






一、GPU介绍及选型
1、什么是GPU
GPU (Graphic Processing Unit)翻译为图形处理器。图形处理器是一种专门在个人电脑、工作站、游戏机和一些移动设备上运行绘图运算工作的微处理器。 图形处理器是英伟达公司在1999年8月发表NVIDIA GeForce 256绘图处理芯片时首先提出的概念,在此之前,电脑中处理影像输出的显示芯片,通常很少被视为是一个独立的运算单元。
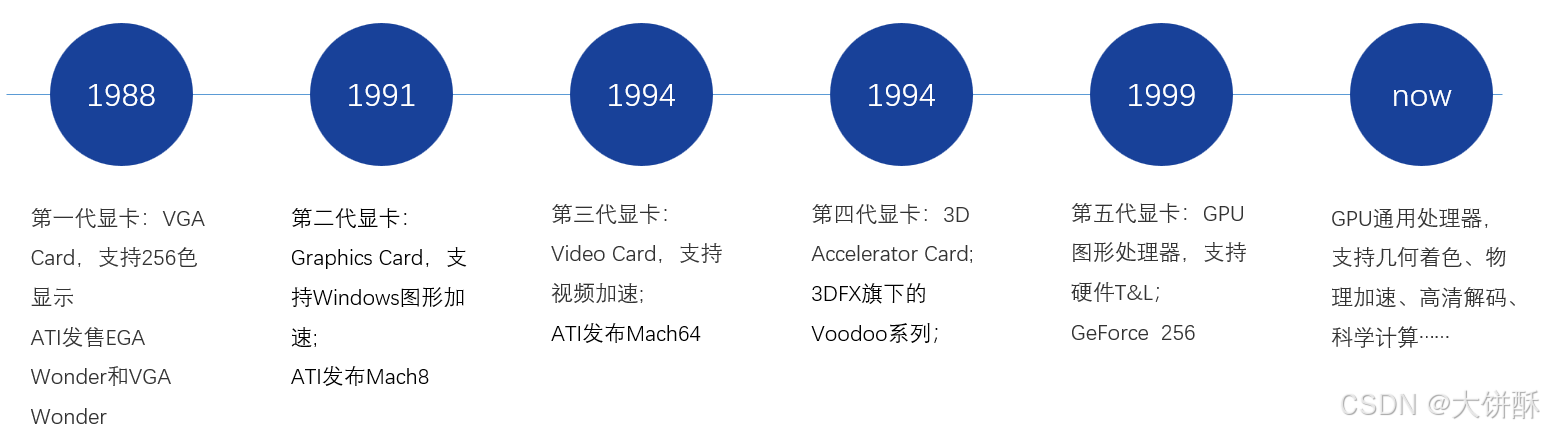
2、GPU产生的背景
冯诺依曼计算机架构的瓶颈
- 曾经,几乎所有的处理器都是以冯诺依曼计算机架构为基础的。
- 该系统架构简单来说就是处理器从存储器中不断取指,解码,执行。
- 瓶颈:内存的读写速度跟不上 CPU 时钟频率。具有此特征的系统被称为内存受限型系统,目前的绝大多数计算机系统都属于此类型。
- 为了解决此问题,传统解决方案是使用缓存技术。通过给 CPU 设立多级缓存,能大大地降低存储系统的压力
- 然而随着缓存容量的增大,使用更大缓存所带来的收益增速会迅速下降,这也就意味着我们要寻找新的办法了。
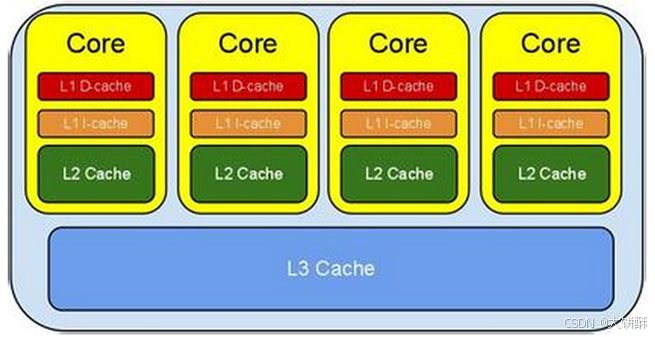
3、CPU 和 GPU 的区别
CPU 单个核心运算能力强,并且内核数量较少(几个到几十个不等),能高效地完成串行任务;而 GPU 则包含非常多核心(数千个),虽然每个核心性能较弱,但凭借核心数多、可并发处理多个任务的优势,在特定场景可提供非常高效的算力。
- CPU 适用于一系列广泛的工作负载,特别是那些对于延迟和单位内核性能要求较高的工作负载。它尤其适合用于处理从串行计算到数据库运行等类型的工作。
- GPU 最初是作为专门用于加速特定 3D 渲染任务的 ASIC 开发而成的。随着时间的推移,这些功能固定的引擎变得更加可编程化、更加灵活。尽管图形处理和当下视觉效果越来越真实的顶级游戏仍是 GPU 的主要功能,但同时,它也已经演化为用途更普遍的并行处理器,能够处理越来越多的应用程序。

4、GPU的关键参数
- 芯片类型:Maxwell, Pascal, Volta,Turing,渐次升级
