






文章目录
高斯过程 Gaussian Processes
1.一元高斯分布
从最简单最常见的一元高斯分布开始,其概率密度函数为
p
(
x
)
=
1
σ
2
π
exp
[
−
(
x
−
μ
)
2
2
σ
2
]
(1)
p(x) = \frac 1 {\sigma \sqrt{2\pi}} \exp \left[ {-\frac {(x-\mu)^2}{2\sigma ^ 2}}\right] \tag1
p(x)=σ2π1exp[−2σ2(x−μ)2](1)
其中
μ
\mu
μ 和
σ
\sigma
σ 分别表示均值和方差,这个概率密度函数曲线画出来就是我们熟悉的钟形曲线,均值和方差唯一地决定了曲线的形状。
2.多元高斯分布
从一元高斯分布推广到多元高斯分布,假设各维度之间相互独立
p
(
x
1
,
x
2
,
…
,
x
n
)
=
∏
i
=
1
n
p
(
x
i
)
=
1
(
2
π
)
n
2
σ
1
σ
2
…
σ
n
exp
(
−
1
2
[
(
x
1
−
μ
1
)
2
σ
1
2
+
(
x
2
−
μ
2
)
2
σ
2
2
+
…
+
(
x
n
−
μ
n
)
2
σ
n
2
]
)
(2)
\begin{aligned} & p\left(x_1, x_2, \ldots, x_n\right)=\prod_{i=1}^n p\left(x_i\right) \\ & =\frac{1}{(2 \pi)^{\frac{n}{2}} \sigma_1 \sigma_2 \ldots \sigma_n} \exp \left(-\frac{1}{2}\left[\frac{\left(x_1-\mu_1\right)^2}{\sigma_1^2}+\frac{\left(x_2-\mu_2\right)^2}{\sigma_2^2}+\ldots+\frac{\left(x_n-\mu_n\right)^2}{\sigma_n^2}\right]\right) \end{aligned} \tag2
p(x1,x2,…,xn)=i=1∏np(xi)=(2π)2nσ1σ2…σn1exp(−21[σ12(x1−μ1)2+σ22(x2−μ2)2+…+σn2(xn−μn)2])(2)
其中
μ
1
,
μ
2
,
⋯
\mu_1, \mu_2, \cdots
μ1,μ2,⋯ 和
σ
1
,
σ
2
,
⋯
\sigma_1, \sigma_2, \cdots
σ1,σ2,⋯ 分别是第 1 维、第二维… 的均值和方差。对上式向量和矩阵表示上式,令
x
−
μ
=
[
x
1
−
μ
1
,
x
2
−
μ
2
,
…
x
n
−
μ
n
]
T
K
=
[
σ
1
2
0
⋯
0
0
σ
2
2
⋯
0
⋮
⋮
⋱
0
0
0
0
σ
n
2
]
\begin{gathered} \boldsymbol{x}-\boldsymbol{\mu}=\left[x_1-\mu_1, x_2-\mu_2, \ldots x_n-\mu_n\right]^T \\ K=\left[\begin{array}{cccc} \sigma_1^2 & 0 & \cdots & 0 \\ 0 & \sigma_2^2 & \cdots & 0 \\ \vdots & \vdots & \ddots & 0 \\ 0 & 0 & 0 & \sigma_n^2 \end{array}\right] \end{gathered} \nonumber
x−μ=[x1−μ1,x2−μ2,…xn−μn]TK=
σ120⋮00σ22⋮0⋯⋯⋱0000σn2
有
σ
1
σ
2
…
σ
n
=
∣
K
∣
1
2
(
x
1
−
μ
1
)
2
σ
1
2
+
(
x
2
−
μ
2
)
2
σ
2
2
+
…
+
(
x
n
−
μ
n
)
2
σ
n
2
=
(
x
−
μ
)
T
K
−
1
(
x
−
μ
)
\begin{gathered} \sigma_1 \sigma_2 \ldots \sigma_n=|K|^{\frac{1}{2}} \\ \frac{\left(x_1-\mu_1\right)^2}{\sigma_1^2}+\frac{\left(x_2-\mu_2\right)^2}{\sigma_2^2}+\ldots+\frac{\left(x_n-\mu_n\right)^2}{\sigma_n^2}=(\boldsymbol{x}-\boldsymbol{\mu})^T K^{-1}(\boldsymbol{x}-\boldsymbol{\mu}) \end{gathered} \nonumber
σ1σ2…σn=∣K∣21σ12(x1−μ1)2+σ22(x2−μ2)2+…+σn2(xn−μn)2=(x−μ)TK−1(x−μ)
代入到公式(2)得到
p
(
x
)
=
(
2
π
)
−
n
2
∣
K
∣
1
2
exp
(
−
1
2
(
x
−
μ
)
T
K
−
1
(
x
−
μ
)
)
(3)
p(x)=(2π)^{-{\frac {n}{2}}}|K|^\frac 1 2\exp \left( - \frac 1 2 \left(\boldsymbol{x}-\boldsymbol{\mu})^T K^{-1}(\boldsymbol{x}-\boldsymbol{\mu}\right)\right) \tag3
p(x)=(2π)−2n∣K∣21exp(−21(x−μ)TK−1(x−μ))(3)
其中
μ
∈
R
\boldsymbol{\mu} \in \R
μ∈R是均值向量,
K
∈
R
n
×
n
K\in \R^{n \times n}
K∈Rn×n 为协方差矩阵,由于假设了各维度直接相互独立,因此
K
K
K是一个对角矩阵。在各维度变量相关时,上式的形式仍然一致,但此时协方差矩阵
K
K
K不再是对角矩阵,只具备半正定和对称的性质。上式通常也简写为
x
∼
N
(
μ
,
K
)
x \sim \mathcal{N}\left(\boldsymbol{\mu},K\right) \nonumber
x∼N(μ,K)
3.无限元高斯分布?
