







 本文介绍了矩阵分解在推荐系统中的应用,探讨了基于内容的过滤和协同过滤方法,重点阐述了矩阵分解的基本模型及其优化,如添加偏置、处理隐式反馈和时间动态。实验表明,矩阵分解模型能有效提升推荐系统的准确性。
本文介绍了矩阵分解在推荐系统中的应用,探讨了基于内容的过滤和协同过滤方法,重点阐述了矩阵分解的基本模型及其优化,如添加偏置、处理隐式反馈和时间动态。实验表明,矩阵分解模型能有效提升推荐系统的准确性。
点击上方蓝字“小透明的推荐之路”一起学习吧
MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS
前言(Foreword)
本篇文章是由来自Yahoo Research的Koren等人在2009年发表在IEEE Computer Society期刊上。矩阵分解用于推荐系统最早是 Simon、Funk等人在 Netflix比赛的评分任务,提出了Funk-SVD算法。之后的研究改进了矩阵分解, 并且提供了很多变种,例如本文。
背景(Background)
由于信息过载问题,现代用户被选择给淹没。给用户匹配最合适的物品能够提高用户的满意度和忠实度。因此,很多的零售商开始对可以给用户提供个性化推荐的推荐系统感兴趣。推荐系统在一些娱乐产品如电影、音乐、商品交易等有了用武之地。
总的来说,推荐系统基于两个策略(当时):基于内容的过滤方法(创建一个轮廓(profile)来描述用户或者物品的本质)和协同过滤方法。
基于内容的过滤(Content Filtering Approach)
例如,一个电影轮廓可以包括关于它的类型、参与的演员、它的票房的受欢迎程度,等等。用户资料可能包括人口统计信息或在适当的调查表上提供的答案。这些轮廓允许程序将用户与匹配的产品关联起来。当时,一个非常成功的内容过滤是the Music Genome Project,它被应用在Pandora.com。
协同过滤(Colaborative Filtering)
