









一、主要内容介绍
1. 问题背景
对于高分辨率的图像,如何在高推断速度的情况下,保证推断精度呢?
- U型网络的分割效果不错,但是计算量较大;
- 一些方法通过减小输入图像的尺寸或者裁剪掉多余的通道来提高推断的速度,但是会损失边界部分的细节以及对于小目标识别效果不好;
- 浅层的网络削弱了特征的辨别能力。
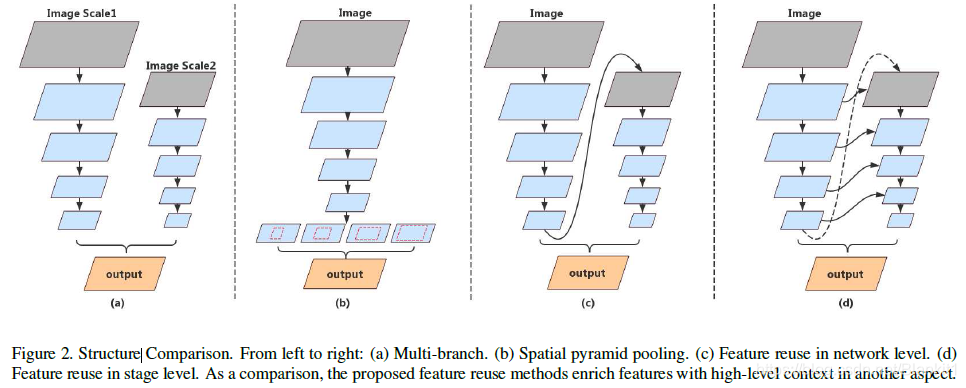
- 针对这些问题,有人提出将空间细节和上下文信息结合在一起的多分支框架(Figure 2(a))。然而,高分辨率图像上的附加分支限制了速度,分支之间的相互独立性限制了模型学习能力。
- SPP(Spatial Pyramid Pooling)(Figure 2(b))会增加高层的特征,同时也会增加计算量。通过最后的输出增加特征图,这样会缺少前面层保留的图像语义信息。
为了提高模型的学习能力,以及增大感受野,特征重利用(feature reuse) 是个不错的方法。文章提出的网络结构如图Figure 2(d).通过子网络聚合(sub-network aggregation)和子状态聚合(sub-stage aggregation)来重利用特征。
2. 文章贡献点
文章提出了一种深度信息整合网络(DFANet)用于实时语义分割。
主要有三个贡献点:
- 采用轻量级的网络作为基本骨架(backbone)
- 子网络聚合——网络级联。
- 子状态聚合。将不同骨架间的相应状态聚合。
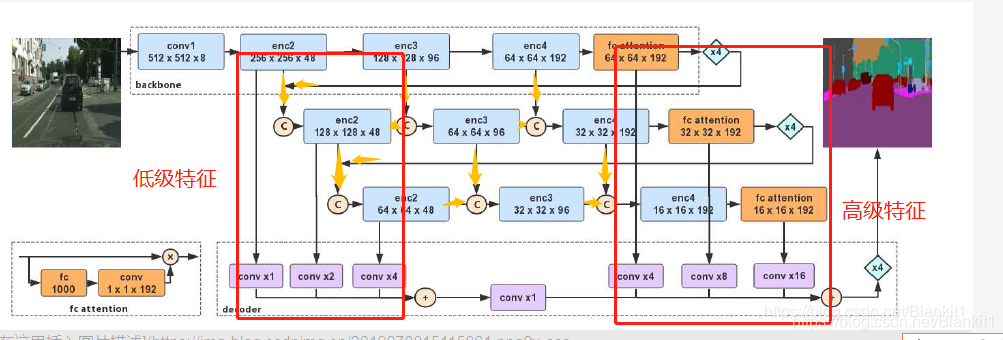
二、网络结构

