






本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊 | 接辅导、项目定制
🚀 文章来源:K同学的学习圈子
1.densenet模型介绍
今天我们要介绍的是DenseNet模型,它的基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(denseconnection),它的名称也是由此而来。DenseNet的另一大特色是通过特征在channel上的连接来实现特征重用(feature reuse)。这些特点让DenseNet在参数和计算成本更少的情形下实现比esNet更优的性能,DenseNet也因此斩获CVPR 2017的最佳论文奖:
2.标准的神经网络传播,resnet,densenet网络对比
标准神经网络
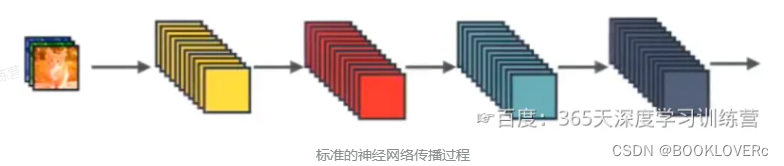
输入和输出的公式是 Xl= H(Xl-1),其中 H是一个组合函数,通常包括 BN、ReLU、Pooling、Conv操作, Xl-1 是第l层输入的特征图, Xl是第l层输出的特征图。
resnet
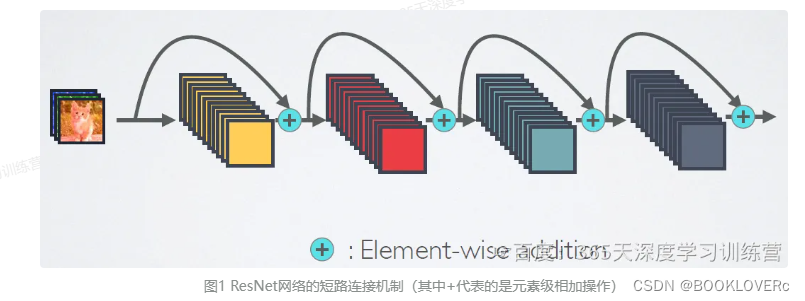
ResNet是跨层相加,输入和输出的公式是X=H(Xl-1)+ X1-1
Desnet
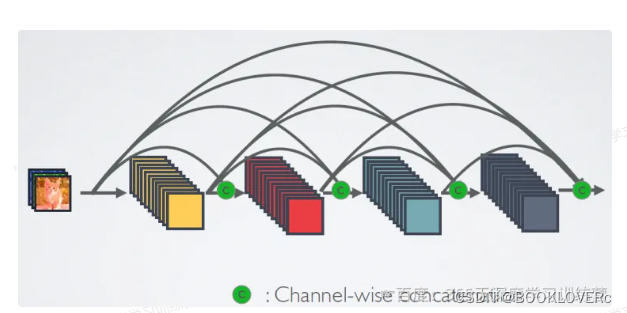
而对于DesNet,则是采用跨通道concat的形式来连接,会连接前面所有层作为输入,输入和输出的公式是 X= H(Xo,X1,…,Xl-1)。这里要注意所有的层的输入都来源于前面所有层在channel维度的concat
3.网络结构
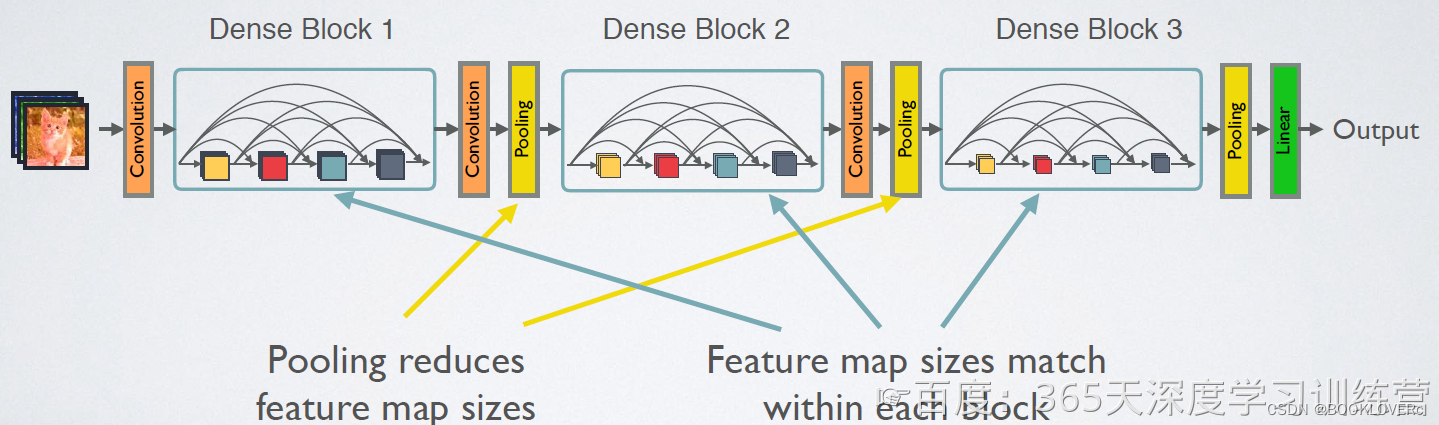
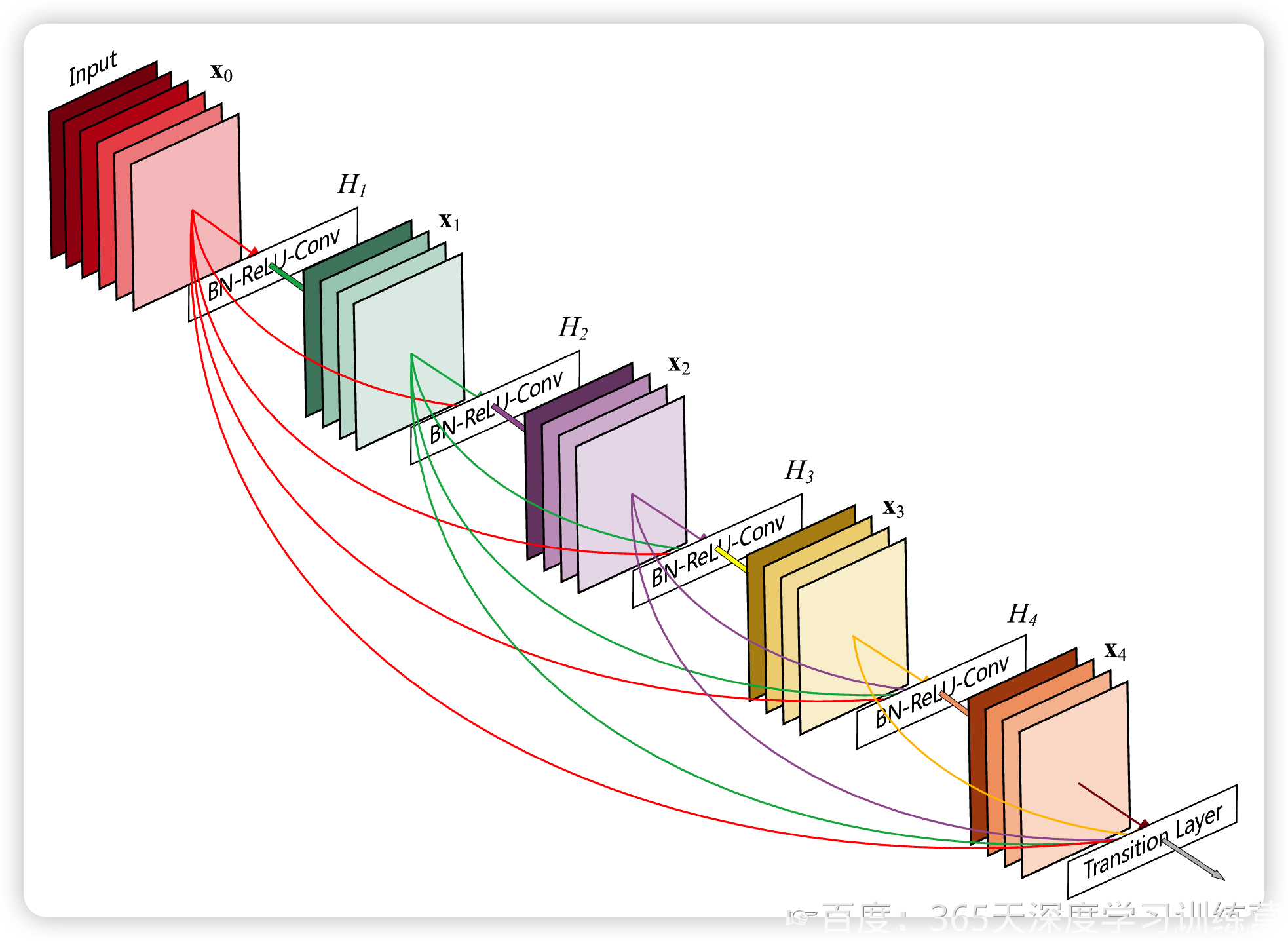
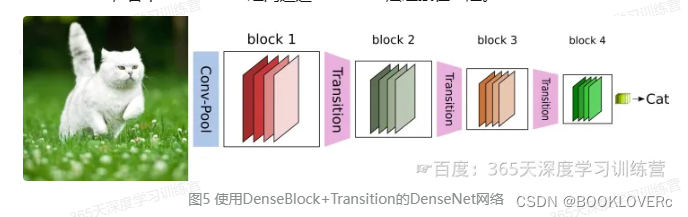
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小,而DenseNet的密集连接方式需要特征图大小保持一致。为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition层是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图5给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition层连接在一起。
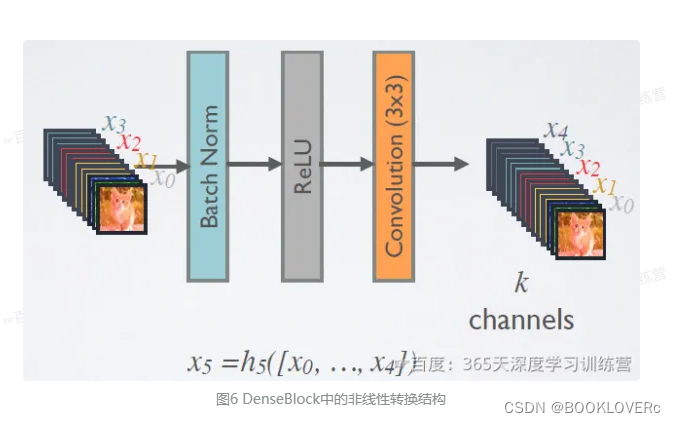
