






 本文介绍了如何将TensorFlow中的残差网络原理应用到PyTorch中,包括残差结构的原理、ResNet-50和bottleneck结构的实现,以及在实际项目中构建和训练ResNet50模型的过程。
本文介绍了如何将TensorFlow中的残差网络原理应用到PyTorch中,包括残差结构的原理、ResNet-50和bottleneck结构的实现,以及在实际项目中构建和训练ResNet50模型的过程。
本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊 | 接辅导、项目定制
🚀 文章来源:K同学的学习圈子
- 📌本周任务:📌
– 1.请根据本文TensorFlow代码,编写出相应的Pytorch代码
– 2.了解残差结构
– 3.是否可以将残差模块融入到C3当中(自由探索)
1.残差网络的由来
Resnet提出
深度残差网络ResNet(deep residual network)在2015年由何凯明等提出,因为它简单与实用并存,随后很多研究都是建立在ResNet-50或者ResNet-101基础上完成的。
ResNet主要解决深度卷积网络在深度加深时候的“退化”问题。 在一般的卷积神经网络中,增大网络深度后带来的第一个问题就是梯度消失、爆炸,这个问题在Szegedy提出BN后被顺利解决。BN层能对各层的输出做归一化,这样梯度在反向层层传递后仍能保持大小稳定,不会出现过小或过大的情况。
加入BN层会产生的问题
但是作者发现加了BN后,再加大深度仍然不容易收敛,其提到了第二个问题——准确率下降问题:层级大到一定程度时,准确率就会饱和,然后迅速下降。这种下降既不是梯度消失引起的,也不是过拟合造成的,而是由于网络过于复杂,以至于光靠不加约束的放养式的训练很难达到理想的错误率。
准确率下降问题不是网络结构本身的问题,而是现有的训练方式不够理想造成的。当前广泛使用的训练方法,无论是SGD,还是RMSProp,或是Adam,都无法在网络深度变大后达到理论上最优的收敛结果。
只要有理想的训练方式,更深的网络肯定会比较浅的网络效果要好。
证明过程:
假设在一种网络A的后面添加几层形成新的网络B,如果增加的层级只是对A的输出做了个恒等映射(identity mapping),即A的输出经过新增的层级变成B的输出后没有发生变化,这样网络A和网络B的错误率就是相等的,也就证明了加深后的网络不会比加深前的网络效果差。
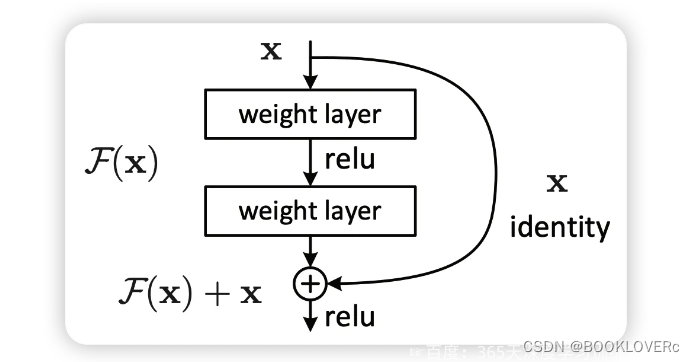
何凯明提出了一种残差结构来实现上述恒等映射(这行字上面这个图):整个模块除了正常的卷积层输出外,还有一个分支把输入直接连到输出上,该分支输出和卷积的输出做算数相加得到最终的输出,用公式表达就是 H ( x ) = F ( x ) + x ,x是输入,F(x)是卷积分支的输出,H ( x )是整个结构的输出。可以证明如果F(x)分支中所有参数都是0,H ( x ) 就是个恒等映射。
残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。如果一个网络通过简单的手工设置参数就能达到想要的结果,那这种结构就很容易通过训练来收敛到该结果,这是一条设计复杂的网络时通用的规则
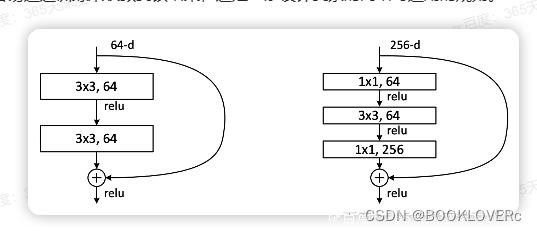
上图左边的单元为ResNet两层的残差单元,两层的残差单元包含两个相同输出的通道数的3x3卷积,只是用于较浅的ResNet网络,对较深的网络主要使用三层的残差单元。三层的残差单元又称为bottleneck结构,先用一个1x1卷积进行降维,然后3x3卷积,最后用1x1升维恢复原有的维度。另外,如果有输入输出维度不同的情况,可以对输入做一个线性映射变换维度,再连接后面的层,三层的残差单元对于相同数量的层又减少了参数量,因此可以拓展更深的模型,通过残差单元的组合有经典的ResNet-50,ResNet-101等网络结构。
2.pytorch代码实现
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib,warnings
warnings.filterwarnings("ignore") #忽略警告信息
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)train_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]
)
])
test_transforms = transforms.Compose([
transforms.Resize([224,224]),
transforms.ToTensor(),
transforms.Normalize(
mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225]
)
])total_data = datasets.ImageFolder("./data_j1/第8天/bird_photos",transform = train_transforms)
print(total_data)train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print(train_dataset)
print(test_dataset)
batch_size = 8
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
#num_workers=1
)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
#num_workers=1
)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break构造retnet50模型
from torch import nn
from torch.nn import functional as F
import torch.nn.functional as F
# 构造ResNet50模型
class ResNetblock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResNetblock, self).__init__()
self.blockconv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels * 4, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels * 4)
)