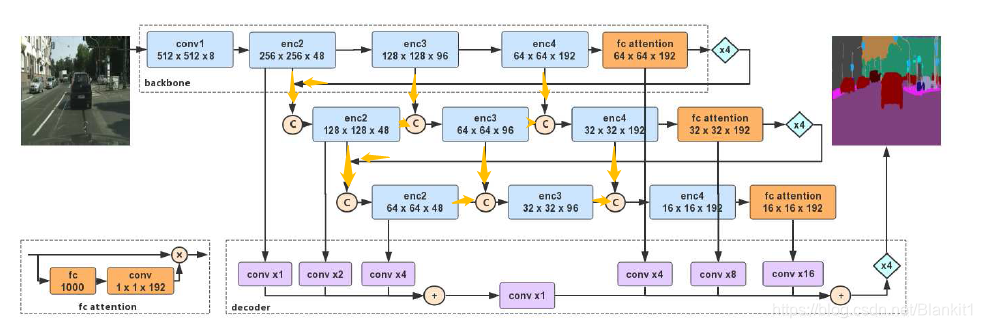
1. backbone
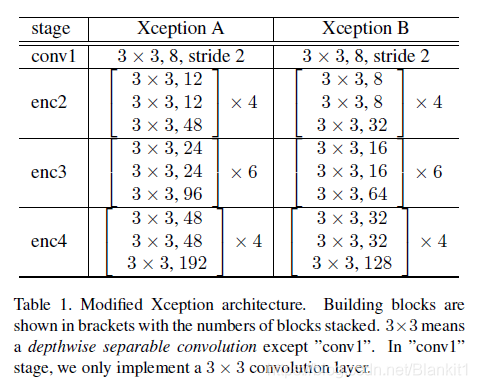
Figure 3中共有3个backbone,每个backbone都是改进版的Xception网络。

2. 子网络聚合——网络级联
图中的红色箭头部分
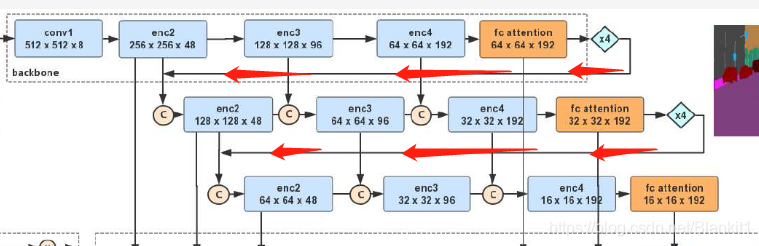
处理过程:将上一个backbone 的输出,作为下一个backbone的输入。这个上一个backbone 的输出上采样四次后输入下一个backbone。

3. 子状态聚合
橙色箭头部分。不同backbone的相应状态聚合
对于第一个backbone,
n
=
1
n=1
n=1,第
i
i
i个状态
x
i
n
x_{i}^{n}
xin 等于上一状态的输入和输出的和,当
n
>
1
n>1
n>1时,
x
i
n
x_{i}^{n}
xin 等于上一状态(
i
−
1
i-1
i−1)以及上一个网络(
n
−
1
n-1
n−1)的当前状态(
i
i
i)的级联。
i
i
i – 状态,
n
n
n – backbone

4. decoder
融合底层和高层的特征,没有使用中间层的特征。
三、实验细节
- 输入图像尺寸: 1024 x 1024 1024 x 1024 1024x1024, 512 x 1024 512 x 1024 512x1024
- 优化方法:SGD batch size 48, momentum 0.9 weight decay 1e − 5.
3.损失函数:交叉熵损失 - 数据增强: 去均值(mean suntraction),随机垂直翻转,随机缩放,缩放因子:[0.75,1.75],随机裁剪
四、问题
当使用3个Backbone A时的mIoU比2个时小?2个Backbone A时的感受野已经比图像大,在增加一个Backbone,会引入噪声。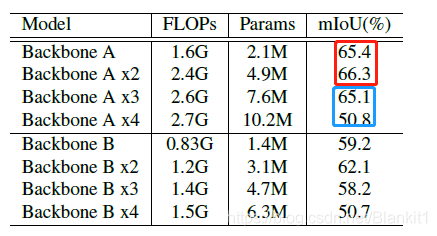














 3424
3424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