只依赖于过去的用户行为,例如,以前的交易或物品的评级,而不需要创建显式的轮廓配置信息,这种方法被称为协同过滤,这是Tapestry的开发人员创造的一个术语,Tapestry是第一个推荐系统。协同过滤分析用户之间的关系和产品之间的相互依赖关系,以识别新的用户-物品的关联。协同过滤的一个主要优点是它是领域自由的,它可以解决数据方面的问题,而这些问题通常很难用内容过滤来分析。尽管协同过滤通常比基于内容的技术更准确,但它存在所谓的冷启动问题,因为它无法处理系统的新产品和用户,在这方面,内容过滤是优越的。
协同过滤两个主要的方法是:基于邻域方法和隐语义模型。
基于邻域的方法(Neighborhood Methods )
基于邻域方法由于计算的关系不同(物品/用户)被分为基于物品的协同过滤和基于用户的协同过滤。
面向物品的方法基于同一用户对“邻近”物品的评分来评估用户对某个物品的偏好。一个物品的邻居是同一个用户打出相似评分的其他物品。比如电影《拯救大兵瑞恩》。它的邻居可能包括战争片,斯皮尔伯格的电影,汤姆汉克斯的电影,等等。为了预测某个特定用户对《拯救大兵瑞恩》的评分,我们会寻找该用户实际评价的电影的最近邻居。
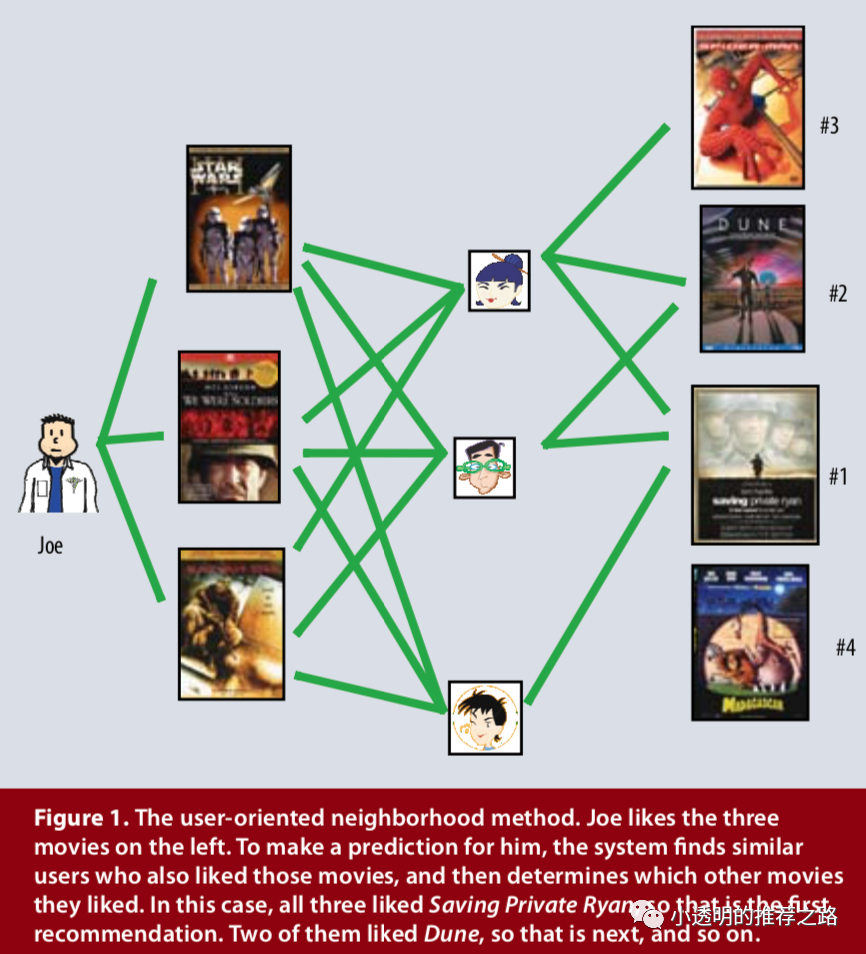
面向用户的方法是去找到志同道合(相似)的用户,这些用户可以互相补充各自的评分,如下图所示。
隐语义模型(Latent Factor Model)
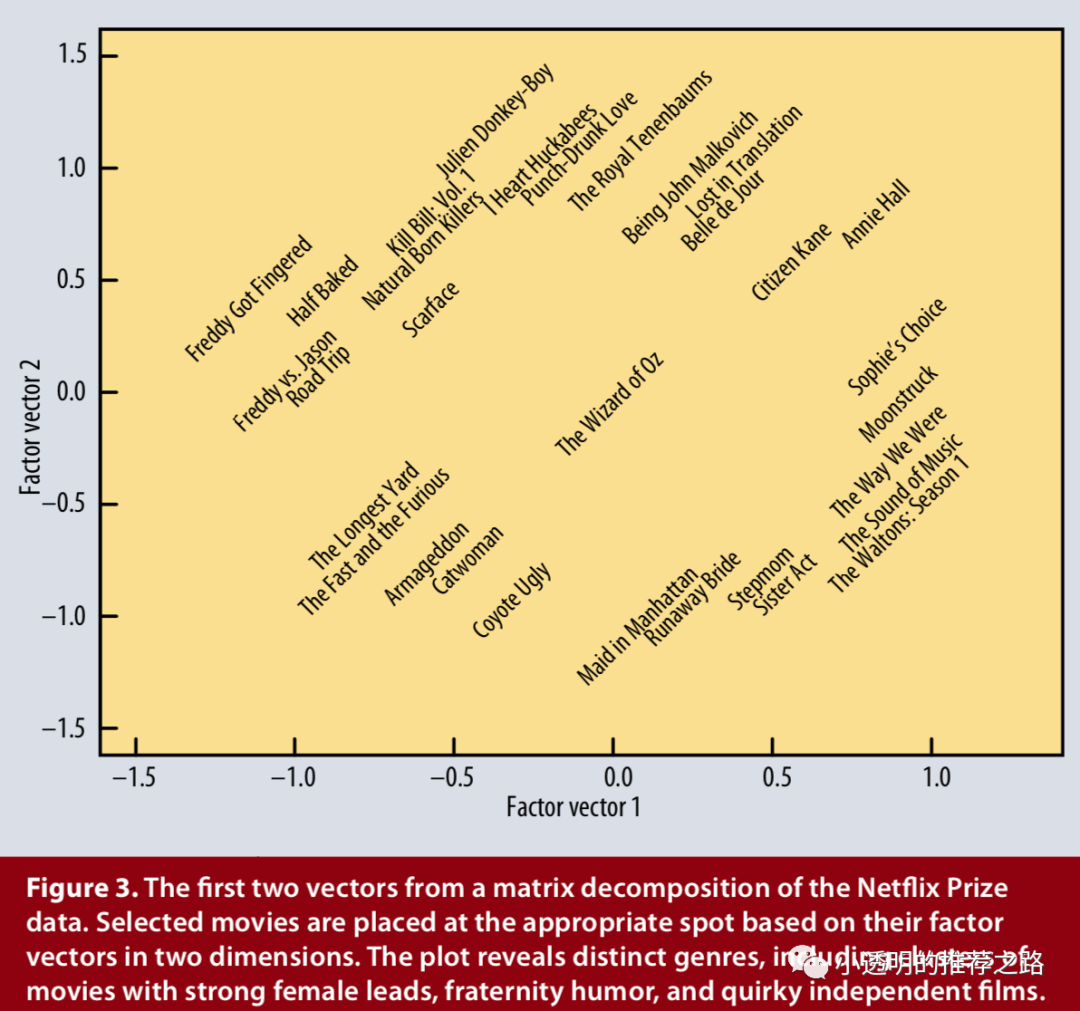
隐语义模型通过根据评分模式推断出的20到100个因子来表征物品和用户,从而试图解释评分。对于电影来说,发现的因素可能会衡量明显的维度,例如喜剧与戏剧,动作量或对儿童的定向;不太明确的尺寸,例如角色发展的深度或古怪成都;亦或者是完全无法解释的尺寸。对于用户来说,每个因素都会衡量用户对在相应电影的喜欢程度。
