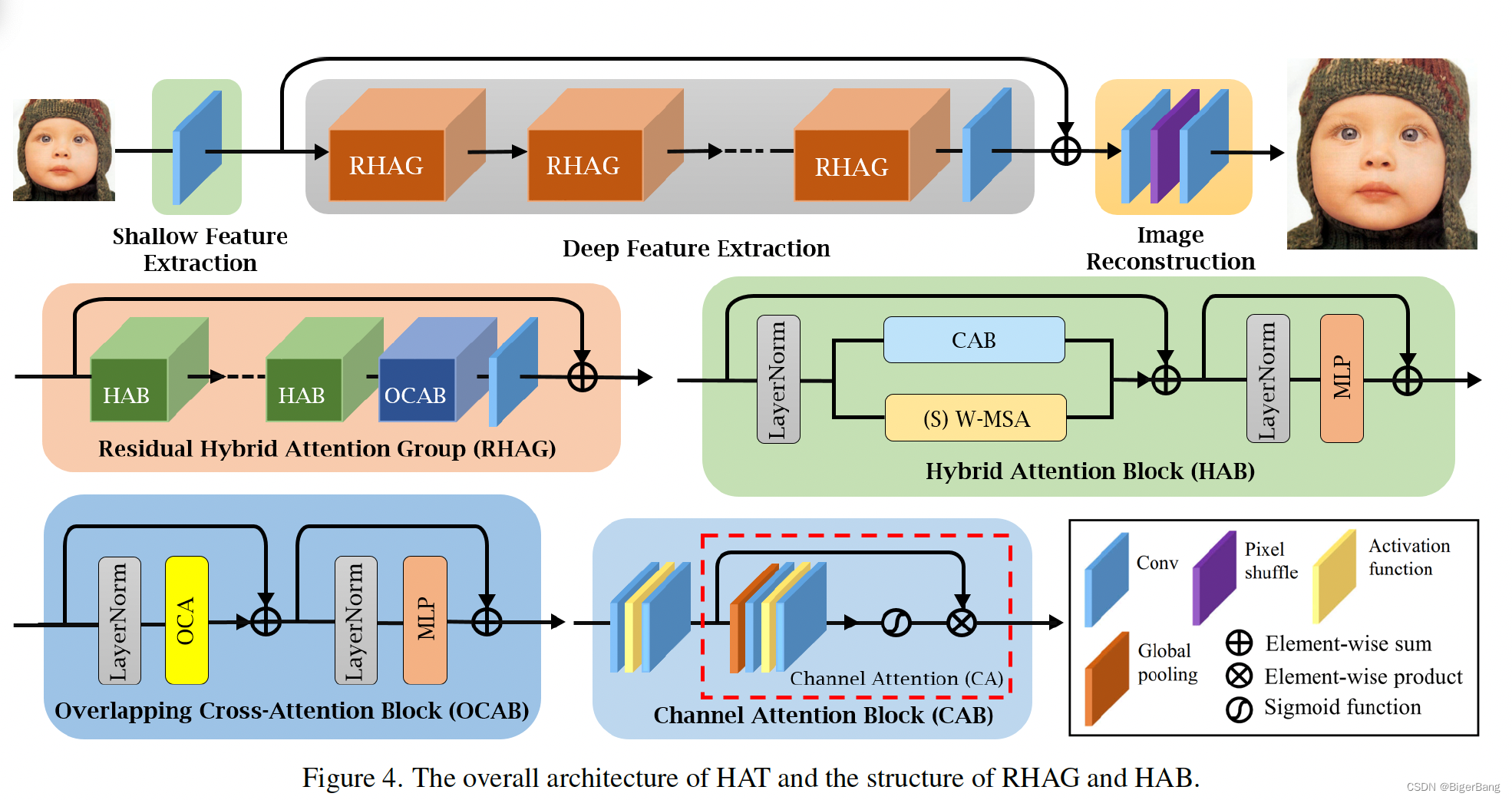
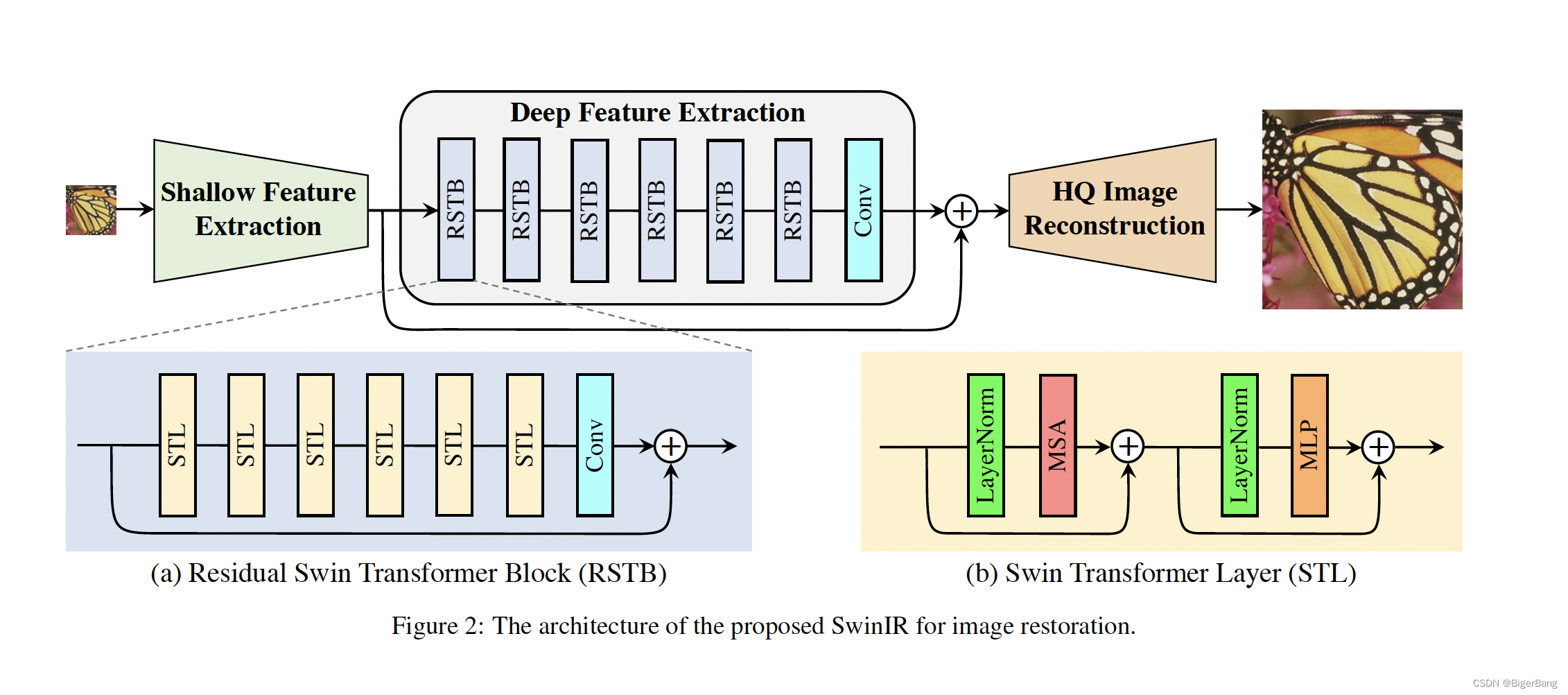
上面两张图分别是HAT和SwinIR的整体结构图,可以看出HAT延续了SwinIR的基本结构,将RSTB升级成RHAG,内部的STL也对应升级成HAB,并且在每个Block中加入了一个OCAB。下面具体来看这两处改动。
-
向(STL)Swin Transformer Layer中加入了Channel Attention,也就是将(S)W-MSA与CAB的结果叠加起来。
CAB的代码实现:
class ChannelAttention(nn.Module): """Channel attention used in RCAN. Args: num_feat (int): Channel number of intermediate features. squeeze_factor (int): Channel squeeze factor. Default: 16. """ def __init__(self, num_feat, squeeze_factor=16): super(ChannelAttention, self).__init__() self.attention = nn.Sequential( nn.AdaptiveAvgPool2d(1), nn.Conv2d(num_feat, num_feat // squeeze_factor, 1, padding=0), nn.ReLU(inplace=True), nn.Conv2d(num_feat // squeeze_factor, num_feat, 1, padding=0), nn.Sigmoid()) def forward(self, x): y = self.attention(x) return x * y class CAB(nn.Module): def __init__(self, num_feat, compress_ratio=3, squeeze_factor=30): super(CAB, self).