






NeRF
【三维重建】NeRF原理+代码讲解_nerf代码-CSDN博客
NeRF(神经辐射场)模型与传统的体素或点云方法有所不同。它不是基于体素或点云的表示,而是通过神经网络来建模场景的连续和可导函数。NeRF使用神经网络表示场景中每个点的辐射强度和密度,而不是显式地表示体素或点云。
具体来说,NeRF模型使用一个神经网络来学习场景中任意位置的颜色和密度。这个神经网络采用了类似于体积渲染的方法,但不需要显式地表示体素网格。相反,它使用称为“神经体积渲染”技术的方法,允许模型在需要时动态地生成场景中每个点的信息。
NeRF通过训练神经网络从多个视角的图像数据中学习场景的外观和形状,而不需要显式地表示体素网格或点云。这种方式使得NeRF能够以更高的精度和逼真度来重建和渲染三维场景,同时避免了体素或点云方法中固有的离散性和存储复杂性。
NeRF是一种描述和渲染3D场景的方法,在3D体积中任何给定的点上它的密度和辐射。它与光场的概念密切相关,光场是表达光如何流经给定空间的函数。对于空间中给定的(x,y,z)视点,图像将方向(θ, φ)的射线投射到一个场景中。对于这条线上的每个点,我们收集其密度和视相关的发射辐射,并以类似于传统光线追踪的方式将这些光线合成为单个像素值。这些NeRF场景是从各种姿势拍摄的图像收集学习,你会使用在结构从运动应用程序。
Background
三维重建
三维重建是指从单张二维图像或多张二维图像中重建出物体的三维模型,并对三维模型进行纹理映射的过程。根据三维模型的表示形式可将图像三维重建方法分类为基于体素的三维重建、基于点云的三维重建和基于网格的三维重建,由输入图像的类型可将图像三维重建分类为单张图像三维重建和多张图像三维重建,传统的三维重建方法通常需要输入大量图像,并进行相机参数估计、密集点云重建、表面重建和纹理映射等多个步骤。近年来,深度学习背景下的图像三维重建受到了广泛关注,并表现出了优越的性能和发展前景。
体素
体素是三维空间中的体积元素,是三维体积数据的基本单元,类似于二维图像中的像素。每个体素包含有关其位置和属性的信息,如颜色、密度、纹理等。通过组合大量的体素,可以构建出复杂的三维场景。
体渲染(Volume Rendering)
体渲染(Volume Rendering)是一种在三维体数据上进行可视化的技术,通过将体素数据转换为图像来呈现具有密度或颜色信息的三维结构。它直接处理三维体素数据,而不是在三维表面上进行光照和阴影计算。
-
体绘制(Volume Ray Casting): 通过沿射线对每个像素采样体素数据,并根据其密度或其他属性计算颜色,最终生成图像。
-
纹理映射(Texture Mapping): 将体素数据映射到二维纹理上,然后在渲染过程中使用纹理进行渲染。这通常结合了一些特殊的着色技术,以产生逼真的效果。
-
光线追踪(Ray Tracing): 类似于体绘制,但使用了光线追踪算法,考虑光线的传播和交互,以产生更真实的渲染效果。
光线投射(Ray Casting)
光线投射(Ray Casting)是一种用于图形学和计算机图形中的渲染技术。它用于生成图像,通过在三维场景中模拟光线从视点出发并与场景中的物体交互的方式。
在光线投射中,为了生成每个像素的颜色值,从观察点发出一条射线,然后检查这条射线与场景中的物体是否相交。如果相交,根据相交点处的物体属性(如颜色、材质等),以及光照模型,计算该点的颜色。这个计算过程包括考虑光的入射方向、反射和折射等因素,以产生最终的颜色值。
MLP
多层感知器,前馈神经网络,应用于分类和回归任务的模型,具有非线性建模能力。
关键技术
体渲染

