







 YOLO是一种快速、统一的目标检测方法,通过单个神经网络直接预测边界框和类别概率。相比于其他检测系统,YOLO速度快、能捕捉全局上下文信息,但定位精度有待提高,尤其在处理小目标时。YOLO将图像划分为网格,每个网格负责预测固定数量的边界框和类别。
YOLO是一种快速、统一的目标检测方法,通过单个神经网络直接预测边界框和类别概率。相比于其他检测系统,YOLO速度快、能捕捉全局上下文信息,但定位精度有待提高,尤其在处理小目标时。YOLO将图像划分为网格,每个网格负责预测固定数量的边界框和类别。
摘要
我们介绍了一种新的对象检测方法名为YOLO。在进行目标检测前,要进行分类来进行检测。相反,我们将对象检测框架变为空间分离的边界框和相关类别概率的回归问题。单个神经网络在一次评估中可以直接从完整的图像中预测边框和所属类别的概率。由于整个检测管道是单个神经网络,所以可以直接对检测性能进行端到端的优化。
我们的这种统一框架非常快。我们的基础YOLO模型以每秒45帧的速度处理实时图像。该网络的一个小版本,名为Fast YOLO,每秒处理的速度达到惊人的155帧,同时还能达到其它实时探测器的两倍。在和最先进的检测系统对比时,YOLO出现了较多的定位错误,但在背景上预测正像时出现的错误较少。最终,YOLO学习到了目标非常一般化的表示方法。当从自然图像推广到其他领域时它比其它检测方法表现更好。
引言
人类看一眼图像就知道图像中有什么,它们在图像中的什么位置,以及它们是如何相互联系的。当前的检测系统将分类器重新应用于目标检测。为了检测对象,这些检测系统在目标上使用了一个分类器,并在测试图像的不同位置和不同尺度上进行评估。诸如DPM(deformable parts models)这样的系统使用了一个滑动窗口,使得分类器等间隔地应用在了整个图像上。
最近的一些方法,例如R-CNN,使用区域建议法首先在图像上生成潜在的边界框,然后在这些建议的框上运行分类器。在分类结束后,使用后处理重新优化边界框,消除重复的检测,并根据场景中的其它目标对这些边界框进行二次评分。由于这些组件必须分开单独进行训练,导致这些复杂的结构速度慢并且难以优化。
我们将对象检测问题定义为一个单一的回归问题,直接从图像像素到边界框坐标和类别的概率。使用我们的系统,一次就可预测出图像中的目标是什么,它们在哪里。
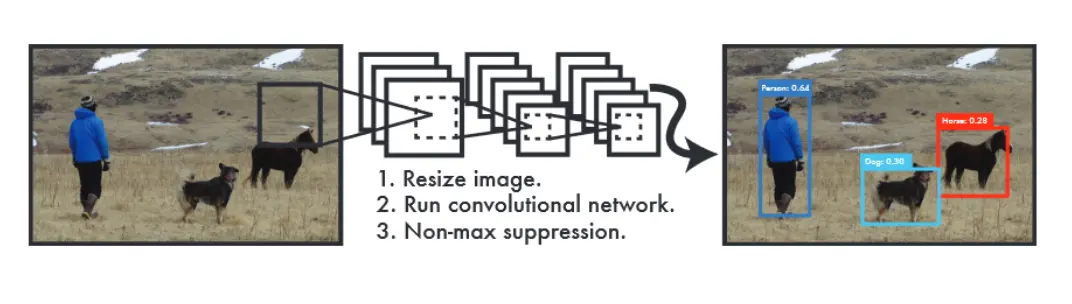
YOLO很简单,如图1,一个单一的卷积网络同时预测多个边界框和这些边界框所属类的概率。YOLO可以在整张图像上训练,并直接优化检测性能。这个统一的模型相比传统的目标检测方法有以下一个优点:
- 首先,YOLO非常快。我们将检测任务作为一个回归问题,不需要复杂的管道连接。我们在测试时在一个新图像上运行我们的神经网络来预测检测的结果。
- YOLO的预测结果是针对全局图像的。不像滑动窗口和基于区域的建议技术,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9195
9195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