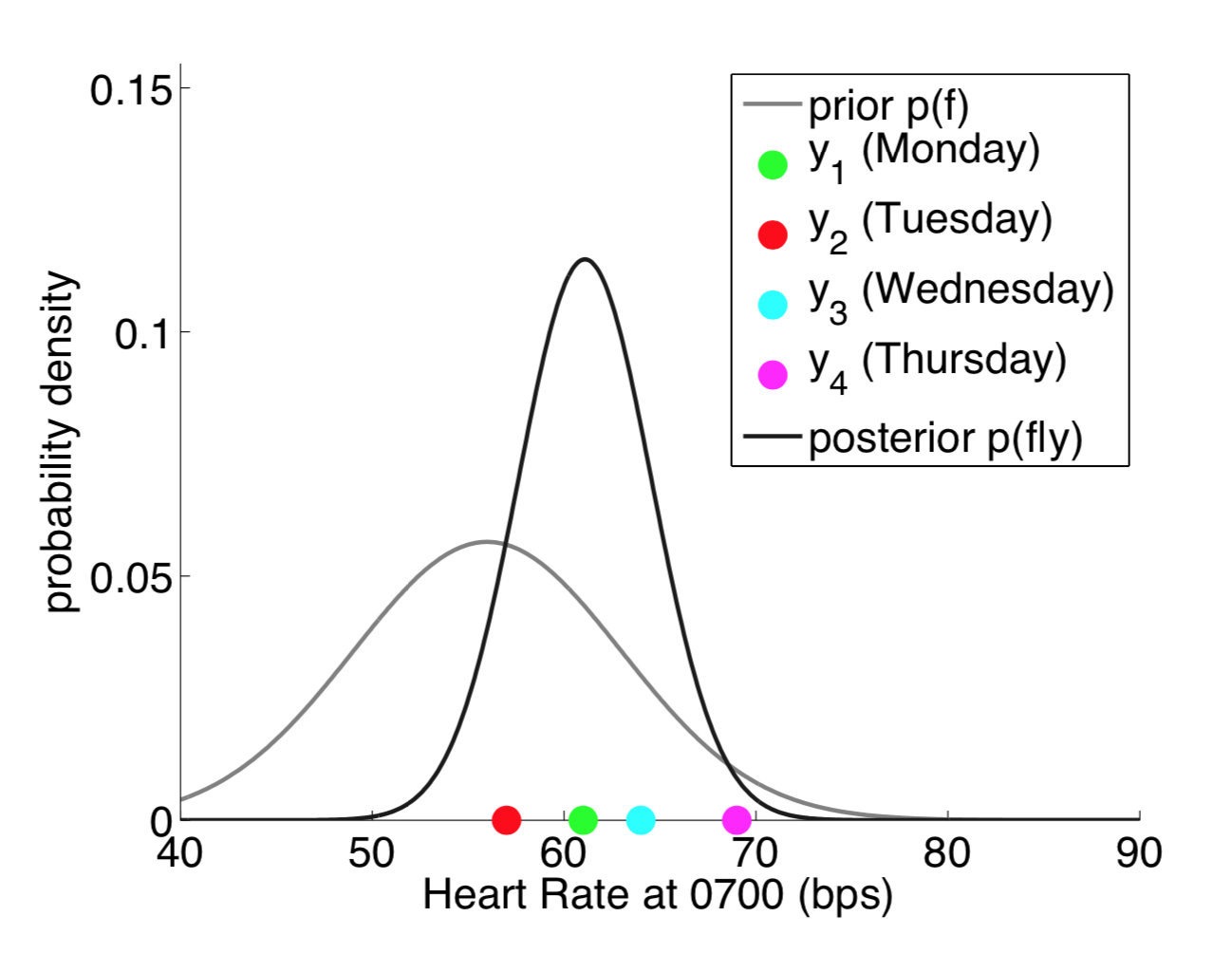
在多元高斯分布的基础上考虑进一步扩展,假设有无限多维呢?用一个例子来展示这个扩展的过程,假设在周一到周四每天的 7:00 测试了 4 次心率,如下图中 4 个点,可能的高斯分布如图所示(高瘦的那条)。这是一个一元高斯分布,只有每天 7: 00 的心率这个维度。
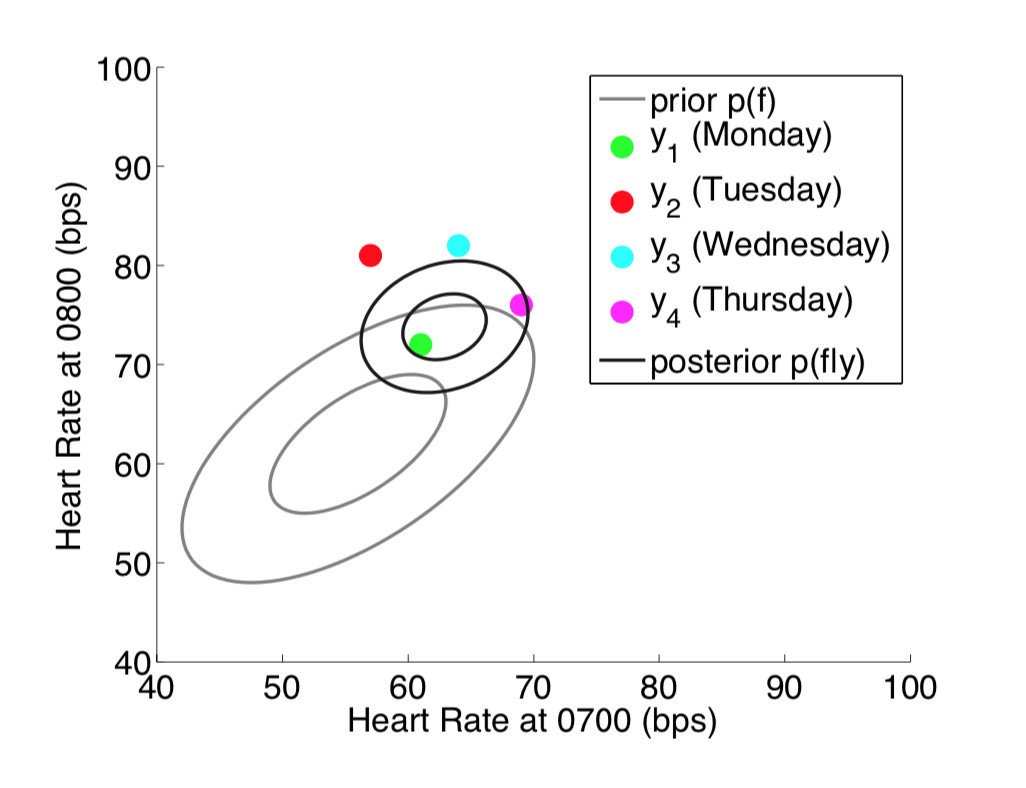
现在考虑不仅在每天的 7: 00 测心率(横轴),在 8:00 时也进行测量(纵轴),这个时候变成两个维度(二元高斯分布),如下图所示
更进一步,如果在每天的无数个时间点都进行测量,则变成了下图的情况。注意下图中把测量时间作为横轴,则每个颜色的一条线代表一个(无限个时间点的测量)无限维的采样。当对每次对无限维进行采样得到无限多个点时,其实可以理解为我们采样得到了一个函数。
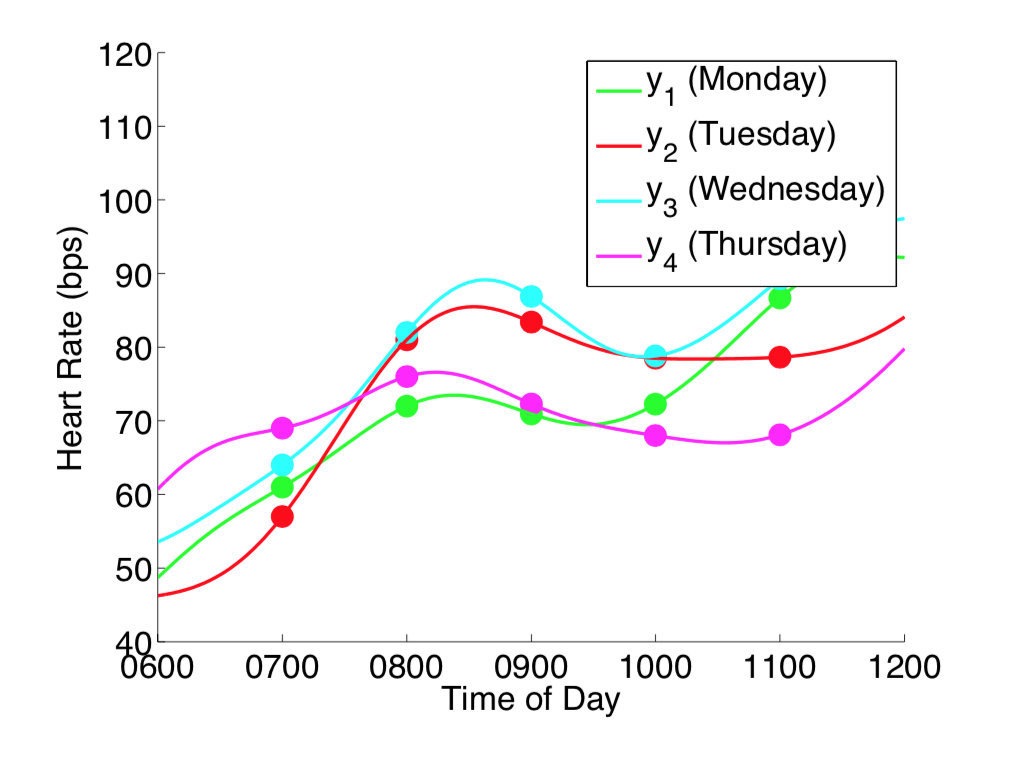
当从函数的视角去看待采样,理解了每次采样无限维相当于采样一个函数之后,原本的概率密度函数不再是点的分布 ,而变成了函数的分布。这个无限元高斯分布即称为高斯过程。高斯过程正式地定义为:对于所有
x
=
[
x
1
,
x
2
,
⋯
,
x
n
]
,
f
(
f
(
x
1
)
,
f
(
x
2
)
,
⋯
,
f
(
x
n
)
)
\boldsymbol{x}=\left[x_1,x_2,\cdots,x_n \right],f\left(f(x_1),f(x_2),\cdots, f(x_n)\right)
x=[x1,x2,⋯,xn],f(f(x1),f(x2),⋯,f(xn))都服从多元高斯分布,则称
f
f
f 是一个高斯过程,表示为
f
(
x
)
∼
N
(
μ
(
x
)
,
κ
(
x
,
x
)
)