体素密度σ(x)可以被理解为,一条穿过空间的射线,在x处被一个无穷小的粒子终止的概率,这个概率是可微分的,可以将其近似理解为该位置点的不透明度。
相机沿着特定方向进行观测,其观测射线上的点是连续的,则该相机成像平面上对应的像素颜色,可以理解为由对应射线经过的点的颜色积分得到。
将一条射线的原点标记为o,射线方向(即相机视角)标记为d,则可将射线表示为r(t)=o+td,t的近端和远端边界分别为tn和tf。
可将这条射线的颜色,用积分的方式表示为: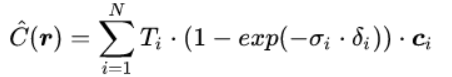
其中,T(t)表示的是射线从tn到t这一段的累计透明度,即,该射线从tn到t都没有因击中任何粒子而被停下的概率,具体写作: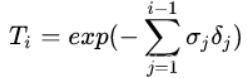
在连续的辐射场中,针对任意视角进行渲染,就需要对穿过目标虚拟相机的每个像素的射线,求取上述颜色积分,从而得到每个像素的颜色,渲染出该视角下的成像图片
分段近似渲染方法
用NeRF难以估计射线上的连续点,这就对其进行分段近似。作者提出了一种分层抽样(Stratified Sampling)的方法:首先将射线需要积分的区域[tn,tf]均匀分为N份,再在每个小区域进行均匀随机采样。则以上预测颜色C(r)的积分,可以简化为求和的形式:
其中,δi 为两个近邻采样点之间的距离,此处T(t)改写作: 这种从所有采样点的(ci,σi)集合求和得到射线渲染颜色的方法也是可微分的,并且可以简化为传统的透明度混合算法,其中alpha值 αi=1−exp(−σiδi)。
MLP
NeRF 的网络结构是一个很简单的全连接网络。
作者把密度 \\theta和颜色 RGB 分为两部分输出,这么做的考量在于,粒子密度是跟三维场景本身更强相关的属性,不管观察的方向怎么变,它都不会有太大的变化 (即论文中提到的 multiview consistent),而颜色值在不同观察方向下,受光照影响,可能会发生大的变动,它受相机位置和观察方向的影响都更大。
基于此,论文先把相机位置 (x,y,z) 经过位置编码 后拓展成 60 维的向量,送入一堆全连接网络 (FC 层) 后,分叉出两路,其中一路经过一个 FC 层和 ReLU 后输出 \theta 值,另一路和方向向量经过位置编码的向量 结合后,一起送入之后的全连接网络,最后经过 Sigmoid 输出颜色值 RGB。

网络输出的 theta 和 RGB 就是一条光线上一个采样点对应的粒子密度和颜色值。在整个训练过程中,我们会收集所有光线上所有采样点的粒子密度和颜色,再根据体渲染得到预测的投影视图,然后和真实的投影视图计算 loss 来训练网络。
Positional Encoding
实验发现:如果给网络输入的数据维度越高 (越高频),那网络也能输出更加高频的信号 (即图像清晰度越好)。把输入拓展成更高维,那网络的输出信号会包含更高维的信息,图像内容会更丰富。
对于位置向量 (x,y,z),论文选取的 L=10,即每个元素会拓展成 20 维,所以在之前的网络输入中,输入是 60 维的向量。而方向向量的 L=4,对应的 positional encoding 则是 24 维 (3*8)。
Hierarchical sampling
分层采样
在实际情况中,粒子在空间中的分布也是不均匀的,有些采样点可能粒子密度很高,有些则密度几乎为 0。
因此,在密度高的地方多放一些采样点是比较合适的,即做 importance sampling。论文为此设计了一种由粗到细的分层采样方法。
其设计思路非常简单:首先,先在每条光线上均匀采样若干点,让网络预测出这些点的粒子密度,然后,根据这些密度信息,重新在密度更高的采样点附近,多采样一些点,再让网络预测一轮,两轮预测的结果分别计算 loss。这样一来,网络便可以在密度高的区域学到更多有效