- CUDA 核心(cores):CUDA 核心的数量决定了 GPU 并行处理能力,在深度学习、机器学习等并行计算类业务下,CUDA 核心多意味着性能好一些。
- Tensor核心数(TMUS):张量核心;“张量”是稍微高级一点的数学概念,是线性代数的延伸,也可以看作对线性代数知识的集大成,简单理解可以是n维数组。
- ROPS:即光栅化处理单元,表示显示GPU拥有的ROP光栅操作处理单元的数量。通常来说:3D图形处理可以分成四个主要步骤,几何处理、设置、纹理和光栅处理,而ROPs就是处理光栅单元。
- 显存容量:其主要功能就是暂时储存 GPU 要处理的数据和处理完毕的数据。显存容量大小决定了 GPU 能够加载的数据量大小。在显存已经可以满足客户业务的情况下,提升显存不会对业务性能带来大的提升。在深度学习、机器学习的训练场景,显存的大小决定了一次能够加载训练数据的量,在大规模训练时,显存会显得比较重要。
- 显存位宽:显存在一个时钟周期内所能传送数据的位数,位数越大则瞬间所能传输的数据量越大,这是显存的重要参数之一。
- 显存带宽:指显示芯片与显存之间的数据传输速率,它以字节/秒为单位。显存带宽是决定显卡性能和速度最重要的因素之一。
5、英伟达显卡的分类
- GeForce
典型型号:1080、2080、2080Ti;定位:消费级游戏卡;价位:~1万
典型型号:Titan X、Titan V、Titan RTX;定位:消费级专业卡;价位:2~3万*注:英伟达禁止在数据中心场景使用GeForce系列显卡
- Quadro
典型的型号:P4000、RTX 6000、RTX 8000;价位:3~4万
定位:工作站,专业图形处理,视频渲染
- Tesla
典型型号:T4:价位:~2万
典型型号:P40、P100、V100;价位:5~7万
典型型号(nvlink接口):V100 SMX2;价位:??(据说很贵)
定位:数据中心级专业卡




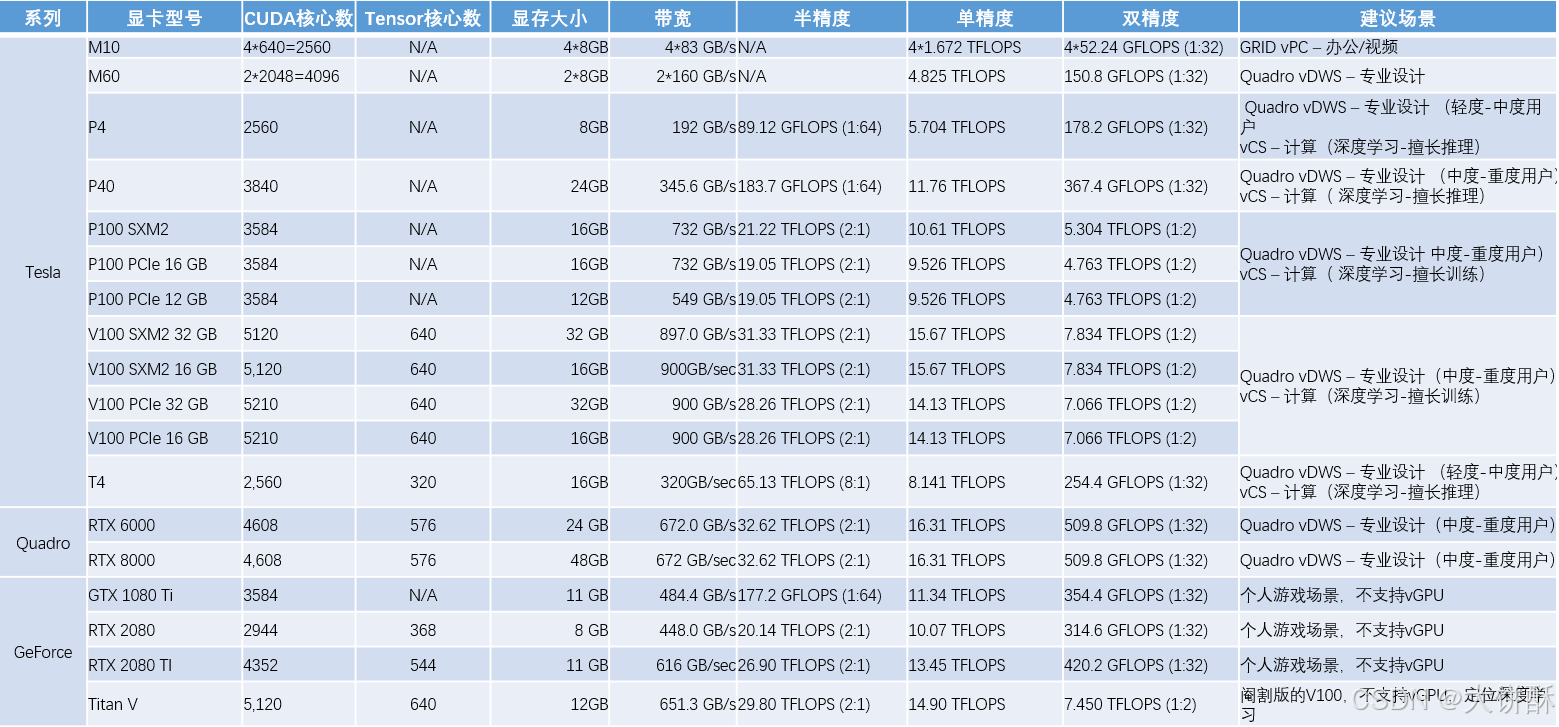
6、英伟达常见显卡对比
7、GPU领域的相关概念
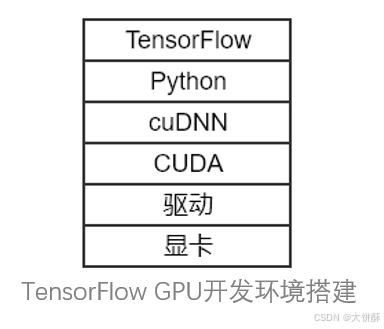