f(x)\sim\mathcal{N}(\boldsymbol{\mu}(x),\kappa(\boldsymbol x,\boldsymbol x)) \nonumber
f(x)∼N(μ(x),κ(x,x))
这里
μ
(
x
)
:
R
n
→
R
n
\boldsymbol{\mu}(x):\R^n \rightarrow \R^n
μ(x):Rn→Rn 表示均值函数(Mean function),返回各个维度的均值;
κ
(
x
,
x
)
:
R
n
×
n
→
R
n
×
n
\kappa(\boldsymbol x,\boldsymbol x):\R^{n \times n} \rightarrow \R^{n \times n}
κ(x,x):Rn×n→Rn×n为协方差函数 Covariance Function(也叫核函数 Kernel Function)返回两个向量各个维度之间的协方差矩阵。一个高斯过程为一个均值函数和协方差函数唯一地定义,并且一个高斯过程的有限维度的子集都服从一个多元高斯分布(为了方便理解,可以想象二元高斯分布两个维度各自都服从一个高斯分布)
4.核函数(协方差函数)
核函数是一个高斯过程的核心,核函数决定了一个高斯过程的性质。核函数在高斯过程中起生成一个协方差矩阵(相关系数矩阵)来衡量任意两个点之间的“距离”。不同的核函数有不同的衡量方法,得到的高斯过程的性质也不一样。最常用的一个核函数为高斯核函数,也成为径向基函数 RBF。其基本形式如下。其中
σ
\sigma
σ 和
l
l
l 是高斯核的超参数
K
(
x
i
,
x
j
)
=
σ
2
exp
(
−
∣
∣
x
i
−
x
j
∣
∣
2
2
2
l
2
)
K(x_i,x_j)=\sigma^2\exp\left( -\frac{||x_i-x_j||_2^2}{2l^2} \right) \nonumber
K(xi,xj)=σ2exp(−2l2∣∣xi−xj∣∣22)
