










逃跑计划——MYSQL
1、MYSQL常见命令
1>显示所有数据库:show databases;
2>进入某个库:use 库名称;
3>显示所有的表:show tables 或者 show tables from 库名;
4>查看在那个库里:select database();
5>创建表:create table user( id int,name vaarchar(20));chakan
6>查看表结构:desc 表名称;
7>查看有哪些数据:select * from 表名称;
8>插入数据:insert into 表名称(id,name) values(1,'zhang';
9>修改数据:update 表名称 set name ='li' where id =1;
10>删除数据:delete from 表名称 where id =1;
2、MYSQL语法规范
-
不区分大小写,建议关键字大写,表名、列名小写。
-
每条命令最好用分号结尾。
-
注释:单行:#文字或者-- 文字,多行注释 /* 文字 */
3、DQL语言
-
关键字:去重DISTINCT
-
+号:如果一方为字符则运算时会把字符转为0,再做运算。如果一方为null,则结果为null。
-
不再。。。。之间的。NOT(num>x AND num<y) 。
-
查询第三个字符为a,第五个字符为e的,like '__a_e%'。
-
查询第二个字符为下划线的:like '-\_%' 或者 like '_$_%' ESCAPE '$' 定义转译字符。
-
between and 包括临界值,两个临界值位置不能替换。
-
in 里边不支持通配符。
-
运算符号不能判断NULL值。
-
<=>安全等于,可以判断NULL值,也可以判断普通的值。
-
常见函数:
-
字符函数:LENGTH()获取字符串长度, CONCAT()拼接字符串,UPPER(),LOWER()大小写转换,SUBSTR()截取字符串,INSTR()返回子串第一次出现的索引,如果没有,则返回0,TRIM()去掉空格,TRIM('字符' FROM '字符串')去掉前后的某个字符,LAPD('字符串',10,'*')用指定的长度左填充,RPAD('字符串','10','*')用指定长度右填充。
-
数学函数:ROUND()四舍五入函数,CEIL()向上取整,FLOOR()向下取整,TRUNCATE()截断函数,MOD()取余,
-
日期函数:NOW()当前系统日期+时间,CURDATE()返回当前日期,CURTIME()返回当前时间,通过YEAR(),MONTH()获取年,月。STR_To_DATE()字符转日期,DATE_FORMAT()日期转字符。
-
其他函数:version() 版本号。
-
流程控制函数:IF函数if(2>1,'Y','N')类似三目表达式。CASE()函数,相当于if...else。
-
分组函数SUM(),AVG(),MIN(),MAX(),COUNT(),SUM,AVG处理数值类型,MAX,MIN,COUNT处理任何类型,SUM和AVG忽略NULL值,MAX,MIN忽略NULL值。COUNT忽略NULL值。在MYISAM引擎下COUNT(*)效率高,在INNODB引擎下COUNT(*) 和COUNT(1)效率差不多。
-
-
联合查询UNION(),将多个结果合并为一个。默认去重,UNINO ALL不去重。
4、DML语言
-
INSERT 插入语句。
-
UPDATE更新语句
-
DELETE删除语句,TRUNCATE 删除没有返回值,效率高点,不能回滚事物,主键自增从0开始。
5、DDL语言
-
库的管理
-
表的管理
修改列名:ALTER TABLE 表名CHANGE COLUMN 旧名 新名 类型。
修改列的类型约束:ALTER TABLE 表名 MODIFY COLUMN 列名 类型。
添加新列:ALTER TABLE 表名 ADD COLUMN 列名 类型。
删除列:ALTER TABLE 表名 DROP COLUMN 列名。
修改表名:ALTER TABLE 表名 RENAME TO 新表名。
删除表:DROP TABLE 表名。
表的复制:仅仅复制表结构:CREATE TABLE COPY LIKE 表名。
-
数据类型:char()固定长度、比较耗费资源,效率高,varchar()不定长度,节省资源,效率低。
-
常见的约束:
六大约束:NOT NULL 非空约束。
DE FAULT 默认值
PRIMARY KEY 主键,保证非空和唯一性。
UNIQUE 唯一性。可以为空。
CHECK 检查约束 mysql不支持。
FOREIGN KEY 外键。
标识列:AUTO_INCREMENT 伴随数值型使用,可以有多个,不一定和主键搭配使用。但必须是个key.