- CUDA全名计算统一设备架构(Compute Unified Device Architecture, CUDA)
东家是英伟达(NVIDIA)。CUDA是专门为通用计算而设计的(Tesla卡甚至连图形输出都没有,专为计算而设计),CUDA采用一种简单的数据并行模型,再结合编程模型,从而无需操纵复杂的图形基元,CUDA使得GPU看起来和别的可编程设备一样。
CUDA对英伟达的意义:显著降低了通用计算编程难度-> 构建了生态护城河
- cuDNN(CUDA Deep Neural Network library)
是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
cuDNN的意义:降低了深度学习的编程难度
8、AI芯片技术路线之争
- FPGA(Field Programmable Gate Array)现场可编程逻辑门阵列
FPGA作为一种高性能、低功耗的可编程芯片,可以根据客户定制来做针对性的算法设计。所以在处理海量数据的时候,FPGA 相比于CPU 和GPU,优势在于:FPGA计算效率更高,FPGA更接近IO。
FPGA不采用指令和软件,是软硬件合一的器件。对FPGA进行编程要使用硬件描述语言,硬件描述语言描述的逻辑可以直接被编译为晶体管电路的组合。所以FPGA实际上直接用晶体管电路实现用户的算法,没有通过指令系统的翻译。可以对硬件编程,实现软件的编程效果;
灵活,但是功耗大,成本高;
- ASIC(Application Specific Integrated Circuit)特殊应用集成电路
ASIC是一种专用芯片,与传统的通用芯片有一定的差异。是为了某种特定的需求而专门定制的芯片。ASIC芯片的计算能力和计算效率都可以根据算法需要进行定制,所以ASIC与通用芯片相比,具有以下几个方面的优越性:体积小、功耗低、计算性能高、计算效率高、芯片出货量越大成本越低。但是缺点也很明显:算法是固定的,一旦算法变化就可能无法使用。目前人工智能属于大爆发时期,大量的算法不断涌出,远没有到算法平稳期,ASIC专用芯片如何做到适应各种算法是个最大的问题,如果以目前CPU和GPU架构来适应各种算法,那ASIC专用芯片就变成了同CPU、GPU一样的通用芯片,在性能和功耗上就没有优势了。