高斯核函数的 python 实现如下
import numpy as np
def gaussian_kernel(x1, x2, l=1.0, sigma_f=1.0):
"""Easy to understand but inefficient."""
m, n = x1.shape[0], x2.shape[0]
dist_matrix = np.zeros((m, n), dtype=float)
for i in range(m):
for j in range(n):
dist_matrix[i][j] = np.sum((x1[i] - x2[j]) ** 2)
return sigma_f ** 2 * np.exp(- 0.5 / l ** 2 * dist_matrix)
def gaussian_kernel_vectorization(x1, x2, l=1.0, sigma_f=1.0):
"""More efficient approach."""
dist_matrix = np.sum(x1**2, 1).reshape(-1, 1) + np.sum(x2**2, 1) - 2 * np.dot(x1, x2.T)
return sigma_f ** 2 * np.exp(-0.5 / l ** 2 * dist_matrix)
x = np.array([700, 800, 1029]).reshape(-1, 1)
print(gaussian_kernel_vectorization(x, x, l=500, sigma=10))
输出的向量
x
x
x 与自身的协方差矩阵为
[[100.
\quad\,\,\,
98.02
\quad
80.53]
\,
[98.02
\quad
100.
\quad\,\,\,\,\,
90.04]
\,
[80.53
\quad
90.04
\quad\,\,
100.]]
