






 本文介绍了DFANet,一种用于语义分割的深度学习模型,特别适用于处理高分辨率遥感影像。文章详细阐述了DFANet的双注意力机制和融合不同尺度信息的特点,并展示了如何结合XceptionAbackbone实现遥感影像的道路提取任务。
本文介绍了DFANet,一种用于语义分割的深度学习模型,特别适用于处理高分辨率遥感影像。文章详细阐述了DFANet的双注意力机制和融合不同尺度信息的特点,并展示了如何结合XceptionAbackbone实现遥感影像的道路提取任务。
前面我们分享了如何制作马萨诸塞州道路遥感数据集。今天我们将介绍使用DFANet来实现遥感影像道路提取。
DFANet
DFANet(Dual-FANet)是一种用于语义分割任务的深度学习神经网络架构。它最初由华为(Huawei)提出,并被设计用于处理高分辨率图像的语义分割,例如在自动驾驶领域中使用的卫星图像或城市场景图像。
DFANet的设计灵感来自于两个重要的组件:全卷积网络(Fully Convolutional Network,FCN)和空洞卷积(Dilated Convolution)。全卷积网络通常用于图像分割,而空洞卷积则可扩展感受野,以更好地捕捉图像中的上下文信息。
DFANet的核心特点包括:
双重注意力机制(Dual Attention Mechanism): DFANet引入了两个注意力机制,分别用于通道注意力和空间注意力。这有助于网络更好地聚焦于图像中的重要区域,提高语义分割的准确性。
融合不同尺度的信息: 通过使用空洞卷积,DFANet能够在不引入额外参数的情况下增加感受野,有效地融合不同尺度的信息,从而更好地理解图像的语义内容。
高效的网络结构: DFANet设计了轻量级的网络结构,以在保持准确性的同时降低计算和内存消耗,适用于一些对计算资源有限的应用场景。 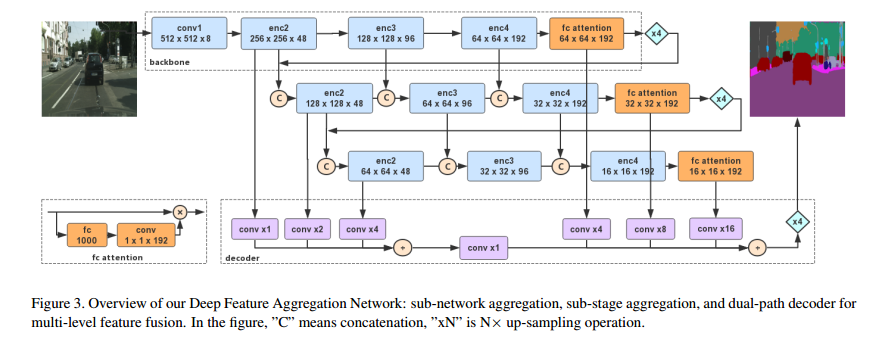
结构复现
xception
import math
import torch
import torch.nn as nn
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, bias=False):
super(SeparableConv2d, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding, dilation, groups=in_channels,
bias=bias)
self.pointwise = nn.Conv2d(in_channels, out_channels, 1, 1, 0, 1, 1, bias=bias)
def forward(self, x):
x = self.conv1(x)
x = self.pointwise(x)
return x
class Block(nn.Module):
def __init__(self, in_filters, out_filters, reps, strides=1, start_with_relu=True, grow_first=True):
super(Block, self).__init__()
if out_filters != in_filters or strides != 1:
self.skip = nn.Conv2d(in_filters, out_filters, 1, stride=strides, bias=False)
self.skipbn = nn.BatchNorm2d(out_filters)
else:
self.skip = None
self.relu = nn.ReLU(inplace=True)
rep = []
filters = in_filters
if grow_first:
rep.append(self.relu)
rep.append(SeparableConv2d(in_filters, out_filters, 3, stride=1, padding=1, bias=False))
rep.append(nn.BatchNorm2d(out_filters))
filters = out_filters
for i in range(reps - 1):
rep.append(self.relu)
rep.append(SeparableConv2d(filters, filters, 3, stride=1, padding=1, bias=False))
rep.append(nn.BatchNorm2d(filters))
if not grow_first:
rep.append(self.relu)
rep.append(SeparableConv2d(in_filters, out_filters, 3, stride=1, padding=1, bias=False))
rep.append(nn.BatchNorm2d(out_filters))
if not start_with_relu:
rep = rep[1:]
else:
rep[0] = nn.ReLU(inplace=False)
if strides != 1:
rep.append(nn.MaxPool2d(3, strides, 1))
self.rep = nn.Sequential(*rep)
def forward(self, inp):
x = self.rep(inp)
if self.skip is not None:
skip = self.skip(inp)
skip = self.skipbn(skip)
else:
skip = inp
x += skip
return x
class XceptionA(nn.Module):
def __init__(self, num_classes=1000):
""" Constructor
Args:
num_classes: number of classes
"""
super(XceptionA, self).__init__()
self.num_classes = num_classes
self.conv1 = nn.Conv2d(3, 8, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(8)
# conv for reducing channel size in input for non-first backbone stages
self.enc2_conv = nn.Conv2d(240, 8, 1, 1, bias=False) # bias=False?
