









题目:
Chp3 Lab: Analysis of Instruction Execution Pipelining
问题描述:
Using the following code fragment:
LOOP: LW R1,0(R2) ; load R1 from address 0+R2
ADDI R1,R1,#1 ; R1=R1+1
SW 0(R2),R1; store R1 at address 0+R2
ADDI R2,R2,#4; R2=R2+4
SUB R4,R3,R2; R4=R3-R2
BNEZ R4,Loop ; branch to loop if R4!=0
Assume that the initial value of R3 is R2+396.
Analyze (a) by showing the timing of the first two iterations and calculate the total cycles needed; implement (b) and (c) in WinMIPS64. Execute the code in WinMIPS64.
(a) Show the timing of this instruction sequence for the RISC pipeline without any forwarding or bypassing hardware but assuming a register read and a write in the same clock cycle “forwards” through the register file. Assume that the branch is handled by flushing the pipeline. If all memory references take 1 cycle, how many cycles does this loop take to execute?
(b) Show the timing of this instruction sequence for the RISC pipeline with normal forwarding and bypassing hardware. Assume that the branch is handled by predicting it as not taken. If all memory references take 1 cycle, how many cycles does this loop take to execute?
(c) Assume the RISC pipeline with a single-cycle delayed branch and normal forwarding and bypassing hardware. Schedule the instructions in the loop including the branch delay slot. You may reorder instructions and modify the individual instruction operands, but do not undertake other loop transformations that change the number or opcode of the instructions in the loop. Show a pipeline timing diagram and compute the number of cycles needed to execute the entire loop.
问题分析:
在开始实验前,我们需要明确,题目中的代码为32位的代码,显然无法在64位的WinMIPS64上运行。所以我们需要将上述代码进行如下的转换:
64位与32位的区别(32位的w:word ----- 64位的d: double)
运算类:add变成dadd,同理sub/mul/div变成dsub/dmul/ddiv
访存: lw变成ld, sw变成sd
寄存器名: S0/S1… 全部变为r0/r1/… / r31
但是还有个问题,并没有见到$符号来表示寄存器,但是见到了#符号用来表示立即数。我查阅资料,#的运用应该比较少用,保险起见,我们去掉#,这样WinMIPS64上可以安心运行。我再加个HALT,用来中止程序以防万一。如果不是DLX的架构的话,题目中,SW 0(R2),R1这个语句源操作数和目的操作数是颠倒的(在WinMIPS64中会报错),应该为SW R1,0(R2),我查阅很多资料,发现全网这个题目都是到处乱抄的都是颠倒的模样(除了华中科技大学博士入学考试真题),他们好像能够在WinMIPS64中运行,但是只能说演技很真。或者说在他们的指令集这是对的,至少在WinMIPS64中这是无法运行的。我们都知道汇编代码一般不区分大小写,我们就都大写表示吧,要不然显得不伦不类。
流水线结构上:默认存在指令存储器和数据存储器(IF和MEM中的取指令和取数据不再冲突,该部分的结构冒险可忽略)
转换后的代码如下:
.text
DADDI R3,R2,396;the initial value of R3 is R2+396
LOOP:
LD R1,0(R2) ; load R1 from address 0+R2
DADDI R1,R1,1 ; R1=R1+1
SD R1,0(R2); store R1 at address 0+R2
DADDI R2,R2,4; R2=R2+4
DSUB R4,R3,R2; R4=R3-R2
BNEZ R4,LOOP ; branch to loop if R4!=0
HALT
(a)Show the timing of this instruction sequence for the RISC pipeline without any forwarding or bypassing hardware but assuming a register read and a write in the same clock cycle “forwards” through the register file. Assume that the branch is handled by flushing the pipeline. If all memory references take 1 cycle, how many cycles does this loop take to execute?