6、TCL语言
-
事务的ACID属性:原子性(Atomicity)事务是一个不可分割的工作单位事务中操作要么都发生,要么都不发生。一致性(Consistency)事务必须使数据从一个状态变换到另一个一致性状态。隔离性(Isolation)一个事务的执行不能被其他事务干扰。持久性(Durability)事务一旦被提交,是对数据库的永久性改变。
-
开启事务的步骤:
1》set autocommit =0; start transaction;(可选的)
2》提交事务:commit;
3》回滚事务:rollback;
-
隔离级别:查看隔离级别:select @@tx_isolation ;设置隔离级别:set session transaction isolation lavel 隔离级别;隔离级别分类:1、read uncommited 可能会出现幻读、脏读,不可重复读。2、read commited 可能会出现幻读,或者不可重复读。3、repeatable read 可能会出现幻读,幻读主要是针对插入的。4、serializable 串行化,在这个级别事务持续期间,禁止其他事务对该表进行增删改操作。所以导致性能很低。
-
视图:虚拟表,和普通表一样使用,创建语句:CREATE VIEW 视图名 AS SELECT .....。查看视图:DESC 视图名。对视图的增删改会影响原表的增删改。包含分组、关联、常量等的视图不能进行更新操作。
-
DELETE 和TRUNCATE 在事务使用时的区别:TRUNCATE 在事务中不支持回滚。
-
变量:查看变量:SHOW GLOBAL VARIABLES, 给变量赋值:SET GLOBAL 变量名=“值”,SET @@GLOBAL.变量名=“值” 局部变量:声明 DECLARE 变量名 类型,局部变量用在订一他的BEGIN...ENG之间。
-
存储过程:一组预先编译好的SQL语句的集合,减少编译次数和数据库的连接次数。提高了效率。
1》创建语法:CREATE PROCEDURE 存储过程名 (参数模式,参数名,参数类型)
BEGIN
存储过程(一组合法的SQL语句)
END
2》参数模式:IN:该参数可以作为输入,需要调用方传过来
OUT:该参数可以作为输出,也就是该参数可以作为返回值
INOUT:该参数既可以作为输出,也可以作为输入,也就是既需要传 入,也可以输出。
3》如果存储主体中只有一句SQL,则BEGIN ..END 可以省略。存储过程中的每一条 语句末尾都必须加分号。末尾可以使用DELIMITER重新设置。
4》调用过程:CALL 存储过程名(模式,参数,类型);
5》案例:CREATE PROCEDURE(IN username varchar(20).OUT nameInfo varchar(20))
BEGIN
SELECT NAME INTO nameInfo
FROM 表名
WHERE NAME =username
END $
备注:SELECT DATEDIFF(参数一,参数二)如果参数一比参数二大,返回一个 正数,相反则返回负数。
6》存储过程删除:DROP PROCEDURE 存储过程名。
7》查看存储过程:SHOW CREATE PROCEDURE存储名。
-
函数:一组预先编译好的SQL语句的集合,减少编译次数和数据库的连接次数。提高了效率。
1》创建函数:CREATE FUNCTION 函数名(参数列表)RETURNS 返回类型
BEGIN
函数体
END
2》调用函数:SELECT 函数名(参数列表)
3》查看函数:SHOW CREATE FUNCTION 函数名。
4》删除函数:DROP FUNCATION 函数名。
-
存储过程和函数的区别:存储过程可以有0个或多个返回值,函数有且仅有一个返回值。
-
流程控制结构:
1》顺序结构:从上往下执行
2》分支结构:从多条路径选择一条执行
①if函数if(表达式,返回值一,返回值二)
②case 变量 | 表达式 | 字段
when 要判断的值 then 返回的值1.
when 要判断的值 then 返回的值2.
else 返回值 0
end case.