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H(·)的是 BN+ReLU+3x3Conv 的结构,如图6所示另外值得注意的一点是,与ResNet不同,所有DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,或者说采用个卷积核。k在DenseNet称为growthrate,这是一个超参数。一般情况下使用较小的k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 ko,那么l层输入的channel数为ko + k(1,2,l-1),因此随着层数增加,尽管 k 设定得较小,DenseBlock的输入会非常多,不过这是由于特征重用所造成的,每个层仅有 k个特征是自己独有的。
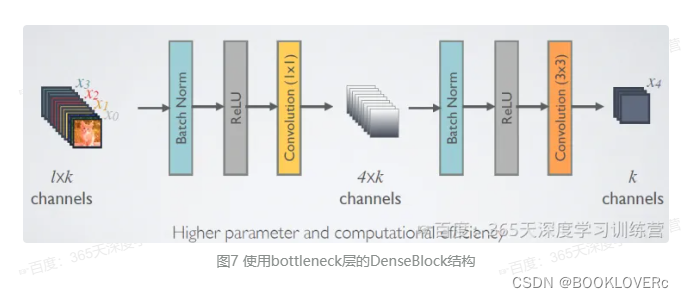
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量主要是原有的结构中增加1x1Conv,如图7所示,即BN+ReLU+1x1ConV+BN+ReLU+3x3Conv,称为DenseNet-B结构。其中1x1Conv得到 4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1Conv+2x2AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition层的上接DenseBlock得到的特征图channels数为 m,Transition层可以产生|0m|个特征(通过卷积层),其中theta(0,1]是压缩系数(compressionrate)。当 theta=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用theta=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
对于lmageNet数据集,图片输入大小为224x224,网络结构采用包含4个DenseBlock的DenseNet-BC,其首先是一个stride=2的7x7卷积层,然后是一个stride=2的3x3 MaxPooling层,后面才进入DenseBlock。lmageNet数据集所采用的网络配置如表1所示:

4.pytorch代码实现
导入数据,处理图片
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
data_dir = "./data_j1/第8天/bird_photos"##数据集目录名称
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[3] for path in data_paths]
print(classeNames)train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]
)
])total_data = datasets.ImageFolder("./data_j1/第8天/bird_photos",transform = train_transforms)