我们先假设所有的存储器存取都命中(模拟器有这个讲究吗?严谨一些算了)。
要求:没有任何前推(又名前递)(Forwarding)或者旁路操作(Bypassing),两者从根本上来说,前递和旁路指的都是同件事情。只不过是观察和描述的角度不同而已。前递是从指令执行顺序的角度来描述的,而旁路则是从电路的结构角度来描述,而这个 a register read and a write in the same clock cycle “forwards” through the register file是指W、B阶段在寄存器堆中读写不矛盾,因为前半周期写,后半周期读嘛。这里问题中我们是纯手工模拟使用的是通常的架构,BNEZ中EX阶段执行的是判断,MEM阶段将转移地址转移到PC中。这与后面的模拟器中的架构有所区别,模拟中BNEZ指令ID阶段执行了两个操作即判断和转移指令到PC。
(1)、什么是前推和旁路?
前推(Forwarding):比流水线停顿更进了一步。流水线停顿(Stall)的方案,就像一条车队在路上行驶,当它们经过路口中间的时候,红灯亮了,根据交通规则,已经过线的车,仍然可以通过路口,而在线后面的车只能在队列(假设只有一条路)中排队等待,在绿灯亮前,后一辆车车永远不会到前一辆车的位置(除非他飞起来),他们都得在那里等着,而幸运的已过线的车,可能已经轻舟已过万重山了。而操作数前推,就好像短跑接力赛。后一个运动员可以提前抢跑,而前一个运动员会多跑一段主动把交接棒传递给他。在流水线中每条在流水线移动的指令就是运动员,而每个壁就是该阶段的流水线寄存器,前推则会
旁路(Bypassing):也就是在第 1 条指令的执行结果,直接“转发”给了第 2 条指令的 ALU 作为输入。为了能够实现这里的“转发”,我们在 CPU 的硬件里面,需要再单独拉一根信号传输的线路出来,使得 ALU 的计算结果,能够重新回到 ALU 的输入里来。这样的一条线路,就是我们的“旁路”。它越过(Bypass)了写入寄存器,再从寄存器读出的过程,也为我们节省了 2 个时钟周期。
(2)、什么是流水线冲刷?(flushing the pipeline)
分支指令通常在EX阶段决定是否跳转,分支指令后续的两条指令都将被取值并且开始执行。如果不进行干预,这两条条后续指令会在 beq 指令跳转之前就开始执行,这样就是我们不期望的。所以,在BEQ指令的EX阶段,后两条指令分别进入取指和译码阶段,如果要跳转,则需要将后两条指令清理掉,否则放任两条指令继续执行会改变寄存器的值从而导致错误的结果,这就是流水线冲刷机制。
将前两级流水线寄存器冲刷掉可以通过插入nop指令(气泡)来实现,当BEQ指令的EX阶段判断要跳转时,给IF_ID、ID_EX流水线寄存器一个clear信号,使得它们在下一周期输出为0。同时,也要将ID_EX流水线寄存器中的控制信号清零。
流水线时空图如下:
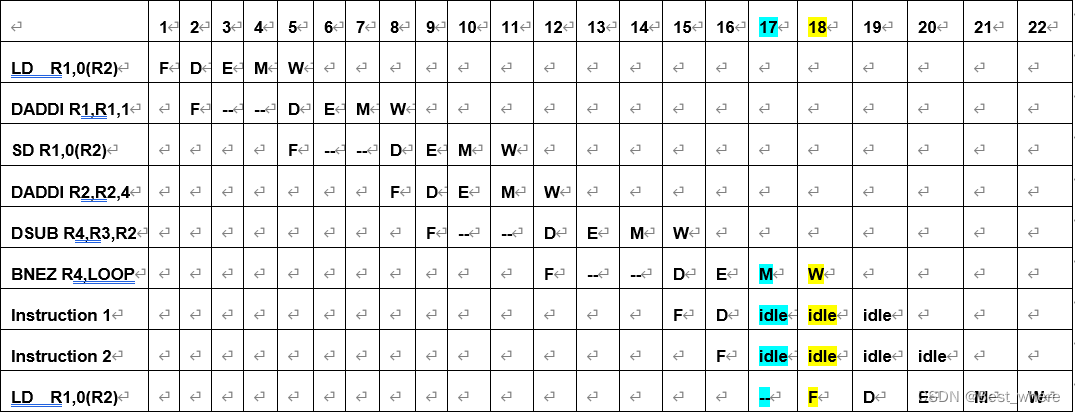
时空图解读:

蓝色圈内代表着寄存器堆中的先写后读,可以有效解决流水寄存器中W和B阶段的矛盾。其它注释如上图所示。
可以看出第二次迭代是在18cycles时开始的,按照总共的计算,这个循环结构要进行396/4=99次循环。但是在计算过程中,我们将前面的98次循环每次看做是17cycles的循环体,而最后一次循环看做是18cycles,这样可以做到循环不重不漏,计算简便。
那么总共的流水线长度为=17*98+18=1684 clock cycles
(b)Show the timing of this instruction sequence for the RISC pipeline with normal forwarding and bypassing hardware. Assume that the branch is handled by predicting it as not taken. If all memory references take 1 cycle, how many cycles does this loop take to execute?