下图以二维的简化示例说明了这种想法。考虑两个假设维度,分别是面向女性和男性(x轴)以及严肃与逃避(y轴)。该图显示了这两个维度上可能有几部著名电影和一些虚拟用户。对于此模型,相对于电影的平均评分,用户对电影的预测评分将等于电影和用户在图表上位置的点积。例如,我们希望Gus 喜欢Dumb和Dumber,讨厌The Color Purple,并且将《勇敢的心》(Braveheart)评为平均水平。
矩阵分解方法(MatRix Factorization Methods)
一些最成功的潜在因素模型的实现是基于矩阵分解的。在其基本形式中,矩阵分解通过从物品评分模式中推断出的隐向量来表征物品和用户。推荐系统依赖于不同类型的输入数据,这些输入数据通常放置在一个矩阵中,其中一个维度表示用户,另一维度表示物品。
输入的数据集分为两类:
最方便的数据是高质量的显式反馈,其中包括用户对其物品兴趣的显式输入。例如,Netflix收集电影的星级评分。我们将明确的用户反馈称为评分。通常,显式反馈包含一个稀疏矩阵,因为任何单个用户都可能只对可能物品的一小部分进行了评分。
当没有明确的反馈时,推荐系统可以使用隐式反馈来推断用户的偏好,隐式反馈通过观察用户的行为(包括购买历史,浏览历史,搜索模式甚至鼠标移动)来间接反映意见。隐式反馈通常表示事件的存在或不存在,因此通常由密集填充的矩阵表示。
最基础的矩阵分解模型(Basic Matrix Factorization Model)
矩阵分解模型将用户和物品都映射到维数为 的联合潜在因子空间,并将用户和物品的交互建模为两者之间的内积操作。
定义:对于每一个物品 表征为隐向量 ,每一个用户 表征为隐向量 ,内积 代表了物品 和用户 之间的交互,即用户 对物品 特性的兴趣程度(评分),用户 对物品 的真实评分为 ,评分估计可被公式化为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1560
1560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









