






近日,阿里Qwen(千问)团队发布并开源了一款被称为“小而美”的推理模型——QwQ-32B。这款模型以其“轻巧”的参数规模——320亿(32B),以及能够媲美更大参数模型的卓越性能(例如与满血版DeepSeek-R1相当),迅速引起了广泛关注和热议。
与此前的DeepSeek模型相比,QwQ-32B的部署灵活性显著提升。DeepSeek的满血版模型通常需要依赖云平台进行部署,个人用户往往只能使用蒸馏版模型,性能上难免有所妥协。而QwQ-32B则打破了这一限制,仅需单张NVIDIA 4090D显卡即可完美运行,为个人开发者和技术爱好者提供了尝鲜的机会。这一突破不仅降低了高性能AI模型的使用门槛,也为更多创新应用提供了可能性,堪称AI技术普惠化的重要一步。
总的来说,QwQ-32B凭借其高效的架构设计、强大的性能表现以及低门槛的部署方式,成为了当前AI领域的一颗新星。无论是对于企业还是个人开发者,这款模型都带来了更多的想象空间和实际应用价值。
1、使用云平台创建实例
星海智算是一家专为人工智能应用打造的GPU计算服务平台,汇聚了4090、4090D、A100、V100、3090等多款热门GPU型号。其价格极具竞争力,4090型号的GPU每小时使用成本不足2元。
新用户可通过星海智算官网完成注册,实名认证并首次充值超过6元即可领取10元代金券。或通过专属邀请链接https://gpu.spacehpc.com/user/register?inviteCode=21735375)注册,还可额外获得10元代金券。
登录平台后,用户可在控制台的GPU实例模块中创建新实例。例如,选择内蒙B区的A100 PCIE,磁盘容量可选择扩容50GB,在镜像市场选择通义千问QWQ-32B镜像环境进行创建。
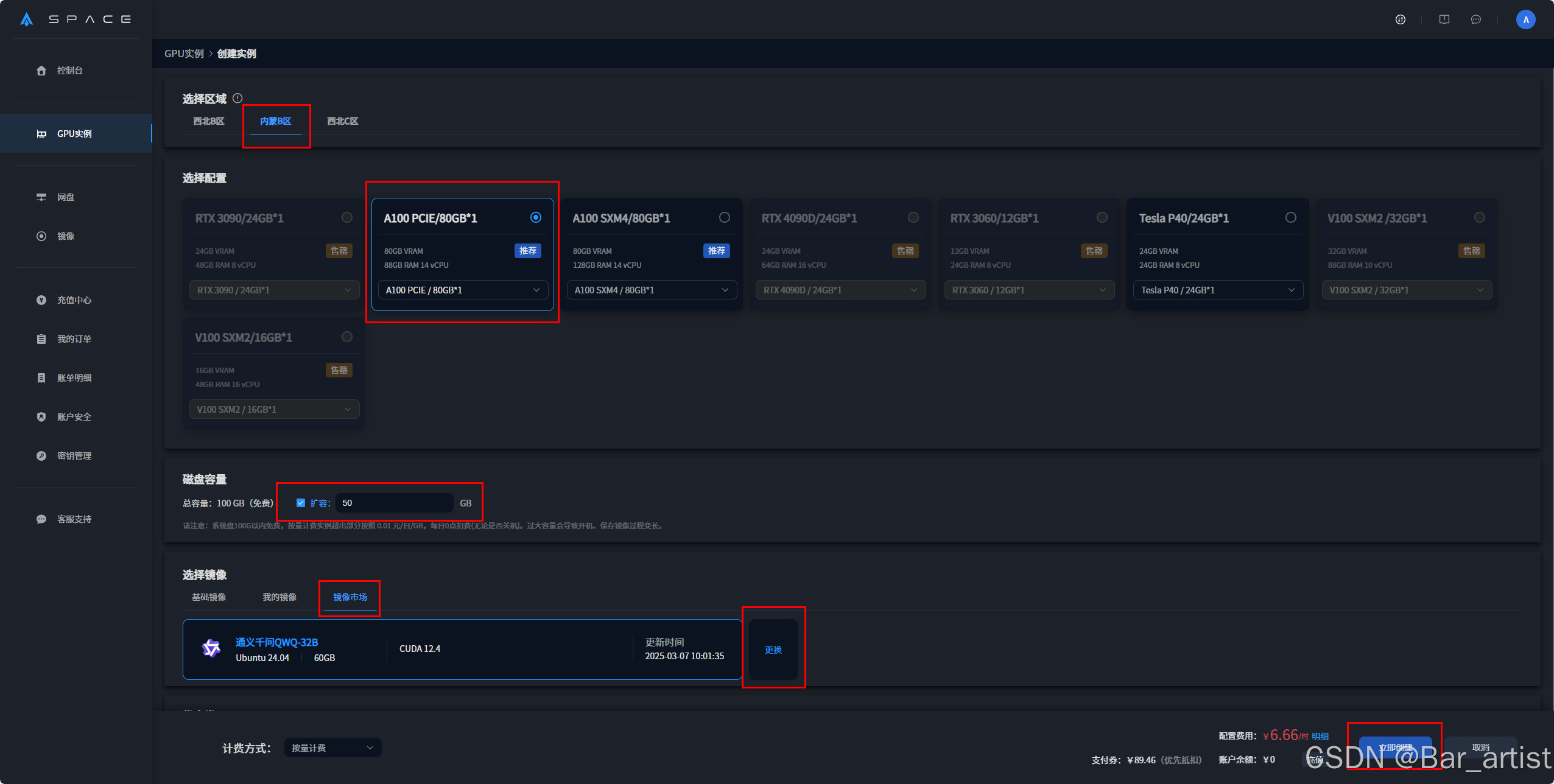
创建成功后,状态栏呈现“运行中”,点击JupyterLab。