(1)、前递和旁路上述已经解释,如上。
(2)、预测不转移(treat every branch as not taken predict-not-taken):
每次转移指令,在还没做出判断前,我们都当做是不转移,继续执行下面紧挨着的语句,直到可以判断是否转移的时候,再进行相应的转移或者继续延续。
(3)、WinMIPS64中分支转移默认是预测不转移的,所以我们只用设置前递功能就行了。
- 问题解决:
手工分析:
由于题目给的信息过少,这里我们不得不假设,ID阶段并没有添加小型的加法器,以及0比较器。
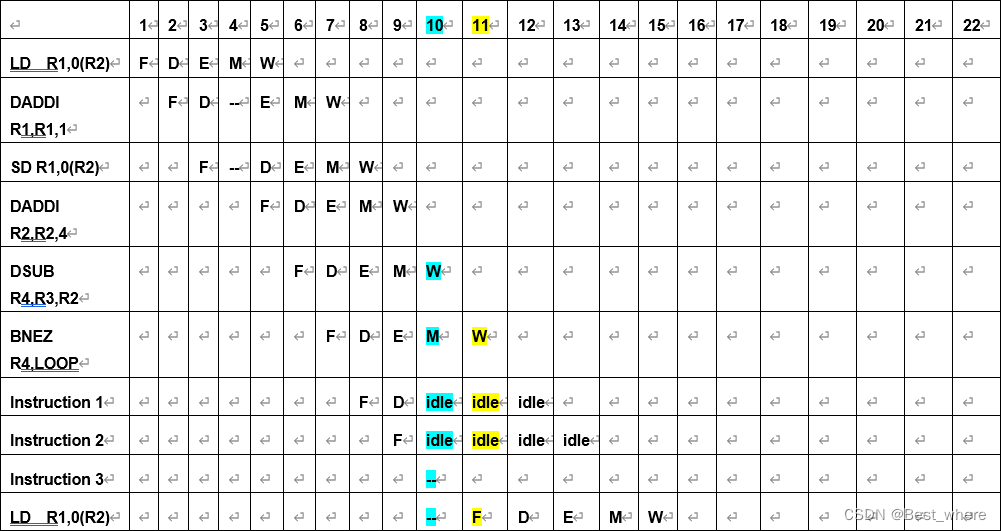
手工时空图解读:

蓝色方框内代表着寄存器堆中的先写后读,可以有效解决W和D阶段的矛盾,其它的指令的W/D阶段也有重叠,但是涉及到的写和读的寄存器不同,(有的硬件内部的读和写可能是两个端口)在这里只有时间先后,数据冒险的表现太小,更多的算是结构冒险,我们每个标记的就多了,这里就不标记了。其它注释如上图所示。
WinMIPS64模拟:
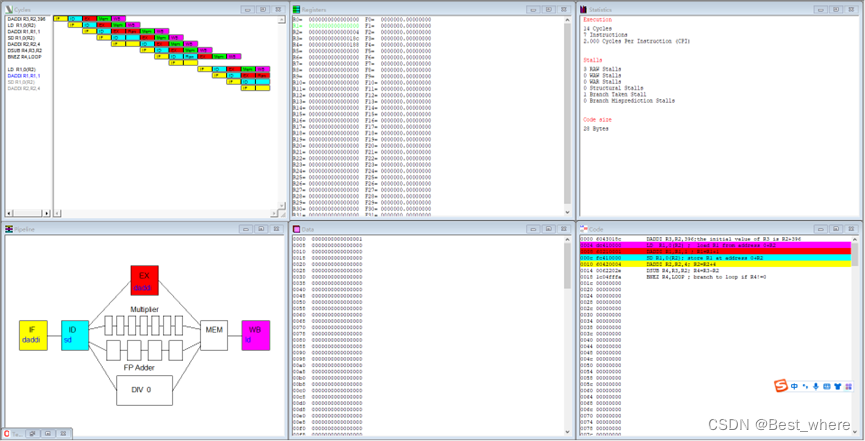
模拟器模拟的结果,一开始令我稍稍不解,据我大致暂时理解为:手写和模拟这两种都是等价的,只是模拟器有自己的设计思路。我自己手画的时空图想要ADDI指令在ID阶段执行完后就开始停顿一个cycle再进入EX阶段;而模拟器ADDI指令在ID阶段执行完后,就直接进入EX阶段,但是这个时候的EX阶段是是无效的,并没有进行实际的动作,属于状态锁存的状态,而然后还是EX阶段,这个时候的EX阶段才真正等到了数据,并进行了执行,实际上第一次进入的EX阶段便是停顿,只是模拟器把它归属为EX阶段罢了。就我认为有些不太节约因为同时停顿了三条指令,而我手画的时空图只用停顿两条指令,还是以我手推的时序图为主吧。
手工图结果:
(BNEZ的判断仍然在EX阶段,M阶段后才有下一条指令的地址)