③if 条件1 then语句1
elseif 条件2 then语句2
else 语句n
end if;
3》循环结构:循环执行同一条语句
① while 循环条件 do
循环体;
end while;
②while(循环条件){
循环体
}
③repeat:先执行后判断。
④loop:没有循环条件,死循环。
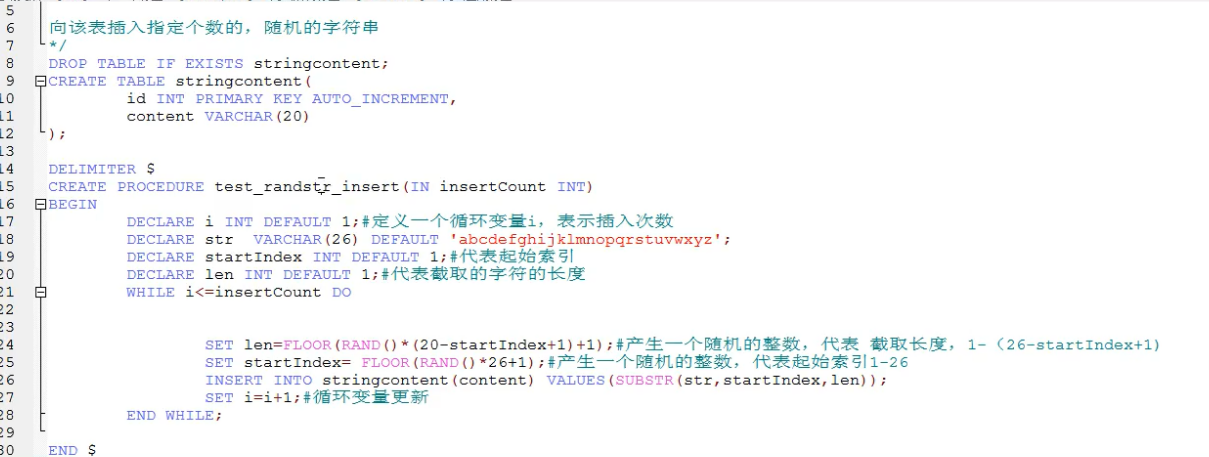
7、MYSQL架构介绍
-
MYSQL 安装查询 rpm -qa | grep -i mysql
-
用CAT 命令查看用户和用户组
-
设置开机自启:chkconfig mysql on.
8、索引优化分析
-
性能下降sql慢
-
执行时间长
-
等待时间长
-
索引:index 是一种数据结构,排好序的快速查找数据结构。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构,就是索引。
-
Explain + sql 语句: Explain 能干嘛:
1》表的读取顺序
id 相同:执行顺序由上至下。
id不同:如果是子查询,id的序号会自增,id的值越大,优先级越高,优先被执行
id相同不同同时存在
2》数据读取操作的操作类型
select_type:
a:simple:不包含自查询和union语句。
b:primary:包含复杂的子查询,最外层的查询则被标记为primary
c:subquery:子查询被标记为subquery
d:derived:把生成的零时表标记为drived