进入JupyterLab后,开一个终端。
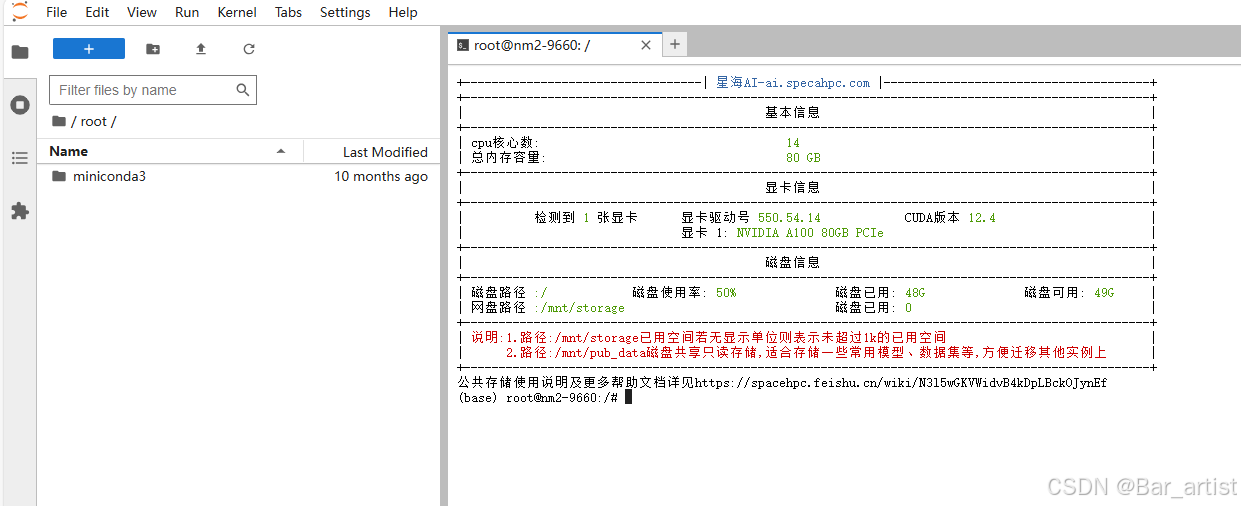
终端内会自动显示CPU、内存、显卡、磁盘等信息。
2、部署并使用QwQ-32B
状态栏“运行中”时,点击右侧应用服务

进入qwq:latest界面,就可以开始提问了。
以下是一个示例,以作为参考。
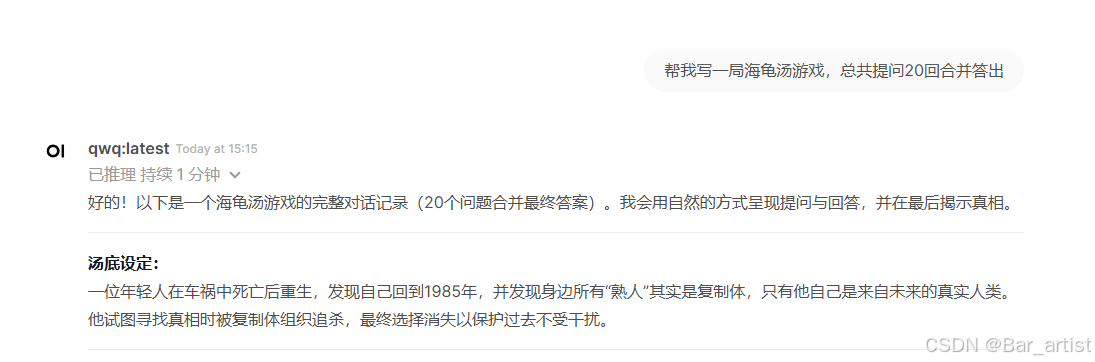


可以看出通义千问QWQ-32B 回答的很详细。并且进行创建和部署的步骤也是非常简单便捷。

















 678
678

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