5.高斯过程可视化
下图是高斯过程的可视化,其中蓝线是高斯过程的均值,浅蓝色区域 95% 置信区间(由协方差矩阵的对角线得到),每条虚线代表一个函数采样(这里用了 100 维模拟连续无限维)。左上角第一幅图是高斯过程的先验(这里用了零均值作为先验),后面几幅图展示了当观测到新的数据点的时候,高斯过程如何更新自身的均值函数和协方差函数。
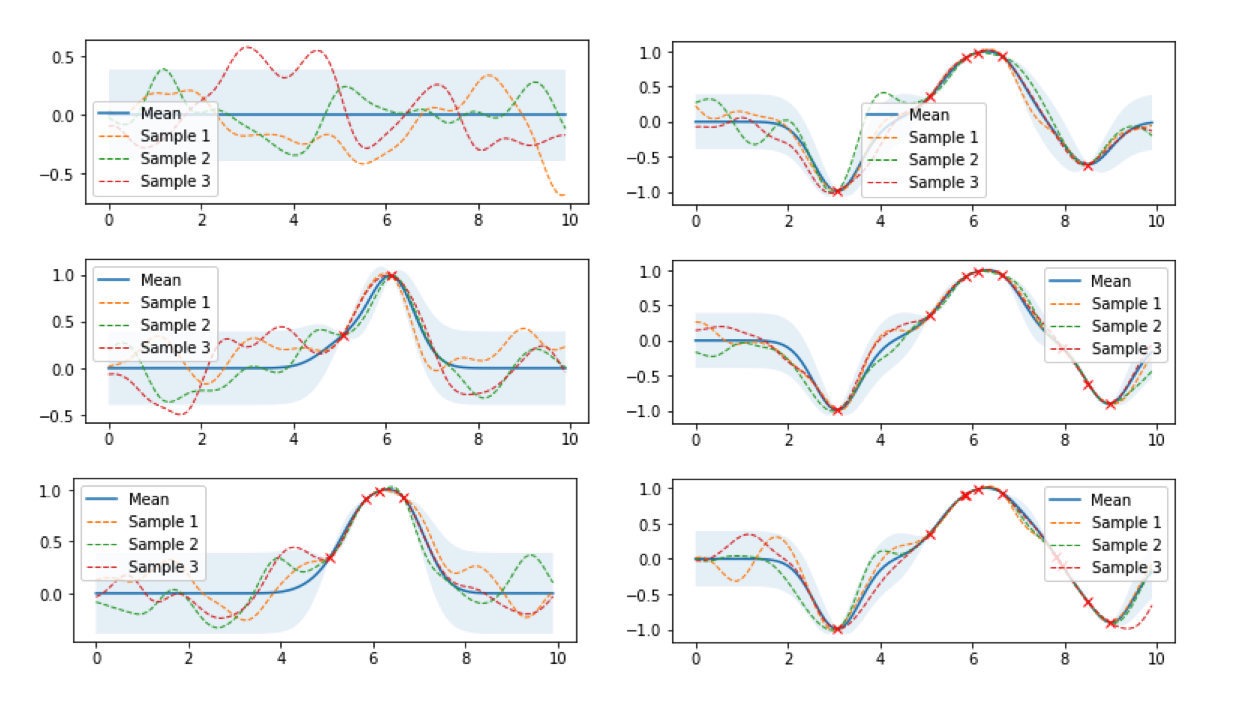
接下来用公式推导上图的过程。将高斯过程的先验表示为
σ
\sigma
σ
f
(
x
)
∼
N
(
μ
f
,
K
f
f
)
f(\boldsymbol x)\sim\mathcal{N}(\boldsymbol{\mu}_f,K_{ff})
f(x)∼N(μf,Kff),对应左上角第一幅图,如果现在观测到一些数据
(
x
∗
,
y
∗
)
(\boldsymbol{x^*,y^*})
(x∗,y∗),并且假设
y
∗
\boldsymbol{y^*}
y∗与
f
(
x
)
f(\boldsymbol x)
f(x)服从联合高斯分布
[
f
(
x
)
y
∗
]
∼
N
(
[
μ
f
μ
y
]
,
[
K
f
f
K
f
y
K
f
y
T
K
y
y
]
)
\left[\begin{array}{c} f(\boldsymbol{x}) \\ \boldsymbol{y}^* \end{array}\right] \sim \mathcal{N}\left(\left[\begin{array}{l} \boldsymbol{\mu}_f \\ \boldsymbol{\mu}_{\boldsymbol{y}} \end{array}\right],\left[\begin{array}{ll} K_{f f} & K_{f y} \\ K_{f y}^T & K_{y y} \end{array}\right]\right) \nonumber
[f(x)y∗]∼N([μfμy],[KffKfyTKfyKyy])
其中
K
f
f
=
κ
(
x
,
x
)
,
K
f
y
=
κ
(
x
,
x
∗
)
,
K
y
y
=
κ
(
x
∗
,
x
∗
)
K_{f f}=\kappa(\boldsymbol{x}, \boldsymbol{x}), \quad K_{f y}=\kappa\left(\boldsymbol{x}, \boldsymbol{x}^*\right), \quad K_{y y}=\kappa\left(\boldsymbol{x}^*, \boldsymbol{x}^*\right)
Kff=κ(x,x),Kfy=κ(x,x∗),Kyy=κ(x∗,x∗), 则有
f
∼
N
(
K
f
y
T
K
f
f
−
1
y
+
μ
f
,
K
y
y
−
K
f
y
T
K
f
f
−
1
K
f
y
)
f \sim \mathcal{N}\left(K_{f y}^T K_{f f}^{-1} \boldsymbol{y}+\boldsymbol{\mu}_f, K_{y y}-K_{f y}^T K_{f f}^{-1} K_{f y}\right) \nonumber
f∼N(KfyTKff−1y+μf,Kyy−KfyTKff−1Kfy)
上述式子表明了给定数据
(
x
∗
,
y
∗
)
\left(\boldsymbol{x}^*, \boldsymbol{y}^*\right)
(x∗,y∗) 之后函数的分布
f
f
f 仍然是一个高斯过程, 具体的推导可见 Gaussian Processes for Machine Learning。这个式子可以看出一些有趣的性 质, 均值
K
f
y
T
K
f
f
−
1
y
+
μ
f
K_{f y}^T K_{f f}^{-1} \boldsymbol{y}+\boldsymbol{\mu}_f
KfyTKff−1y+μf 实际上是观测点
y
\boldsymbol{y}
y 的一个线性函数, 协方差项
K
y
y
−
K
f
y
T
K
f
f
−
1
K
f
y
K_{y y}-K_{f y}^T K_{f f}^{-1} K_{f y}
Kyy−KfyTKff−1Kfy 的第一部分是先验的协方差, 减掉的后面的那一项实际上表示了观测到数据后函数分布不确定性的减少, 如果第二项非常接近于 0 , 说明观测数据后不确定性几乎不变, 反之如果第二项非常大, 则说明不确定性降低了很多。
上式其实就是高斯过程回归的基本公式, 首先有一个高斯过程先验分布, 观测到一些数据(机器学习中的训练数据), 基于先验和一定的假设(联合高斯分布)计算得到高斯过程后验分布的均值和协方差。
6.简单高斯过程回归实现
考虑代码实现一个高斯过程回归,API 接口风格采用 sciki-learn fit-predict 风格。由于高斯过程回归是一种非参数化 (non-parametric)的模型,每次的 inference 都需要利用所有的训练数据进行计算得到结果,因此并没有一个显式的训练模型参数的过程,所以 fit 方法只需要将训练数据保存下来,实际的 inference 在 predict 方法中进行。Python 代码如下
from scipy.optimize import minimize
class GPR:
def __init__(self, optimize=True):
self.is_fit = False
self.train_X, self.train_y = None, None
self.params = {"l": 0.5, "sigma_f": 0.2}
self.optimize = optimize
def fit(self, X, y):
# store train data
self.train_X = np.asarray(X)
self.train_y = np.asarray(y)
self.is_fit = True
def predict(self, X):
if not self.is_fit:
print("GPR Model not fit yet.")