print(total_data)划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset)
print(test_dataset)
batch_size = 8
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
#num_workers=1
)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
#num_workers=1
)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break构造模型
import torch
import torch.nn as nn
import torch.nn.functional as F
class _DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, efficient=False):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate,
kernel_size=1, stride=1, bias=False)),
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module('relu2', nn.ReLU(inplace=True)),
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)),
self.drop_rate = drop_rate
self.efficient = efficient
def forward(self, *prev_features):
bn_function = _bn_function_factory(self.norm1, self.relu1, self.conv1)
if self.efficient and any(prev_feature.requires_grad for prev_feature in prev_features):
bottleneck_output = cp.checkpoint(bn_function, *prev_features)
else:
bottleneck_output = bn_function(*prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_featuresnum_input_features:输入特征的数量。growth_rate:密集块内部每个密集层输出的特征图数量。bn_size:瓶颈层中 1x1 卷积核的扩展系数。drop_rate:Dropout 正则化的比率。
通过代码理解网络结构
def forward(self, x)::forward 方法定义了数据在模型中前向传播的流程。
output = self.bn1(x):输入特征进行批量标准化。output = self.relu1(output):ReLU 激活函数。output = self.conv1(output):进行 1x1 卷积。output = self.bn2(output):通过瓶颈层的批量标准化。output = self.relu2(output):ReLU 激活函数。output = self.conv2(output):进行 3x3 卷积。if self.drop_rate > 0::如果drop_rate大于 0。output = F.dropout(output, p=self.drop_rate):应用 Dropout 正则化。
return torch.cat([x, output], 1):将原始输入 x 和当前层的输出 output 连接起来,这是 DenseNet 中密集连接的核心。密集连接将当前层的输出与之前所有层的输出连接在一起,而不是像传统的网络那样只与前一层连接。连接的方式是通过拼接在通道维度上进行的。这种连接有助于梯度流动,减轻了梯度消失问题,并且有助于信息传递。
class _DenseBlock(nn.Module):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, efficient=False):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
efficient=efficient,
)
self.add_module('denselayer%d' % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.named_children():
new_features = layer(*features)
features.append(new_features)
return torch.cat(features, 1)num_layers:密集块中密集层的数量。num_input_features:输入特征的数量。bn_size:瓶颈层中 1x1 卷积核的扩展系数。growth_rate:每个密集层输出的特征图数量。drop_rate:Dropout 正则化的比率。
if i == 0::如果是第一层,创建一个nn.Sequential对象self.layer,其中包含一个密集层。else::如果不是第一层,创建一个单独的密集层对象,并将其添加到self.layer中。
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 3 or 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
small_inputs (bool) - set to True if images are 32x32. Otherwise assumes images are larger.
efficient (bool) - set to True to use checkpointing. Much more memory efficient, but slower.