软硬件固化,针对某种特定应用;
功耗低,量产后成本低,但是不灵活;
二、vGPU介绍及选型
1、什么是vGPU
vGPU(虚拟GPU)是一种技术,允许将物理GPU的计算资源虚拟化,以便多个虚拟机可以共享这些资源。
2、vGPU产生的背景
由于加密货币、 AI 等产业的蓬勃发展,加上 GPU 芯片产能不足,以及后来美国针对中国的 GPU 禁运等一系列事件的影响,GPU 卡在市场上非常稀缺,导致其售价非常昂贵,而且供货周期也不稳定。对于有 GPU 需求的企业用户,不但需要思考 GPU 卡的选型,同时需要考虑怎样尽可能高效利用 GPU 资源。通常情况下,将 GPU 资源虚拟化能有效提高资源利用率,目前大多企业也已经习惯将业务部署在虚拟机之上,GPU 与虚拟机的结合可以说是顺理成章的。在服务器虚拟化(或超融合)环境下使用 GPU ,大体分为两种模式:GPU 直通和 vGPU 。
3、GPU直通
GPU 直通主要是利用 PCIe Pass-through 的技术,将物理主机上的整块 GPU 显卡直通挂载到虚拟机上使用,与网卡直通的原理类似,需要主机支持 IOMMU。这种方案有利有弊:
优势
- 通用性好,大部分的 GPU 卡型号都支持直通功能。
- 兼容性好,直通 GPU 在虚拟机中识别的显卡型号与物理显卡一致,直接安装官方驱动,可无损使用 GPU 的各项特性和功能。
- 性能损失小,直通 GPU 性能接近物理机,性能损失一般低于 5%。
限制
- 一张 GPU 卡不能同时直通给多个虚拟机使用,相当于虚拟机独占了 GPU 卡。如果多个虚拟机需要同时使用 GPU,需要在服务器中安装多块 GPU 卡,分别直通给不同的虚拟机使用。
- 拥有直通 GPU 的虚拟机不支持在线迁移。
4、vGPU
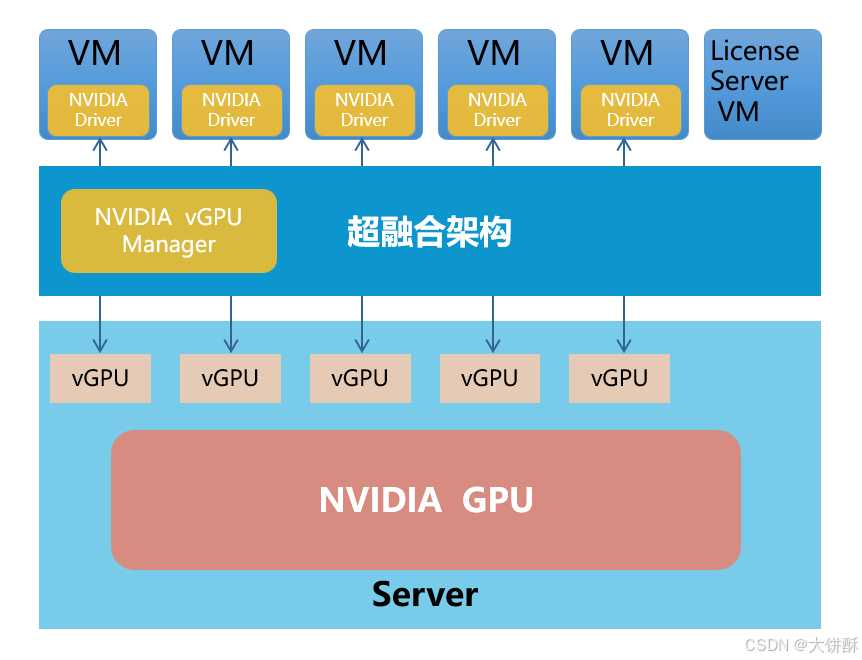
为了应对 GPU 直通带来的限制,vGPU 技术应运而生:将 GPU 卡上的资源进行切分,切分后的 GPU 资源可分配给多台虚拟机使用。vGPU 技术相对 GPU 直通技术要更为复杂,GPU 拥有多种切分方式和不同切分粒度,使得 vGPU 方案有很多种组合。
