









HashMap(JDK 8):
为什么用HashMap:
- HashMap 是一个散列桶(数组和链表/红黑树),它存储的内容是键值对 key-value 映射
- 当hash冲突越少时(链表长度短,红黑树深度小),增删改查的时间复杂度越接近O(1),也可能是O(n)或O(log n)(n为某个位置hash冲突的元素个数)
- HashMap 是非 synchronized,所以对 HashMap的操作很快
- HashMap、LinkedHashMap 可以接受 null 键和值,TreeMap可以接收值为null,其余Map的K 、V 不能接受null
HashMap的工作原理:
- HashMap是基于hashing原理的,使用 put(key, value) 存储对象到 HashMap 中,使用 get(key) 从 HashMap 中获取对象。
- 当使用 put() 方法传递键和值时,先对键调用 hashCode() 方法,然后找到bucket中的位置来存储Node对象。当对键计算得到的hash值出现冲突时,采用链表尾插法链接多个Entry,当链表元素超过8转红黑树,当红黑树节点少于6转为链表。
- 当使用get()方法时,使用键对象的hashcode 找到 bucket 位置。如果该 bucket 位置,存在多个Entry,开始从头遍历调用 keys.equals() 方法去找到链表中正确的节点,最终找到要找的值对象。
为什么红黑树与链表的转换会使用8 / 6:
-
为避免红黑树、链表的重复转换,使用当树中节点少于6时,链表节点大于8时,才发生转换。当元素少于8时,使用Node占用空间少,操作速度快。
-
红黑树的插入、删除和遍历的最坏时间复杂度都是log(n),TreeNode占用更多的空间,只有当拥有足够的元素,才有使用红黑树的必要。桶中的某一位置出现hash冲突是一个随机事件,发生概率遵循泊松分布,桶中某一位置Entry对长度超过8的概率非常小,在源码中有举例说明,故选择8。
HashMap扩容机制:
使用空参构造方法:
Map容量为16,当Map中元素个数大于12(= DEFAULT_INITIAL_CAPACITY(16) * DEFAULT_LOAD_FACTOR(0.75))后,扩容为大于16的第一个2的幂(32)
使用指定初始容量的构造方法:
Map容量为大于等于传入参数的第一个2的幂(如:传入7,则Map容量为:8;传入8,则Map容量为:8),当Map中元素个数大于capacity (= 初始化的容量 * DEFAULT_LOAD_FACTOR(0.75))后,扩容为大于capacity的第一个2的幂
《阿里Java开发手册》建议设置initialCapacity=(需要存储的元素个数 / 负载因子(默认:0.75))+1,来减少重建hash表对性能的消耗。
为什么负载因子选择0.75:
如果使用 0.5,那么 Map 中未利用的空间将会随着容量的增长而增长,如果使用1,那么在使用put方法时,将会延长等待时间。在源码中也只是说了“默认负载因子(0.75)在时间和空间成本上提供了很好的折衷”,负载因子的选择可以按实际项目情况来。
扩容时,需要重新计算hash吗?
在 JDK 8 之前需要重新计算 hash 值,JDK 8 开始,hash 值不重新计算,只是根据不同 hash 值和之前的 bucket 容量进行与运算( (e.hash & oldCap) == 0 ),如果结果为0,元素在 bucket 中的索引值不变;如果不为0,元素的索引值变为 j(原索引)+OldCap(原bucket大小) 。参考下列源码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
-start-------------------------
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
-end-------------------------
}
}
return newTab;
}
在上面标记的一段中,(e.hash & oldCap) == 0 是为了求得当前 hash 值与 oldCap(=2^n)二进制的最高位1,是否相同,同则结果为1,不同结果为0。例如:16 & 32 = 0,hash值为16的元素在扩容后索引值不变; 17 & 16 !=0,hash值为17的元素在扩容后索引值变为 j +16
HashMap 如何求得 key 的 hash 值?为什么容量使用的是2的n次方?HashMap 是如何通过 hash 值定位某一个元素的?