"""
def __init__(self, growth_rate=12, block_config=(16, 16, 16), compression=0.5,
num_init_features=24, bn_size=4, drop_rate=0,
num_classes=10, small_inputs=True, efficient=False):
super(DenseNet, self).__init__()
assert 0 < compression <= 1, 'compression of densenet should be between 0 and 1'
# First convolution
if small_inputs:
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=3, stride=1, padding=1, bias=False)),
]))
else:
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
]))
self.features.add_module('norm0', nn.BatchNorm2d(num_init_features))
self.features.add_module('relu0', nn.ReLU(inplace=True))
self.features.add_module('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1,
ceil_mode=False))
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
efficient=efficient,
)
self.features.add_module('denseblock%d' % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features,
num_output_features=int(num_features * compression))
self.features.add_module('transition%d' % (i + 1), trans)
num_features = int(num_features * compression)
# Final batch norm
self.features.add_module('norm_final', nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Initialization
for name, param in self.named_parameters():
if 'conv' in name and 'weight' in name:
n = param.size(0) * param.size(2) * param.size(3)
param.data.normal_().mul_(math.sqrt(2. / n))
elif 'norm' in name and 'weight' in name:
param.data.fill_(1)
elif 'norm' in name and 'bias' in name:
param.data.fill_(0)
elif 'classifier' in name and 'bias' in name:
param.data.fill_(0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return outimport math
model = DenseNet(growth_rate=32, block_config=(2, 2, 4, 4), compression=0.5,
num_init_features=64, bn_size=4, drop_rate=0.5,
num_classes=10, small_inputs=True, efficient=False)
model.to(device)DenseNet(
(features): Sequential(
(conv0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(denseblock1): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition1): _Transition(
(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock2): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition2): _Transition(
(norm): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(128, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock3): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): _DenseLayer(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): _DenseLayer(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(transition3): _Transition(
(norm): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1), bias=False)
(pool): AvgPool2d(kernel_size=2, stride=2, padding=0)
)
(denseblock4): _DenseBlock(
(denselayer1): _DenseLayer(
(norm1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer2): _DenseLayer(
(norm1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer3): _DenseLayer(