e:union:在第二个select之前出现union
3》那些索引可以使用
possible_keys:显示可能应用到这张表中的索引
4》那些索引被实际使用
key:实际被应用的索引
5》表之间的引用
6》每张表有多少张被优化器查询
7》访问类型排序
从最好到最差依次是:system>const>eq_ref>ref>range>index>all
system:只有一条数据,相当于系统表
const:常用于比较主键级别的。
eq_ref:唯一性索引扫描或者主键扫描
ref:非唯一性索引扫描,返回匹配某个值的所有行。
range:只检索指定范围的行,使用一个索引来选择行,
index:只便利索引树
all:遍历全表。
-
索引失效(应该避免的):
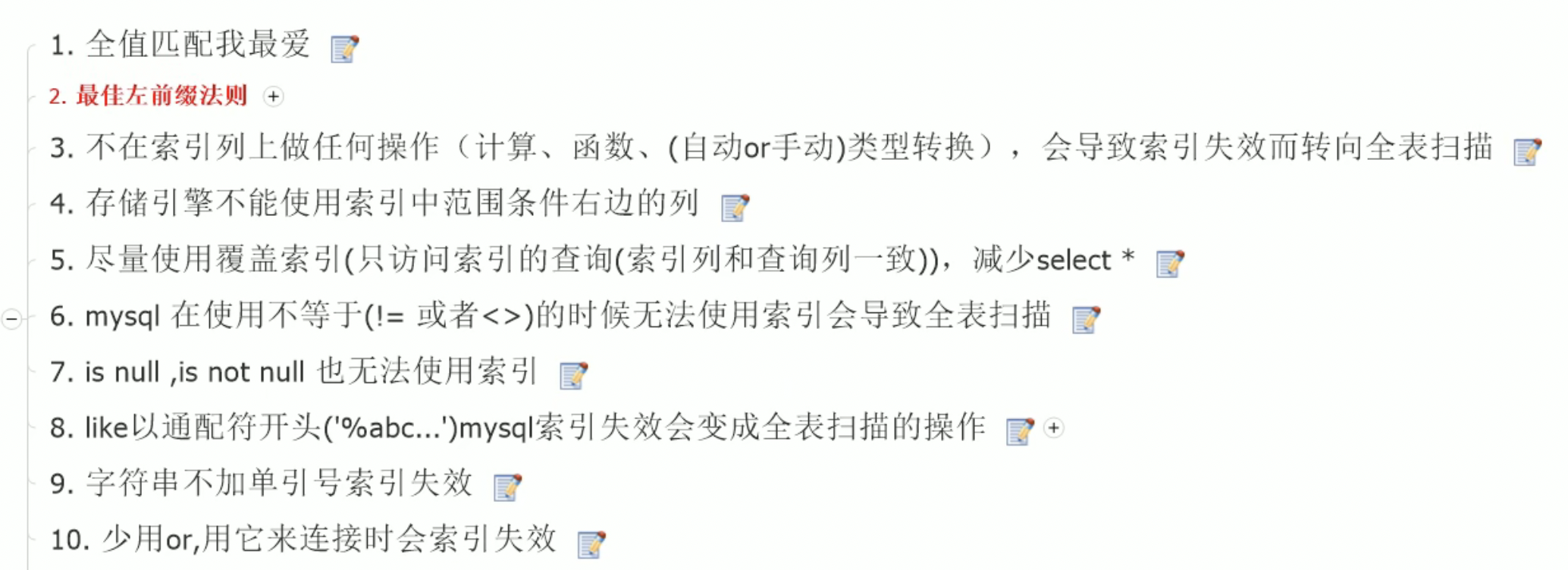
多个字断的的联合索引,查询从索引的最左侧开始,不能跳过中间的索引。
9、查询截取分析
分析: 1、把跑的慢的服务的sql抓取出来
2、explain +慢sql分析。
3、show profile:查看sql在mysql服务器上的执行细节和生命周期
4、数据库服务参数调整
-
小表驱动大表
-
order by 排序:尽量使用index排序,避免使用fileSort排序

-
group by: 先分组后排序,也是适用索引最佳左前缀。
-
慢查询日志分析:mysql有个慢查询日志,一般不建议开启。因为写日志会影响性能,
show variables like "%slow_query_log" 设置阈值 long_query_time.