把一个GPU切分成多个vGPU,给到多个虚拟机使用。
- 服务器硬件需安装NVIDIA支持虚拟化的物理显卡
- 在虚拟化层(超融合架构)内置NVIDIA提供的vGPU管理组件,负责将物理显卡的GPU核心切分成多个虚拟GPU硬件
- 虚拟机安装对应的显卡驱动Driver保证虚拟显卡工作正常
vGPU方案特点:
- 资源占用可视,管理简单
- GPU资源池化,硬件复用更灵活,提高显卡资源利用率
5、vGPU 切分方式
- Time-sliced 切分方式:是按时间切分 GPU,每个 vGPU 对应物理 GPU 一段时间内的使用权。此方式下,vGPU 上运行的进程被调度为串行运行,当有进程在某个 vGPU 上运行时,此 vGPU 会独占 GPU 引擎,其他 vGPU 都会等待。所有支持 vGPU 技术 GPU 卡都能支持 Time-sliced 的切分方式。
- Multi-Instance GPU (MIG)切分方式:将物理 GPU 划分为多个分区(vGPU),vGPU 是一个单独的实例,可以独占访问实例的引擎。多个 vGPU 上运行的进程并行运行。MIG 是基于 NVIDIA Ampere GPU 架构引入的,仅有 Ampere 架构的 GPU 型号才能使用 MIG 方式。MIG 可将 GPU 划分为多达七个实例,每个实例均完全独立于各自的高带宽显存、缓存和计算核心。
6、vGPU系列
NVIDIA 对同一款显卡可支持多种切分的方案,基于不同的切分方案可适应不同用户工作负载类。因此 NVIDIA 将其显卡分为 4 个 vGPU 系列:
| 系列 | 工作负载目的 |
| Q-series | 强调图形处理能力,针对需要 Quadro 技术性能和功能的创意和技术专业人士的虚拟工作站 |
| C-series | 计算密集型服务器的工作负载,针对人工智能、深度学习或高性能计算场景 |
| B-series | 面向商务专业人士和知识工作者的虚拟桌面(如:XenDesktop) |
| A-series | 面向虚拟应用(如:XenApp)用户的应用流式传输或基于会话的解决方案 |