(norm1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(denselayer4): _DenseLayer(
(norm1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(norm2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
(norm_final): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(classifier): Linear(in_features=224, out_features=10, bias=True)
)训练函数和测试函数
def train(dataloader,model,optimizer,loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_acc,train_loss = 0,0
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model(X)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_acc,train_loss
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_lossloss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-2
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
import copy
epochs = 10
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
best_acc = 0def _bn_function_factory(norm, relu, conv):
def bn_function(*inputs):
concated_features = torch.cat(inputs, 1)
bottleneck_output = conv(relu(norm(concated_features)))
return bottleneck_output
return bn_function
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss = train(train_dl,model,opt,loss_fn)
model.eval()
epoch_test_acc,epoch_test_loss = test(test_dl,model,loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = opt.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
print('Done')Epoch: 1, Train_acc:40.0%, Train_loss:1.703, Test_acc:55.8%, Test_loss:1.455, Lr:1.00E-02
Epoch: 2, Train_acc:53.3%, Train_loss:1.319, Test_acc:57.5%, Test_loss:1.290, Lr:1.00E-02
Epoch: 3, Train_acc:55.1%, Train_loss:1.201, Test_acc:60.2%, Test_loss:1.206, Lr:1.00E-02
Epoch: 4, Train_acc:58.6%, Train_loss:1.132, Test_acc:61.1%, Test_loss:1.131, Lr:1.00E-02
Epoch: 5, Train_acc:64.6%, Train_loss:1.072, Test_acc:60.2%, Test_loss:1.026, Lr:1.00E-02
Epoch: 6, Train_acc:65.3%, Train_loss:1.010, Test_acc:64.6%, Test_loss:1.001, Lr:1.00E-02
Epoch: 7, Train_acc:65.0%, Train_loss:0.968, Test_acc:63.7%, Test_loss:1.018, Lr:1.00E-02
Epoch: 8, Train_acc:62.6%, Train_loss:0.965, Test_acc:65.5%, Test_loss:0.967, Lr:1.00E-02
Epoch: 9, Train_acc:63.7%, Train_loss:0.952, Test_acc:61.9%, Test_loss:0.955, Lr:1.00E-02
Epoch:10, Train_acc:66.4%, Train_loss:0.920, Test_acc:71.7%, Test_loss:0.886, Lr:1.00E-02
Doneimport matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc[-10:], label='Training Accuracy')
plt.plot(epochs_range, test_acc[-10:], label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss[-10:], label='Training Loss')
plt.plot(epochs_range, test_loss[-10:], label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()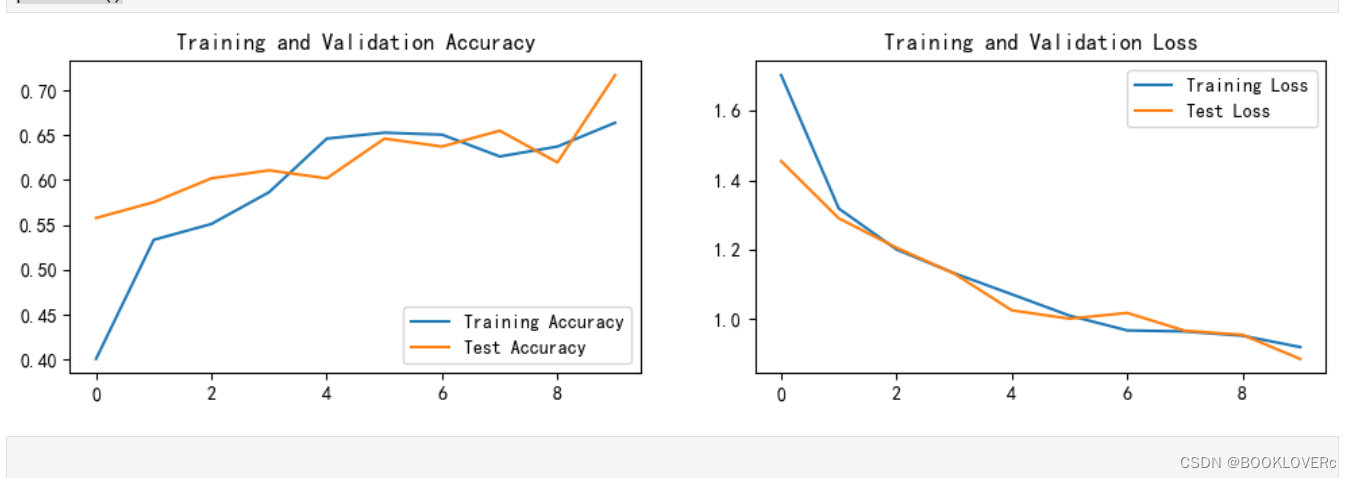
5.DenseNet结构的关键组成部分总结
初始卷积层:网络通常以一个标准的卷积层开始,用于初步提取输入图像的特征,并可能伴随有池化层来缩小输入尺寸。
Dense Blocks(密集块):DenseNet的主要构建模块。每个密集块内,每新增一个层,都会将其输出特征图与之前所有层的输出特征图进行拼接(concatenation),作为下一个层的输入。这保证了信息流的高效传递和特征的复用。为了控制模型复杂度,每个层通过较小的增长率(growth rate)来增加特征图的数量,即每个层产生的新特征图数量。