return
X = np.asarray(X)
Kff = self.kernel(self.train_X, self.train_X) # (N, N)
Kyy = self.kernel(X, X) # (k, k)
Kfy = self.kernel(self.train_X, X) # (N, k)
Kff_inv = np.linalg.inv(Kff + 1e-8 * np.eye(len(self.train_X))) # (N, N)
mu = Kfy.T.dot(Kff_inv).dot(self.train_y)
cov = Kyy - Kfy.T.dot(Kff_inv).dot(Kfy)
return mu, cov
def kernel(self, x1, x2):
dist_matrix = np.sum(x1**2, 1).reshape(-1, 1) + np.sum(x2**2, 1) - 2 * np.dot(x1, x2.T)
return self.params["sigma_f"] ** 2 * np.exp(-0.5 / self.params["l"] ** 2 * dist_matrix)
def y(x, noise_sigma=0.0):
x = np.asarray(x)
y = np.cos(x) + np.random.normal(0, noise_sigma, size=x.shape)
return y.tolist()
train_X = np.array([3, 1, 4, 5, 9]).reshape(-1, 1)
train_y = y(train_X, noise_sigma=1e-4)
test_X = np.arange(0, 10, 0.1).reshape(-1, 1)
gpr = GPR()
gpr.fit(train_X, train_y)
mu, cov = gpr.predict(test_X)
test_y = mu.ravel()
#均值 μ 标准差 σ 的正态分布落在 (μ-1.96σ, μ+1.96σ) 区间内的面积约占了 95%
uncertainty = 1.96 * np.sqrt(np.diag(cov))
plt.figure()
plt.title("l=%.2f sigma_f=%.2f" % (gpr.params["l"], gpr.params["sigma_f"]))
plt.fill_between(test_X.ravel(), test_y + uncertainty, test_y - uncertainty, alpha=0.1)
plt.plot(test_X, test_y, label="predict")
plt.scatter(train_X, train_y, label="train", c="red", marker="x")
plt.legend()
结果如下图,红点是训练数据,蓝线是预测值,浅蓝色区域是 95% 置信区间。真实的函数是一个 cosine 函数,可以看到在训练数据点较为密集的地方,模型预测的不确定性较低,而在训练数据点比较稀疏的区域,模型预测不确定性较高。
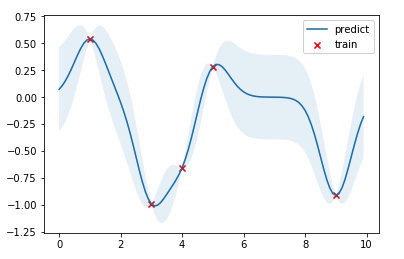
7.超参数优化
上文提到高斯过程是一种非参数模型,没有训练模型参数的过程,一旦核函数、训练数据给定,则模型就被唯一地确定下来。但是核函数本身是有参数的,比如高斯核的参数 μ \mu μ和 l l l ,这种参数称为模型的超参数(类似于 K − N N \rm K-\rm{NN} K−NN 模型中 k 的取值)。
核函数本质上决定了样本点相似性的度量方法,进行影响到了整个函数的概率分布的形状。上面的高斯过程回归的例子中使用了 μ = 0.2 , l = 0.5 \mu =0.2,l=0.5 μ=0.2,l=0.5的超参数,可以选取不同的超参数看看回归出来的效果。
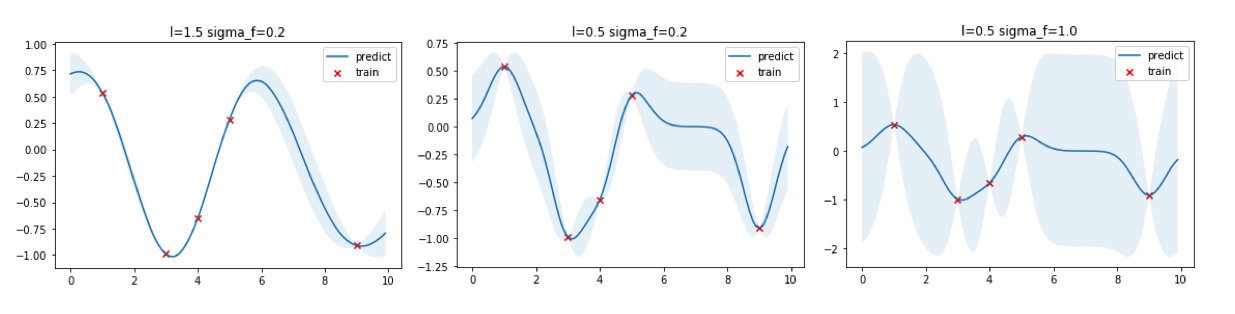
从上图可以看出, l l l越大函数更加平滑,同时训练数据点之间的预测方差更小,反之 l l l 越小则函数倾向于更加“曲折”,训练数据点之间的预测方差更大; σ \sigma σ 则直接控制方差大小, σ \sigma σ越大方差越大,反之亦然。
如何选择最优的核函数参数
σ
\sigma
σ和
l
l
l 呢?答案是最大化在这两个超参数下
y
\boldsymbol y
y 出现的概率,通过最大化边缘对数似然(Marginal Log-likelihood)来找到最优的参数,边缘对数似然表示为
log
p
(
y
∣
σ
,
l
)
=
log
N
(
0
,
K
y
y
(
σ
,
l
)
)
=
−
1
2
y
T
K
−