JDK 8 HashMap 中的源码:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//获取某一元素在桶中的位置
int index=(n - 1) & hash;//n = tab.length ,tab为散列桶的数组

hash 值是 32bit 的 int 类型,不能使用 hash 值的范围(40亿个位置)为散列桶数组的容量,故需要将 hash 值缩小到适合的大小。
通过右移(>>>)和异或(^)运算,将 hash 值的高16位与低16位进行异或运算,这样做是为了让高低位的信息混合,再把得到的 hash 值和散列桶容量 - 1 进行与(&)运算,得到 hash 值的最后几位,这便是散列桶数组中的索引。
在进行 与运算 时,为了得到在数组范围内的索引,就必须要和 2^n(散列桶容量) - 1 (该式保证低位全为1)做运算。
LinkedHashMap:
它是一个继承至 HashMap 的有序的散列桶,这里的有序可以是插入顺序或访问顺序,可在构造器中传入accessOrder(默认false,表示按插入顺序)来控制有序性。
类图:
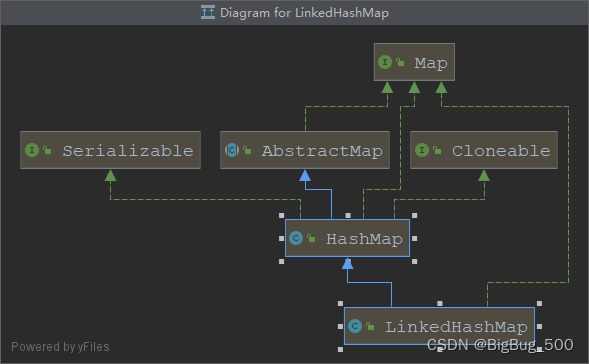
关键代码:
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>{
... ...
/**
* Constructs an empty {@code LinkedHashMap} instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - {@code true} for
* access-order, {@code false} for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
/**
* 插入新节点才会触发该方法
* 根据 HashMap 的 putVal 方法, evict 一直是 true
* removeEldestEntry 方法表示移除规则, 在 LinkedHashMap 中默认返回 false,即不移除最近最少被访问的节点
* 所以在 LinkedHashMap 里这个方法相当于什么都不做
*/
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// 根据条件判断是否移除最近最少被访问的节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
// 移除最近最少被访问条件之一,通过重写此方法可实现不同策略的缓存
// LinkedHashMap是默认返回false的,我们可以继承LinkedHashMap然后重写该方法即可
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
... ...
}
EnumMap:
特点:
-
用Enum类型作为key的HashMap
-
可以根据Enum类型的key,快速定位,而不需要对key求hashcode(),故效率高
public class EnumMapTest {
@Test
public void enumMapTest() {
System.out.println(Color.GREEN.ordinal() + " : " + Color.GREEN.name());
EnumMap<Color, String> map = new EnumMap<>(Color.class);
map.put(Color.RED, "red");
map.put(Color.BLACK, "black");
map.forEach((k, v) -> {
System.out.println(k + " : " + v);
});
//RED : red
//BLACK : black
}
}
enum Color {
RED, GREEN, YELLOW, BLACK
}
WeakHashMap:
定义:
其key是弱引用类型,在GC执行垃圾回收时,会移除弱引用对象(当将键值对中的key设置为null时,其指向的对象便是弱引用对象),所以,WeakHashMap的size()方法返回值会随着程序的运行变小,isEmpty()方法的返回值会从false变成true等。
WeakHashMap可作为缓存使用,在Tomcat中有具体的使用。
TreeMap(按key排序):
TreeMap的底层是通过红黑树来实现的,其查找、修改、增加的时间复杂度都为O( log n )。
TreeMap的排序是因为实现了NavigableMap接口,而它又继承了SortedMap接口。
定义TreeMap的key排序规则,默认是对key排升序:
/**
* @Author Snail
* @Describe 自定义treemap的升序与降序
* @CreateTime 2019/8/16
*/
public class TestTreeMap {
@Test
public void treeMapOrder(){
TreeMap<Integer,String> treeMap=new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//o1-o2:表示用升序,o2-o1:为降序
return (Integer) o2-(Integer) o1;
}
});
treeMap.put(1,"aaa");
treeMap.put(3,"bbb");
treeMap.put(2,"bbb");
treeMap.put(9,"bbb");
treeMap.put(5,"bbb");
for(Map.Entry<Integer,String> entry:treeMap.entrySet()){
System.out.println(entry.getKey() + "::::::::::::::::" + entry.getValue());
}
}
@Test
public void treeMapOrderBean(){
TreeMap<Bean,String> treeMap=new TreeMap(new Comparator<Bean>() {
@Override
public int compare(Bean o1, Bean o2) {
//o1-o2:表示用升序,o2-o1:为降序
return o2.getOrder()-o1.getOrder();
}
});
treeMap.put(new Bean(2),"aaa");
treeMap.put(new Bean(5),"aaa");
treeMap.put(new Bean(3),"aaa");
treeMap.put(new Bean(6),"aaa");
treeMap.put(new Bean(10),"aaa");
treeMap.put(new Bean(1),"aaa");
for(Map.Entry<Bean,String> entry:treeMap.entrySet()){
System.out.println(entry.getKey().getOrder() + "::::::::::::::::" + entry.getValue());
}
}
}
class Bean{
private Integer order;
public Bean(int i) {
order=i;
}
public Integer getOrder() {
return order;
}
public void setOrder(Integer order) {
this.order = order;
}
}
HashSet(基于HashMap实现的HashSet):
HashSet中,所有键值对存储的值都是PRESENT(源码:private static final Object PRESENT = new Object();),HashSet的add方法将值存入了key(key的存储,满足HashMap的put方法),这也就满足了 Set 中元素不重复的特性。
ConcurrentHashMap(高效率的线程安全的Map容器)
JDK 1.7 下的分段式锁
将 HashMap 中的散列桶数组分成多段 Segment 存储,加锁时使用 Segment 对象,当一个线程占用锁操作其中一段数据的时候,其他段的数据也能被其他线程操作
//Segment.put(...) 方法中尝试获取锁的代码
HashEntry<K,V> node = tryLock() ? null : scanAndLockForPut(key, hash, value);
JDK 1.8 下如何控制线程安全的?