可以看出第二次迭代是在11cycles时开始的,按照总共的计算,这个循环结构要进行396/4=99次循环。但是在计算过程中,我们将前面的98次循环每次看做是10cycles的循环体,而最后一次循环看做是11cycles,这样可以做到循环不重不漏,计算简便。
那么总共的流水线长度为=10*98+11=991 clock cycles
模拟器结果:
(显然模拟器中的BNEZ的ID阶段添加了小型的加法器,以及0比较器)这与题目要求有所出入,也是与我们答案有出入的原因但是不妨碍我们分析。
加上R3的预处理指令和HALT指令:9*98+12+1+1=896 clock cycles
忽略R3的预处理指令和HALT指令(减去两个1):9*98+12=894 clock cycles
两个1分别的原因是:R3的预处理指令和HALT指令各自造成了流水线cycle加1。
前98个周期循环体看作是9个cycle,最后一个周期看做是12个cycle即完整的一个周期。

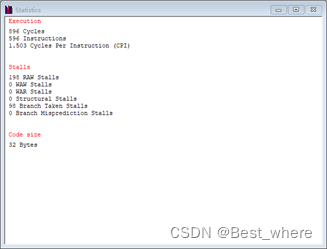
<图1 单循环> <图2 完整运行>
(c) Assume the RISC pipeline with a single-cycle delayed branch and normal forwarding and bypassing hardware. Schedule the instructions in the loop including the branch delay slot. You may reorder instructions and modify the individual instruction operands, but do not undertake other loop transformations that change the number or opcode of the instructions in the loop. Show a pipeline timing diagram and compute the number of cycles needed to execute the entire loop.