1
y
y
y
−
1
2
log
∣
K
y
y
∣
−
N
2
log
(
2
π
)
\begin{aligned} \log \, p\left( \boldsymbol y |\sigma,l\right) &=\log \,\mathcal N(\boldsymbol 0,K_{yy}\left(\sigma,l \right)) \\&=-\frac 1 2 \boldsymbol y ^T K_{-1}^{yy}\boldsymbol{y}-\frac 1 2\log \, |K_{yy}|-\frac N 2\log \,(2π) \end{aligned} \nonumber
logp(y∣σ,l)=logN(0,Kyy(σ,l))=−21yTK−1yyy−21log∣Kyy∣−2Nlog(2π)
具体的实现中,在 fit 方法中增加超参数优化这部分的代码,最小化负边缘对数似然。
from scipy.optimize import minimize
class GPR:
def __init__(self, optimize=True):
self.is_fit = False
self.train_X, self.train_y = None, None
self.params = {"l": 0.5, "sigma_f": 0.2}
self.optimize = optimize
def fit(self, X, y):
# store train data
self.train_X = np.asarray(X)
self.train_y = np.asarray(y)
# hyper parameters optimization
def negative_log_likelihood_loss(params):
self.params["l"], self.params["sigma_f"] = params[0], params[1]
Kyy = self.kernel(self.train_X, self.train_X) + 1e-8 * np.eye(len(self.train_X))
loss = 0.5 * self.train_y.T.dot(np.linalg.inv(Kyy)).dot(self.train_y) + 0.5 * np.linalg.slogdet(Kyy)[1] + 0.5 * len(self.train_X) * np.log(2 * np.pi)
return loss.ravel()
if self.optimize:
res = minimize(negative_log_likelihood_loss, [self.params["l"], self.params["sigma_f"]],
bounds=((1e-4, 1e4), (1e-4, 1e4)),
method='L-BFGS-B')
self.params["l"], self.params["sigma_f"] = res.x[0], res.x[1]
self.is_fit = True
将训练、优化得到的超参数、预测结果可视化如下图,可以看到最优的 l = 1.2 , σ f = 0.8 l=1.2,\sigma_f=0.8 l=1.2,σf=0.8
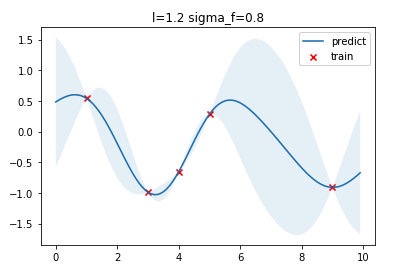
这里用 scikit-learn 的 [GaussianProcessRegressor] 接口进行对比
from sklearn.gaussian_process import GaussianProcessRegressor
from sklearn.gaussian_process.kernels import ConstantKernel, RBF
# fit GPR
kernel = ConstantKernel(constant_value=0.2, constant_value_bounds=(1e-4, 1e4)) * RBF(length_scale=0.5, length_scale_bounds=(1e-4, 1e4))
gpr = GaussianProcessRegressor(kernel=kernel, n_restarts_optimizer=2)
gpr.fit(train_X, train_y)
mu, cov = gpr.predict(test_X, return_cov=True)
test_y = mu.ravel()
uncertainty = 1.96 * np.sqrt(np.diag(cov))
# plotting
plt.figure()
