






本文为🔗365天深度学习训练营中的学习记录博客
🍖 原作者:K同学啊 | 接辅导、项目定制
🚀 文章来源:K同学的学习圈子
1.设置GPU
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
gpus
2.导入数据
import pandas as pd
import numpy as np
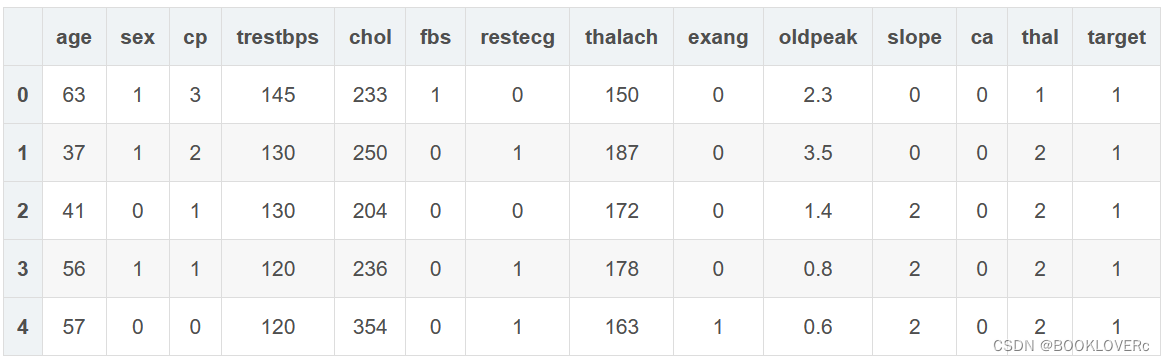
df = pd.read_csv("heart.csv")
df.head()
2.数据预处理
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1, random_state = 1)
X_train.shape, y_train.shape
# 将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
3.构建RNN模型
关键参数说明
● units: 正整数,输出空间的维度。
● activation: 要使用的激活函数。 默认:双曲正切(tanh)。 如果传入 None,则不使用激活函数 (即 线性激活:a(x) = x)。
● use_bias: 布尔值,该层是否使用偏置向量。
● kernel_initializer: kernel 权值矩阵的初始化器, 用于输入的线性转换 (详见 initializers)。
● recurrent_initializer: recurrent_kernel 权值矩阵 的初始化器,用于循环层状态的线性转换 (详见 initializers)。
● bias_initializer:偏置向量的初始化器 (详见initializers).
● dropout: 在 0 和 1 之间的浮点数。 单元的丢弃比例,用于输入的线性转换。
import tensorflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense,LSTM,SimpleRNN
model = Sequential()
model.add(SimpleRNN(200, input_shape= (13,1), activation='relu'))
model.add(Dense(100, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
4.编译和训练
opt = tf.keras.optimizers.Adam(learning_rate=1e-4)
model.compile(loss='binary_crossentropy',
optimizer=opt,
metrics="accuracy")
from tensorflow.keras.callbacks import ModelCheckpoint
#保存最佳模型参数
checkpointer=ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
save_weights_only=True
)
epochs = 100
history = model.fit(X_train, y_train,
epochs=epochs,
batch_size=128,
validation_data=(X_test, y_test),
verbose=1,
callbacks=[checkpointer])
5.模型评估
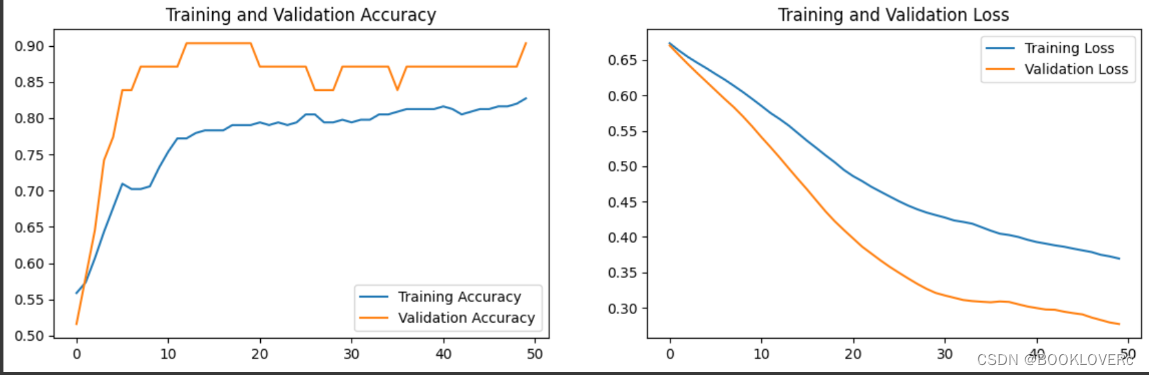
import matplotlib.pyplot as plt
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(14, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 加载效果最好的模型权重
model.load_weights('best_model.h5')
scores = model.evaluate(X_test, y_test, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
accuracy: 90.32%
6.总结
RNN构建过程:
输入1: [样本1的特征1]
[样本2的特征1]
[样本3的特征1]
...
[样本13的特征1]
输入2: [样本14的特征1]
[样本15的特征1]
[样本16的特征1]
...
[样本26的特征1]
输入3: [样本27的特征1]
[样本28的特征1]
[样本29的特征1]
...
[样本39的特征1]
…
直至270*13个特征全部输入完毕后输入过程结束
整个训练过程流程
训练数据 (train_data, train_labels)
↓
前向传播
↓
输入层 (Input Layer) SimpleRNN层 Dense层 Dense层
(输入数据的形状为 (13,1)) (200个神经元) (100个神经元) (1个神经元)
↓ ↓ ↓ ↓
──────────────▶ ─────────────▶ ───────────▶ ──────────▶
↓ ↓ ↓ ↓
↘ (包含权重) ↘ (包含权重) ↘ (包含权重) ↘ (包含权重)
计算损失
↓
反向传播
↓
优化器更新权重
↓
循环以上过程 (多次Epoch)















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