Bottleneck Layers(瓶颈层):为了减少计算成本,实际应用中的DenseNet常采用Bottleneck层设计。这些层首先使用1x1卷积来减少输入特征图的数量,然后是BN(Batch Normalization)和ReLU激活函数,接着是3x3卷积来提取特征。这样的设计保持了模型的效率,同时维持了特征的丰富性。
Transition Layers(过渡层):位于Dense Blocks之间,用于过渡并控制模型的复杂度。过渡层通常包含1x1的卷积用于压缩特征图的通道数(使用压缩因子θ),以及可选的平均池化(Average Pooling)来进一步减小空间尺寸,帮助减少计算负担和过拟合风险。
分类层:网络的尾部通常包括全局平均池化(Global Average Pooling)层,用于将每个特征图的 spatial 维度压缩为一个值,随后连接一个或多个全连接层用于最终的分类或回归任务。
DenseNet通过其独特的密集连接机制,不仅增强了特征传播,还允许特征的多尺度融合,提高了模型的性能和训练效率。
6.改写成tensflow中的网络结构
class DenseLayer(Model):
def __init__(self,bottleneck_size,growth_rate):
super().__init__()
self.filters=growth_rate
self.bottleneck_size=bottleneck_size
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.c1=Conv2D(filters=self.bottleneck_size,kernel_size=(1,1),strides=1)
self.b2=BatchNormalization()
self.a2=Activation('relu')
self.c2=Conv2D(filters=32,kernel_size=(3,3),strides=1,padding='same')
def call(self,*x):
x=tf.concat(x,2)
x=self.b1(x)
x=self.a1(x)
x=self.c1(x)
x=self.b2(x)
x=self.a2(x)
y=self.c2(x)
return yclass DenseBlock(Model):
def __init__(self,Dense_layers_num,growth_rate):#Dense_layers_num每个denseblock中的denselayer数,growth
super().__init__()
self.Dense_layers_num=Dense_layers_num
self.Dense_layers=[]
bottleneck_size=4*growth_rate
for i in range(Dense_layers_num):
layer=DenseLayer(bottleneck_size,growth_rate)
self.Dense_layers.append(layer)
def call(self,input):
x=[input]
for layer in self.Dense_layers:
output=layer(*x)
x.append(output)
y=tf.concat(x,2)
return yclass Transition(Model):
def __init__(self,filters):
super().__init__()
self.b=BatchNormalization()
self.a=Activation('relu')
self.c=Conv2D(filters=filters,kernel_size=(1,1),strides=1)
self.p=AveragePooling2D(pool_size=(2,2),strides=2)
def call(self,x):
x=self.b(x)
x=self.a(x)
x=self.c(x)
y=self.p(x)
return y class DenseNet(Model):
def __init__(self,block_list=[6,12,24,16],compression_rate=0.5,filters=64):
super().__init__()
growth_rate=32
self.padding=ZeroPadding2D(((1,2),(1,2)))
self.c1=Conv2D(filters=filters,kernel_size=(7,7),strides=2,padding='valid')
self.b1=BatchNormalization()
self.a1=Activation('relu')
self.p1=MaxPooling2D(pool_size=(3,3),strides=2,padding='same')
self.blocks=tf.keras.models.Sequential()
input_channel=filters
for i,layers_in_block in enumerate(block_list):
if i<3 :
self.blocks.add(DenseBlock(layers_in_block,growth_rate))
block_out_channels=input_channel+layers_in_block*growth_rate
self.blocks.add(Transition(filters=block_out_channels*0.5))
if i==3:
self.blocks.add(DenseBlock(Dense_layers_num=layers_in_block,growth_rate=growth_rate))
self.p2=GlobalAveragePooling2D()
self.d2=Dense(1000,activation='softmax')
def call(self,x):
x=self.padding(x)
x=self.c1(x)
x=self.b1(x)
x=self.a1(x)
x=self.p1(x)
x=self.blocks(x)
x=self.p2(x)
y=self.d2(x)
return y
model=DenseNet()
print(model)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