plt.title("l=%.1f sigma_f=%.1f" % (gpr.kernel_.k2.length_scale, gpr.kernel_.k1.constant_value))
plt.fill_between(test_X.ravel(), test_y + uncertainty, test_y - uncertainty, alpha=0.1)
plt.plot(test_X, test_y, label="predict")
plt.scatter(train_X, train_y, label="train", c="red", marker="x")
plt.legend()
得到结果为 l = 1.2 , σ f = 0.6 l=1.2,\sigma_f=0.6 l=1.2,σf=0.6 ,这个与我们实现的优化得到的超参数有一点点不同,可能是实现的细节有所不同导致。
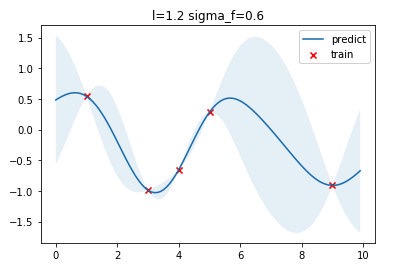
8.多维输入
上面讨论的训练数据都是一维的,高斯过程直接可以扩展于多维输入的情况,直接将输入维度增加即可。
def y_2d(x, noise_sigma=0.0):
x = np.asarray(x)
y = np.sin(0.5 * np.linalg.norm(x, axis=1))
y += np.random.normal(0, noise_sigma, size=y.shape)
return y
train_X = np.random.uniform(-4, 4, (100, 2)).tolist()
train_y = y_2d(train_X, noise_sigma=1e-4)
test_d1 = np.arange(-5, 5, 0.2)
test_d2 = np.arange(-5, 5, 0.2)
test_d1, test_d2 = np.meshgrid(test_d1, test_d2)
test_X = [[d1, d2] for d1, d2 in zip(test_d1.ravel(), test_d2.ravel())]
gpr = GPR(optimize=True)
gpr.fit(train_X, train_y)
mu, cov = gpr.predict(test_X)
z = mu.reshape(test_d1.shape)
fig = plt.figure(figsize=(7, 5))
ax = Axes3D(fig)
ax.plot_surface(test_d1, test_d2, z, cmap=cm.coolwarm, linewidth=0, alpha=0.2, antialiased=False)
ax.scatter(np.asarray(train_X)[:,0], np.asarray(train_X)[:,1], train_y, c=train_y, cmap=cm.coolwarm)
ax.contourf(test_d1, test_d2, z, zdir='z', offset=0, cmap=cm.coolwarm, alpha=0.6)
ax.set_title("l=%.2f sigma_f=%.2f" % (gpr.params["l"], gpr.params["sigma_f"]))
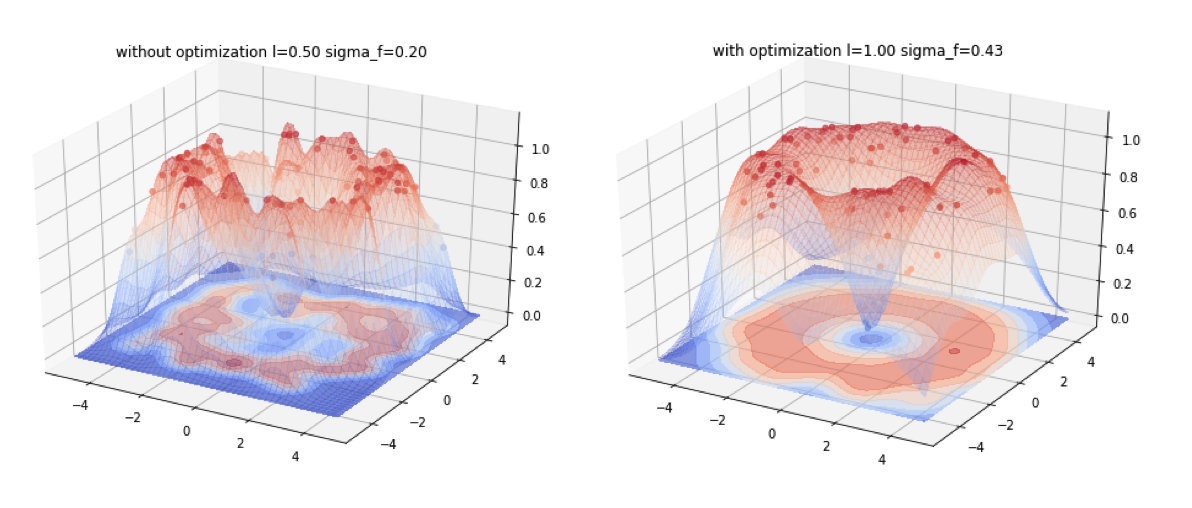
下面是一个二维输入数据的高斯过程回归,左图是没有经过超参优化的拟合效果,右图是经过超参优化的拟合效果。
9.高斯过程回归的优缺点
- 优点
- (采用 RBF 作为协方差函数)具有平滑性质,能够拟合非线性数据
- 高斯过程回归天然支持得到模型关于预测的不确定性(置信区间),直接输出关于预测点值的概率分布
- 通过最大化边缘似然这一简洁的方式,高斯过程回归可以在不需要交叉验证的情况下给出比较好的正则化效果
- 缺点
- 高斯过程是一个非参数模型,每次的 inference 都需要对所有的数据点进行(矩阵求逆)。对于没有经过任何优化的高斯过程回归,n 个样本点时间复杂度大概是 O ( n 3 ) O(n^3) O(n3),空间复杂度是 O ( n 2 ) O(n^2) O(n2),在数据量大的时候高斯过程变得 intractable
- 高斯过程回归中,先验是一个高斯过程,likelihood 也是高斯的,因此得到的后验仍是高斯过程。在 likelihood 不服从高斯分布的问题中(如分类),需要对得到的后验进行 approximate 使其仍为高斯过程
- RBF 是最常用的协方差函数,但在实际中通常需要根据问题和数据的性质选择恰当的协方差函数
本文参考:















 3150
3150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









