






全球AI加速技术之前言:
在数据洪流汹涌而至的数字时代,传统计算架构逐渐暴露出瓶颈。NVLink/NVSwitch 互联技术宛如一道划破天际的闪电,以颠覆性的姿态震撼登场。它不是简单的技术迭代,而是一场彻底的革命,以惊人的速度和强大的性能,打破旧有束缚,为高性能计算开启一扇通往巅峰的荣耀之门,让我们一同见证这一技术传奇的崛起。
一:顶尖的GPU 互联技术泛化分类:
在深度学习训练过程中,随着 GPU 算力的迅猛提升,GPU 之间的数据传输速度逐渐成为影响训练效率的关键瓶颈。从网络架构的角度来看,可以将其划分为以下几个方面:
1:GPU 卡间互联

2:GPU 服务器件互联
二:本文单机多 GPU 卡间互联:构建高效通信的单机本地简化后的算力基石
在高性能计算与深度学习领域,如何将多张 GPU 高效互联,释放其协同计算潜力,是提升整体性能的核心命题。无论是应对复杂的 AI 模型训练,还是处理海量数据的科学计算,GPU 间的通信效率都直接决定了系统的算力上限。从技术实现的角度,单机内 GPU 卡间互联方案可分为以下四大类:
1. PCIe 直连
传统而经典的互联方式,通过 PCIe 总线实现 GPU 与 CPU 的直接连接。适合中小规模任务,但在高带宽需求场景下略显乏力。
2. PCIe Switch 互联
借助 PCIe 交换机扩展多 GPU 的通信能力,提供更灵活的拓扑结构。尽管解决了扩展性问题,但受限于 PCIe 的带宽与延迟,仍难以满足极致性能需求。
3. NVLink 互联
高速互联的革新者,通过点对点直连大幅提升 GPU 间的数据传输速度,彻底突破 PCIe 的带宽瓶颈,为高性能计算注入强劲动力。
4. NVSwitch 全互联
技术巅峰的代表作,基于 NVLink 构建全互联架构,允许多张 GPU 在同一节点内实现无阻塞、无缝的高速通信。无论是带宽、延迟还是扩展性,NVSwitch 都将单机多 GPU 的协作效率推向了全新高度。
每一种互联技术都有其独特的优势与适用场景,而 NVSwitch 更是重新定义了单机多 GPU 的通信极限,为未来 AI 和科学计算铺就了一条通往无限可能的道路。
三:PCIe 直连
PCIe 直连是一种将 GPU 直接连接到 CPU 的技术路线,与通过 PCIe Switch 连接不同。但在实际应用中,PCIe 直连的弊端逐渐显现,其中最突出的就是 PCIe lane 总量紧缺问题极为显著。
以 inter 平台 4U 8 卡 AI 服务器为例:
1:2颗第三代 inter CPU,每颗 inter CPU 64 个 PCIe lane,总计 64x2 lane。
2:2 颗 CPU 之间使用 3 条 xGMI 互联,占用 32x3 lane,剩余 160 lane 给到 NIC、GPU 等 I/O 外设设备