日志分析工具:MySQLdumpshow
5、show profile:mysql 提供可以用来分析当前会话中语句执行的资源消耗情况。挣断命令:show profile cpu,block io for query
10、MYSQL锁机制
-
锁的分类:读锁(共享锁)和写锁(排他锁),行锁(偏写)和表锁(偏读)。
-
表锁(MYISAM):手动增加表锁:lock table 表名 read(write),查看锁:show open tables,释放锁:unlock tables
-
加了读锁后,除了读自己,其他的什么都不能干。其他的用户可以读他和读其他,但是修改和插入操作是阻塞等待。
-
加了写锁:自己可以读写锁定的表,但是不能读其他的表。其他用户可以查询是阻塞等待。
-
MYISAM的读写锁调度写优先,所以myisam不适合做写为主的表的引擎。
-
行锁(innoDB):
-

-
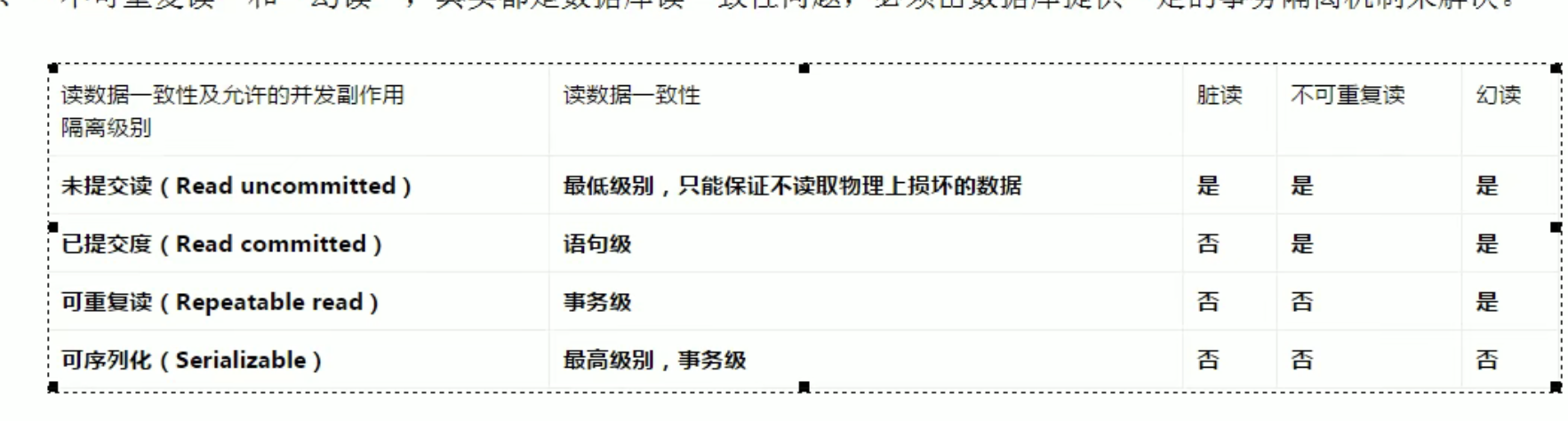
-
行锁:读己只锁写
-
间隙锁的危害:当我们用范围条件而不是相等条件检索数据,innoDB会给符合条件的已有记录的索引项加锁,对于键值在条件范围内但并不存在的记录叫做“间隙”(GAP)。
-
如何锁定一行:命令begin;锁定一行,commit;结束锁定。
11、主从复制
-
主从复制的原理:slave会从master读取binlog来进行数据同步。mysql的复制是异步串行化的。
-
主从复制常见配置:1、数据库版本一致,在同一网段,主从机关闭防火墙,主机上建立账户并授权slave
12、Mycat读写分离、分库分表
-
mycat数据库中间件:读写分离、数据分片(垂直+水平拆分)、多数据源整合。
-
mycat原理:拦截
-
分库:选择分库的表,然后配置schema.xml文件。
-
分表:
-
全局序列化:推荐使用数据库方式















 1388
1388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