if stride != 1 or in_channels != out_channels * 4:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels * 4, kernel_size=1, stride=stride),
nn.BatchNorm2d(out_channels * 4)
)
def forward(self, x):
residual = x
out = self.blockconv(x)
if hasattr(self, 'shortcut'): # 如果self中含有shortcut属性
residual = self.shortcut(x)
out += residual
out = F.relu(out)
return out
class ResNet50(nn.Module):
def __init__(self, block, num_classes=1000):
super(ResNet50, self).__init__()
self.conv1 = nn.Sequential(
nn.ZeroPad2d(3),
nn.Conv2d(3, 64, kernel_size=7, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d((3, 3), stride=2)
)
self.in_channels = 64
# ResNet50中的四大层,每大层都是由ConvBlock与IdentityBlock堆叠而成
self.layer1 = self.make_layer(ResNetblock, 64, 3, stride=1)
self.layer2 = self.make_layer(ResNetblock, 128, 4, stride=2)
self.layer3 = self.make_layer(ResNetblock, 256, 6, stride=2)
self.layer4 = self.make_layer(ResNetblock, 512, 3, stride=2)
self.avgpool = nn.AvgPool2d((7, 7))
self.fc = nn.Linear(512 * 4, num_classes)
# 每个大层的定义函数
def make_layer(self, block, channels, num_blocks, stride=1):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_channels, channels, stride))
self.in_channels = channels * 4
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = out.view(out.size(0), -1)
out = self.fc(out)
return outmodel = ResNet50(block=ResNetblock, num_classes=len(classeNames)).to(device)
model定义训练函数和测试函数
def train(dataloader,model,optimizer,loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_acc,train_loss = 0,0
for X,y in dataloader:
X,y = X.to(device),y.to(device)
pred = model(X)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_acc,train_loss
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss相关参数
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-2
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
import copy
epochs = 50
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
best_acc = 0#开始训练
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss = train(train_dl,model,opt,loss_fn)
model.eval()
epoch_test_acc,epoch_test_loss = test(test_dl,model,loss_fn)
if epoch_test_acc > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
lr = opt.state_dict()['param_groups'][0]['lr']
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
print('Done')可视化残差曲线
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc[-50:], label='Training Accuracy')
plt.plot(epochs_range, test_acc[-50:], label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss[-50:], label='Training Loss')
plt.plot(epochs_range, test_loss[-50:], label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()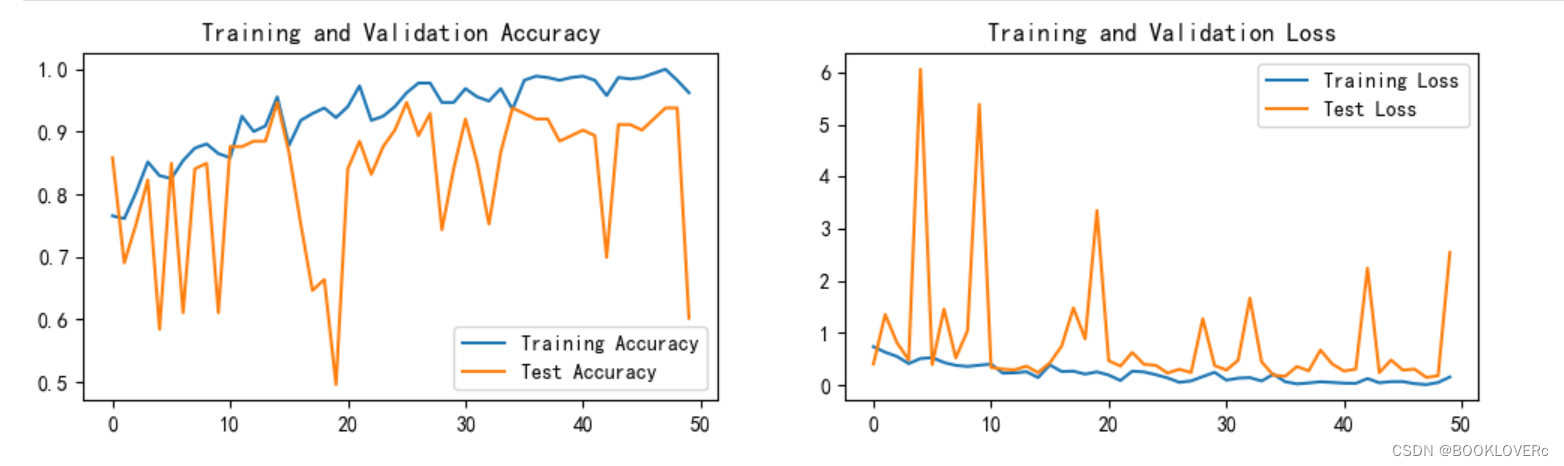
总结:
-
从最后的准确率和错误率来看,模型训练过程非常不稳定,图中的波动幅度较大。通过网络查询,可能有以下几个原因导致这种情况: (1) Batch size过小:一般来说,在一定范围内,Batch size越大,模型的下降方向越准确,训练震荡越小。常用的Batch size有16、32、64等。 (2) Epoch过小:Epoch和Batch size之间的关系为:完成一次Epoch需要的Batch个数=iterations=数据总数/ batch_size。
-
观察到深度网络的分类结果非常高,可以通过增加网络深度来提高网络的学习能力。此外,对残差网络也有一定的了解。















 7763
7763











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