3:每张 GPU 占用 16 lane,8 卡 GPU 总计 16x8 lane,剩余 32 lane。
4:剩余的 32 lane 可供其他 NIC、RAID 卡使用。

四:PCIe Switch 互联
在上述 PCIe 直连拓扑里,PCIe lane 数量明显不足。为缓解这一困境,新的 PCIe 标准引入了 PCIe Switch 模块。在主板设计上,与 2 个 CPU Socket 分别对应的,是采用 2 个 PCIe Switch 芯片来实现信号的扩展,从而优化整个系统的 PCIe 资源分配与连接效率。
1:PCIe Switch 互联:性能与架构的权衡
在 PCIe Switch 互联方案中,多个 GPU 通过 PCIe 交换机直接与 CPU 连接。其工作原理是,GPU 发出的信号首先传输至 PCIe Switch,随后由交换机将数据分发至对应的 CPU 进行调度处理。然而,这种架构不可避免地引入了额外的网络延迟,成为系统性能的瓶颈。信号的中转和调度过程不仅增加了通信开销,还限制了整体计算效率,尤其在高带宽需求场景下,这种局限性更加显著。
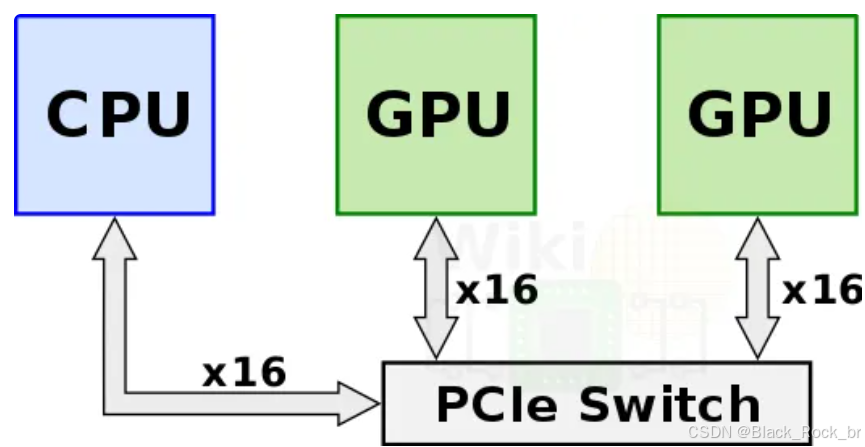
在PCIe直连拓扑中,PCIe lane的数量显然存在一定的局限性。为了解决这一问题,新的PCIe标准中引入了PCIe Switch模块。PCIe Switch模块在主板上与2个CPU Socket一一对应,采用2个PCIe Switch芯片来进行信号扩展。这种设计巧妙地利用了信号放大的原理,使得每个扩展芯片能够额外扩展出5个x16的插槽,从而显著增加了可用的PCIe插槽数量。通过这种方式,PCIe Switch有效地缓解了CPU直连时PCIe lane数量不足的问题,为系统提供了更灵活的扩展能力和更强大的连接性能。
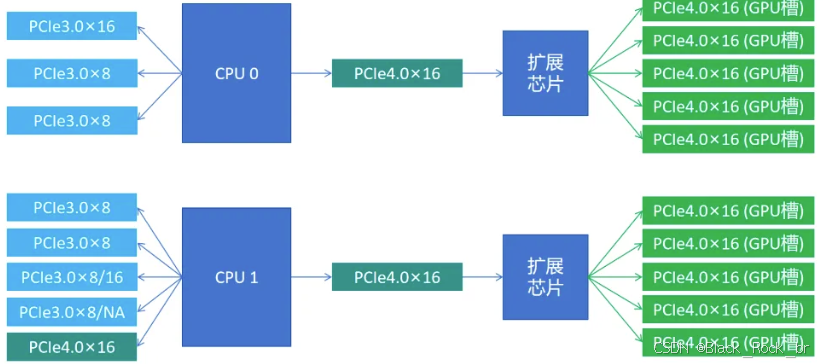
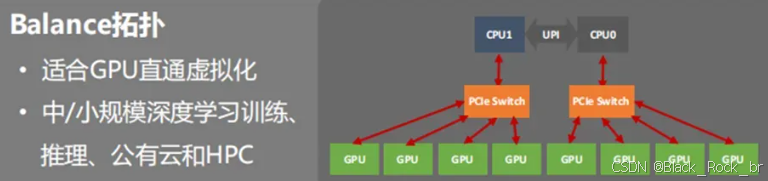
通过 PCIe Switch,服务器可以实现 CPU-GPU、GPU-GPU 之间的连接,同时也出现了 3 种连接模式,即:balance、common、cascade 拓扑。
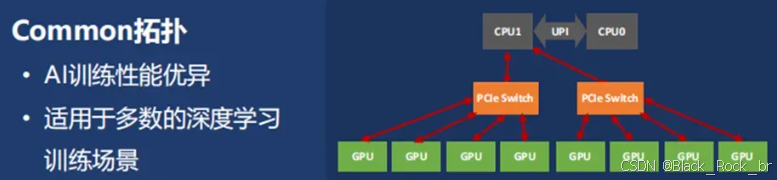

尽管 PCIe 的双向带宽正以每代翻倍的速度快速增长(例如,PCIe 5.x x16 已可提供高达 126GB/s 的双向带宽),但与 GPU 算力对带宽的爆炸式需求相比,其速度仍然显得捉襟见肘,成为性能提升的瓶颈。
在 PCIe Switch 互联拓扑里,GPU 间通信链路可能为 GPU0→Switch0→CPU0→CPU1→Switch1→GPU7,这种链路通信会存在延迟,更适合对信号效率要求不高、注重性价比的场景,比如推理、云计算等。