以 NVIDIA A40 这款显卡为例,它可以支持全部 4 种系列的 vGPU 切分方案,而各 vGPU 系列又可以按照切分 GPU 数量分为不同的型号。
| vGPU 型号 | 系列 | 目标用户场景 | 搭配 vGPU 软件许可 |
| A40-48Q/……等 10 种型号 | Q 系列 | 虚拟工作站 | vWS |
| A40-48C/……等 7 种型号 | C 系列 | AI 训练 | vCS 或者 vWS |
| A40-2B/……等 2 种型号 | B 系列 | 虚拟桌面 | vPC 或者 vWS |
| A40-48A/……等 10 种型号 | A 系列 | 虚拟应用 | vWS |
7、vGPU 软件许可
上述提到 vGPU 切分功能是由 GPU 硬件支持的,但虚拟机要真正使用 vGPU 功能还需要搭配相关 NVIDIA GRID vGPU 软件许可才能使用。大致机制是:当带有 vGPU 设备的虚拟机启动后,需从 NVIDIA vGPU License 服务器获取 license,才能正常激活 vGPU 的相应功能,否则无法正常使用;当虚拟机关闭时,license 将被 License 服务器重新回收。
NVIDIA GPU 提供以下的 NVIDIA GRID 授权产品:
- vWS:虚拟工作站(Virtual Workstation)
- vCS:虚拟计算服务器(Virtual Compute Server)
- vPC:虚拟 PC(Virtual PC)
- vApp:虚拟应用程序(Virtual Application)
同时需要注意一点:vGPU 系列与 vGPU 授权许可需要正确搭配才能正常工作。以下是 vGPU 系列与 vGPU 授权许可的搭配关系。
| GRID License 类型 | 支持的 vGPU 类型 | 系列 |
| vApps | Virtual Application | A 系列 |
| vCS | Virtula Compute Server | C 系列 |
| vPC | Virtual PC | B 系列 |