- 问题解读:
(1)、前递和旁路上述已经解释,如上。
(2)、也就是延迟槽中只放一条语句(single-cycle delayed branch):
延迟槽中的语句必然会执行
(3)、WinMIPS64中分支转移默认是预测不转移的,所以我们只用设置前递功能就行了。
- 问题解决:
(1)、首先要重整语句顺序,自己充当编译器的角色,将上述的一条语句放入延迟槽中。
调整如下:
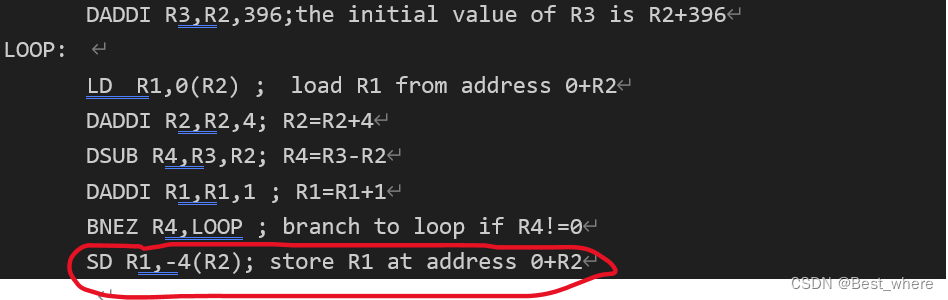
BNEZ指令之下的这条语句(红圈之内的语句)充作延迟槽中的内容。
延迟槽中的这条语句与 ![]() BNEZ语句并不依赖,它的改善是永久的,我们发现无论是判断转移还是不转移,效果均是改善的,是最好的策略(From before)。
BNEZ语句并不依赖,它的改善是永久的,我们发现无论是判断转移还是不转移,效果均是改善的,是最好的策略(From before)。
手工图时序图:
这种情况下的ID阶段添加了小型的加法器,以及0比较器,因此分支转移指令在ID后便知道是否转移,及下一步的转移地址。

手工时序图解读:

WinMIPS64模拟:
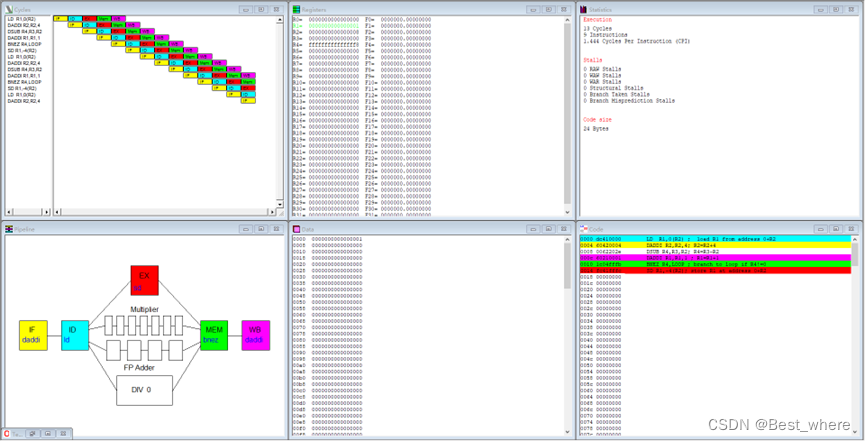
上述的时空图是完美状态,可以说已经基本不可以再优化了,没有任何停顿,呈台阶状。
手工图结果:
可以看出第二次迭代是在7cycles时开始的,按照总共的计算,这个循环结构要进行396/4=99次循环。但是在计算过程中,我们将前面的98次循环每次看做是6cycles的循环体,而最后一次循环看做是10cycles,这样可以做到循环不重不漏,计算简便。
那么总共的流水线长度为=6*98+10=598 clock cycles
模拟器结果:
(显然模拟器中的BNEZ的ID阶段添加了小型的加法器,以及0比较器)这与题目要求有所出入,也是与我们答案有出入的原因但是不妨碍我们分析。
加上R3的预处理指令和HALT指令:6*98+10+1+1=600 clock cycles
忽略R3的预处理指令和HALT指令(减去两个1):6*98+10=598 clock cycles


左图为单次循环的图,右图为完整程序运行的图。
这个时候模拟器和手工结果形成了惊人的一致!!(当然这得去了R3的预处理指令和HALT指令的情况下)















 2260
2260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