五:NVLink 互联
1:NVIDIA 推出的 NVLink 技术,目的是突破 PCIe 互联在带宽性能上的限制,让 GPU 芯片间能实现高带宽、低延迟的数据传输。
2: NVLink 互联方式是让 GPU 通过 NVLink 直接连通,无需借助 PCIe Switch。
3:NVLink 是点对点的高速互连技术,单条 NVLink 是全双工双路信道,可直连 2 个 GPU,且每个 GPU 能凭借多条 NVLink 接口连接多个 GPU。
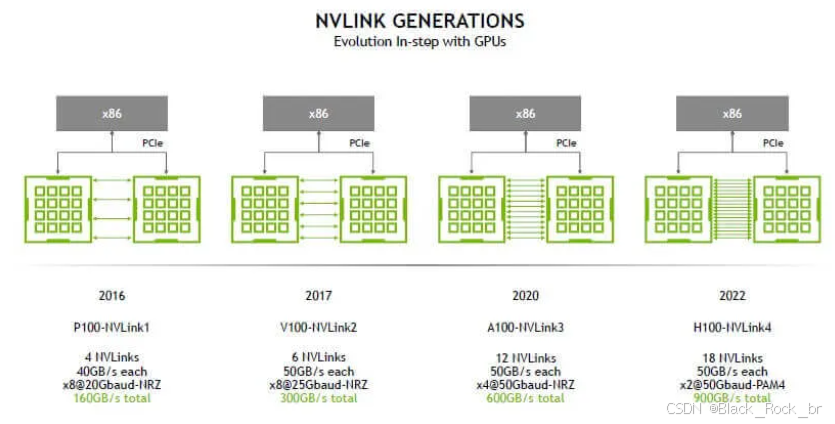
六:NVLink 4.0、NVSwitch 3.0 与 DGX H100
2022 年,发布了 NVLink 4.0、NVSwitch 3.0 以及 H100 GPU。
-
每张 H100 具有 18 条 Link 接口,单 Link 双向 50GB/s(400Gb/s),单卡满带宽 900GB/s。
-
由于 Link 数量的增加,NVSwitch 2.0 的 Port 数量也增加到了 64 个,单 Port 双向 50GB/s。
DGX H100 系统由 8 张 H100 与 4 颗 NVSwitch 芯片组成,如下图所示。
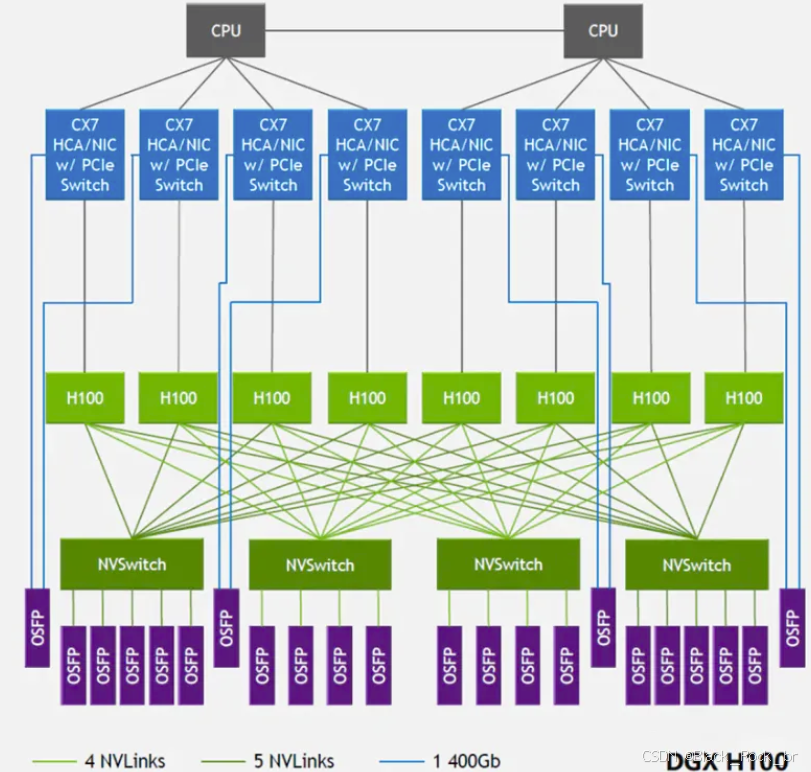
值得注意的是,从 NVSwitch 3.0 开始 NVIDIA 真的将 NVSwitch 芯片拿出来做成了交换机,是真正的 “NVLink Switch”,用于实现跨主机连接 GPU 设备。NVSwitch 3.0 集成了多个 800G OSFP 网络光模块,使得可以连接到 NVLink Switch。
总结:
在高性能计算与深度学习领域,GPU 间的高效互联已成为释放算力潜力的核心关键。传统 PCIe 互联虽不断演进,但仍难以满足现代 AI 模型和科学计算对带宽与延迟的极致需求。NVLink 和 NVSwitch 的出现,彻底颠覆了这一局面。通过提供超高带宽、超低延迟的点对点及全互联架构,它们不仅撕碎了传统互联技术的瓶颈,还为多 GPU 协同计算铺平了道路。
NVLink 实现了 GPU 间高速直连,而 NVSwitch 更进一步,构建起无阻塞的全互联网络,让多张 GPU 在单机内无缝协作,极大提升了通信效率和系统性能。无论是应对复杂的深度学习训练,还是推动尖端科学研究,NVLink/NVSwitch 都以其卓越的技术优势,成为重铸高性能计算辉煌的基石。
未来,随着 AI 和 HPC 需求的不断升级,NVLink/NVSwitch 必将继续引领行业变革,开启算力新时代的无限可能。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