| vWS | Virtual Workstation | Q 系列、C 系列、B 系列 |
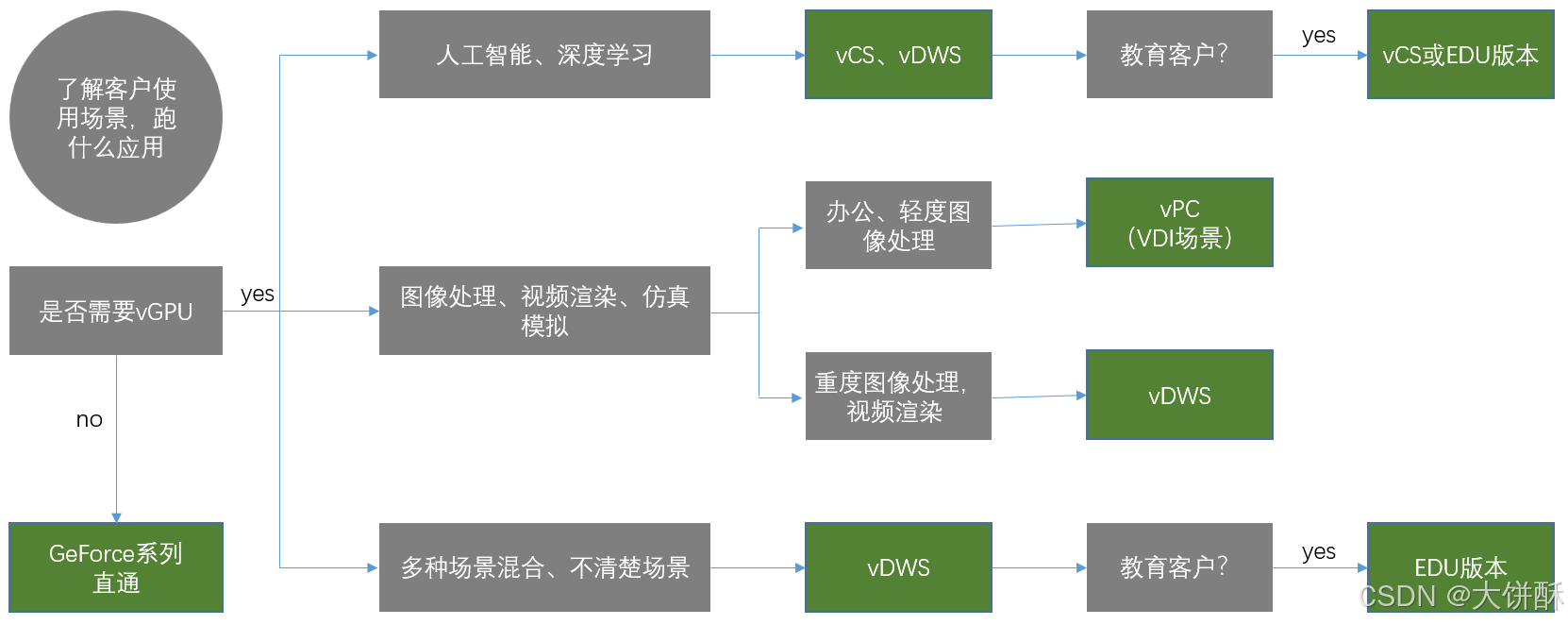
4、vGPU版本选型路径
三、英伟达GPU选型
1、英伟达GPU选型经验分享
- M10、M60 主要用于桌面云、图形设计场景,可以支持多个vGPU
- RTX 6000、RTX 8000 定位用于专业的图形设计,也支持深度学习,支持vCS授权模式
- 专业的用于深度学习的显卡有P4、P40、 T4 、P100、V100
- P4、P40、T4 擅长推理、P100、V100 擅长训练;总体来说,训练需要比推理更强的性能
- T4 突出优势是低功耗,仅75W,一般深度学习显卡功耗在200-300W之间
- 上述几款显卡中,性能最好的是V100;
- GeForce系列 为定位用于个人游戏场景,核心技术与Tesla 系列没有本质的差异,主要的差别是GeForce不支持vGPU方案,只能直通,GeForce 显卡内存不支持ECC,可靠性比Tesla略差
- 因为定价策略的原因,GeForce 比Tesla 会有明显的性价比,很多用户会选择使用GeForce卡做深度学习
- 上述的显卡中 RTX 2080 Ti 是性价比最高的显卡;
- Titan V 是V100的阉割版,与其他GeForce系列显卡略有区别,改卡定位是一款适合“能玩游戏的深度学习计算卡”,在一定程度上,可以认为Titan V是一款价格更便宜的Tesla计算卡;
- 按照NVIDIA的规定,在数据中心做人工智能、深度学习,不允许用游戏卡
2、英伟达GPU性价比
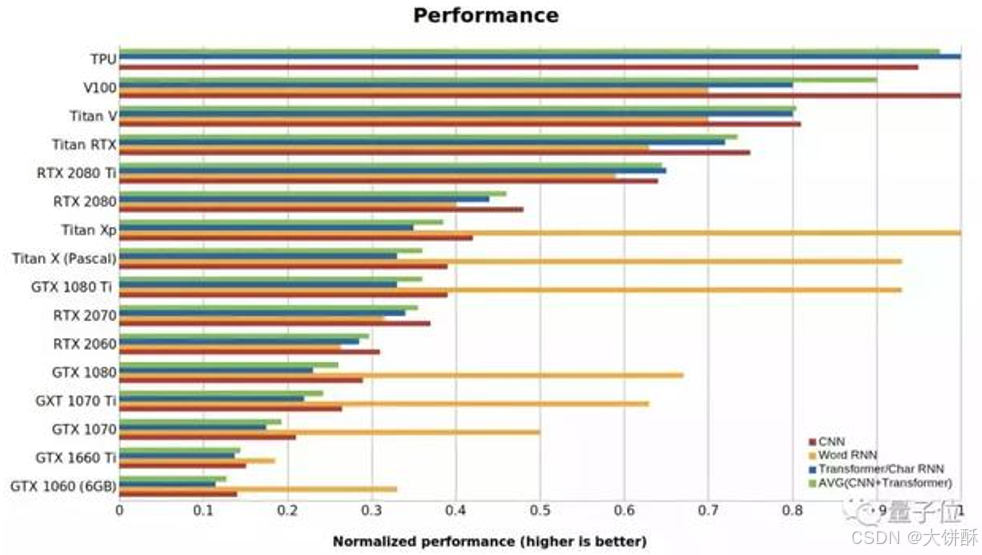
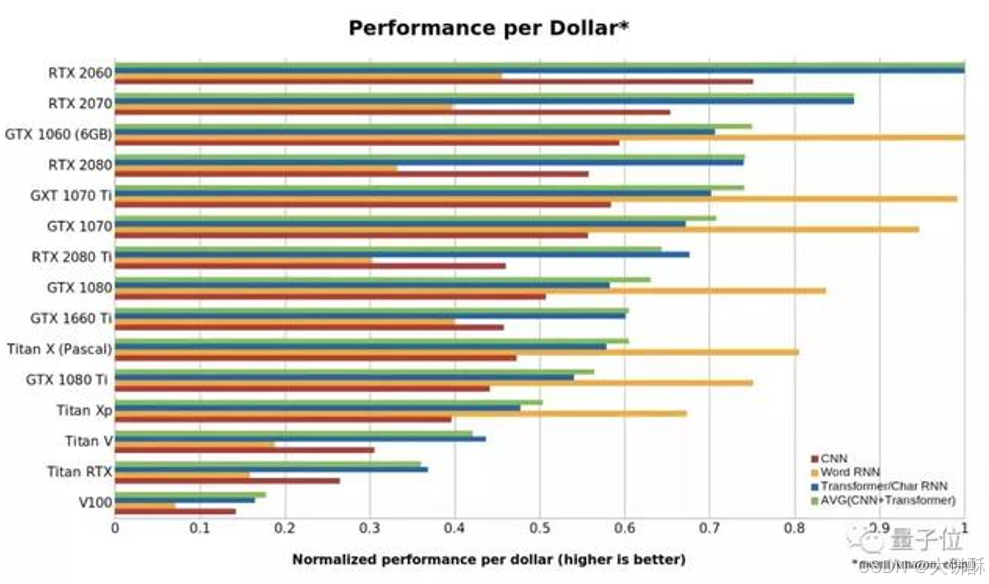
在上面这张图中,数字越大代表每一美元能买到的性能越强。可以看出, RTX 2060比RTX 2070,RTX 2080或RTX 2080 Ti更具成本效益,甚至是Tesla V100性价比的5倍以上。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