使用synchronized 、CAS 和 volatile 机制来保证并发操作时的线程安全。
源码分析(标注代码位置,去阅读源码中的注释)
- 实例化:通过 Unsafe.objectFieldOffset 方法获取指定Field(例如sizeCtl)在内存中的偏移量。
- ConcurrentHashMap.java:6287
- 初始化Map容器(transient volatile Node<K,V>[] table):第一次插入值时懒惰地初始化,使用 CAS 控制初始化时的线程安全问题。若当前线程 CAS 失败,使用 Thread.yield 释放当前线程的CPU执行时间片,等待下次执行,即自旋重试,直到 table 完成初始化。
- ConcurrentHashMap#initTable
- put(key, value):
- 当 table 中,key对应的 index 没有值时,使用 CAS 的方式完成值的新增
- ConcurrentHashMap.java:1018
- 当 table 中,key对应的 index 有值(即出现了 hash 冲突),使用 synchronized 锁住该 index 位置的 Node 对象(可能为链表头或红黑树的 root)
- ConcurrentHashMap.java:1025
- 当 table 中,key对应的 index 没有值时,使用 CAS 的方式完成值的新增
- 扩容 transfer(table, nextTable):
- 当判断需要扩容时,初始化一个新的hash表(nextTable)出来,大小是原来的2倍
- 在整个过程中,共享变量的变更和读取全部通过 volatile + CAS的方式,保证了线程安全。
- ConcurrentHashMap 锁的维度在 hash 桶的头节点上,那么这里就存在锁的等待问题,其中一共有两种情况:
- 扩容线程 和 put操作线程,对桶头元素为null时的CAS方式新增 Node 的线程自旋重试情况
- 扩容线程 和 put操作线程,对桶头元素不为null时,对桶头 Node 的 synchronized 竞争情况
- ConcurrentHashMap#transfer
Map间的比较:
-
HashMap是无序的,有序的是TreeMap(可按key排升降序)和LinkedHashMap(按插入顺序排序)。
-
HashMap是线程不安全的。在JDK 8下,多线程的put操作会出现数据覆盖的情况,链表的元素插入使用尾插法;在JDK 7下,由于在扩容期间,扩容操作会对新链表使用到头插法,多个线程操作时就可能出现循环链表,在获取该位置的元素时,就会导致应用卡死。但如果设置了初始容量后不会出现扩容操作,那么就不会发生该情况。
-
HashMap 与 Hashtable 之间的区别有那些?
-
HashMap 是线程不安全的,适合在单线程的环境下使用;Hashtable 是线程安全的,可以(但不推荐)在多线程环境下使用
-
HashMap 允许 key-value 为 Null ,Hashtable 不允许 key-value 为 Null
-
HashMap 的 initialCapacity=16 ,扩容规则是大于当前容量的第一个2的n次方;Hash table的 initialCapacity=11,扩容规则为 oldCapacity * 2 + 1
-
两者对 key 求 hash 时运算规则不同,HashMap 的运算规则更加的高效与随机。
-
线程安全的几种Map:
Hashtable<>() 与 Coolections.synchronizedMap(new HashMap<>()) 都是线程安全的,对每个方法添加synchronized修饰,同一时刻,仅允许一个线程对容器进行操作,导致对容器的访问变成串行化的了,故效率低下。
ConcurrentHashMap<>():JDK1.8使用 Synchronized + CAS 保证线程安全;CAS是一个乐观锁,通过判断标记决定这个线程能否操作。效率高,推荐使用。
Map的遍历:
- JDK 8 后建议使用 map.forEach()
map.forEach((k, v) -> {
System.out.println(k + " " + v);
});
- 使用entrySet来遍历map集合
for (Map.Entry entry:map.entrySet()){
System.out.println(entry.getKey()+" : "+entry.getValue());
}














 4040
4040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