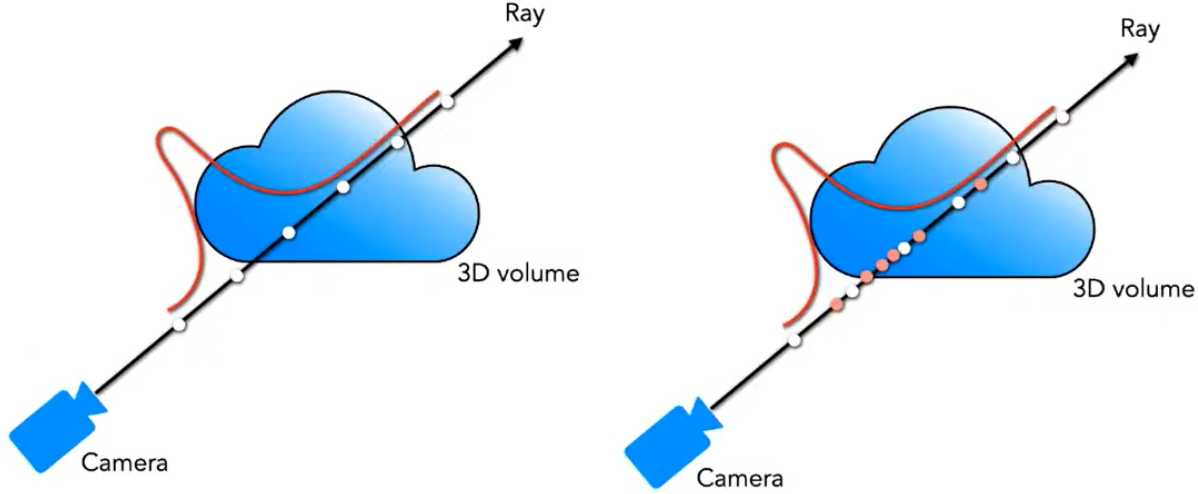
shiyanxijie
损失函数为粗模型(64个采样点)和细模型(128个采样点)的平方和,便粗网络的权重分布可以用于在细网络中分配样本。

消融实验
观察到位置编码(positional encoding)和视图依赖(view-dependence)提供了最大的增益,其次是分层抽样(Hierarchical volume sampling)。
"View-dependence"(视角相关性)是指在计算机图形学和计算机视觉中,渲染或分析的结果受到视点或观察角度的影响。即相机或传感器的位置和朝向可能影响对物体的识别和定位。解决视角相关性问题的方法包括使用多视角信息,融合多个视角的信息以提高稳健性和准确性。
Conclusion
薄纱其他所有三维重建模型

NeRF 相比之前的工作,最大的优势就是渲染出来的图像清晰度更高,更真实。但同样存在几个严重的问题。
首先,NeRF 的渲染速度极其慢。
其次,NeRF 只适用于一个场景,如果换了别的场景,就得重新训练了,泛化能力很差。
NeRF流程
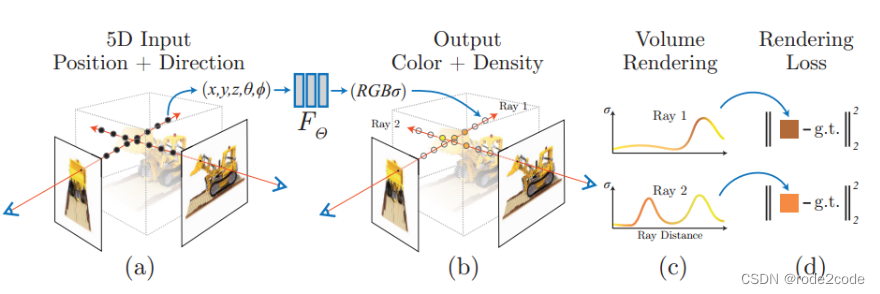
(a)我们通过沿着相机光线采样5D坐标(位置和观看方向)来合成图像。
(b)将这些位置输入MLP以产生颜色和体积密度。
(c)使用体渲染技术将这些值合成为图像。
(d)该渲染函数是可微的,因此我们可以通过最小化合成图像和真实图像之间的残差来优化场景表示。















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