__init__() self.cab = nn.Sequential( nn.Conv2d(num_feat, num_feat // compress_ratio, 3, 1, 1), nn.GELU(), nn.Conv2d(num_feat // compress_ratio, num_feat, 3, 1, 1), ChannelAttention(num_feat, squeeze_factor) ) def forward(self, x): return self.cab(x) -
在每一个RHAG的最后引入一个Overlapping Cross-Attention Block (OCAB),直接建立跨窗口的连接,同时增强窗口自注意力的表达能力。实现方式仍是基于W-MSA,只是在窗口划分时,Q的窗口是正常的无overlap的窗口,窗口大小为M * M,而K和V的窗口大小是M0 * M0, M0 =(1+gamma) * M, gamma是用于控制重叠大小的参数。虽然窗口的大小不一样,但是窗口的数量是相同的,一一对应的。
Q shape: (nums_of_windows, M*M, emb_dims) K shape: (nums_of_windows, M0*M0, emb_dims) V shape: (nums_of_windows, M0*M0, emb_dims) QK.T shape: (nums_of_windows, M*M, M0*M0) 因此得到的结果仍是 (nums_of_windows, M*M, emb_dims),但其过程中获取了跨窗口的信息,因为OCA的key和value是从更大的区域中计算得到的,因此更多有用的信息将被query查询到;-
预训练
使用Imagenet进行X4预训练,再在DF2K上进行finetune, 发现很有效,预训练的效果取决于数据的量级和多样性;同时,作者指出充分的iteration和合适的小学习率对于预训练来说非常重要;
-

















 6448
6448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