self.enc2_1 = Block(8, 12, 4, 1, start_with_relu=True, grow_first=True)
self.enc2_2 = Block(12, 12, 4, 1, start_with_relu=True, grow_first=True)
self.enc2_3 = Block(12, 48, 4, 2, start_with_relu=True, grow_first=True)
self.enc2 = nn.Sequential(self.enc2_1, self.enc2_2, self.enc2_3)
self.enc3_conv = nn.Conv2d(144, 48, 1, 1, bias=False)
self.enc3_1 = Block(48, 24, 6, 1, start_with_relu=True, grow_first=True)
self.enc3_2 = Block(24, 24, 6, 1, start_with_relu=True, grow_first=True)
self.enc3_3 = Block(24, 96, 6, 2, start_with_relu=True, grow_first=True)
self.enc3 = nn.Sequential(self.enc3_1, self.enc3_2, self.enc3_3)
self.enc4_conv = nn.Conv2d(288, 96, 1, 1, bias=False)
self.enc4_1 = Block(96, 48, 4, 1, start_with_relu=True, grow_first=True)
self.enc4_2 = Block(48, 48, 4, 1, start_with_relu=True, grow_first=True)
self.enc4_3 = Block(48, 192, 4, 2, start_with_relu=True, grow_first=True)
self.enc4 = nn.Sequential(self.enc4_1, self.enc4_2, self.enc4_3)
self.pooling = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(192, num_classes)
self.fca = nn.Conv2d(num_classes, 192, 1)
# ------- init weights --------
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# -----------------------------
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
enc2 = self.enc2(x)
enc3 = self.enc3(enc2)
enc4 = self.enc4(enc3)
pool = self.pooling(enc4)
fc = self.fc(pool.view(pool.size(0), -1))
fca = self.fca(fc.view(fc.size(0), -1, 1, 1))
fca = enc4 * fca
return enc2, enc3, enc4, fc, fca
def forward_concat(self, fca_concat, enc2_concat, enc3_concat, enc4_concat):
"""For second and third stage."""
enc2 = self.enc2(self.enc2_conv(torch.cat((fca_concat, enc2_concat), dim=1)))
enc3 = self.enc3(self.enc3_conv(torch.cat((enc2, enc3_concat), dim=1)))
enc4 = self.enc4(self.enc4_conv(torch.cat((enc3, enc4_concat), dim=1)))
pool = self.pooling(enc4)
fc = self.fc(pool.view(pool.size(0), -1))
fca = self.fca(fc.view(fc.size(0), -1, 1, 1))
fca = enc4 * fca
return enc2, enc3, enc4, fc, fca
def backbone(**kwargs):
"""
Construct Xception.
"""
model = XceptionA(**kwargs)
return model
decode
import math
import torch
import torch.nn as nn
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1):
super(ConvBlock, self).__init__()
self.relu = nn.ReLU()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
x_relu = self.relu(x)
x_conv = self.conv(x_relu)
x_bn = self.bn(x_conv)
return x_bn
class Decoder(nn.Module):
def __init__(self, n_classes=19):
super(Decoder, self).__init__()
self.n_classes = n_classes
self.enc1_conv = ConvBlock(48, 32, 1) # not sure about the out channels
self.enc2_conv = ConvBlock(48, 32, 1)
self.enc2_up = nn.UpsamplingBilinear2d(scale_factor=2)
self.enc3_conv = ConvBlock(48, 32, 1)
self.enc3_up = nn.UpsamplingBilinear2d(scale_factor=4)
self.enc_conv = ConvBlock(32, n_classes, 1)
self.fca1_conv = ConvBlock(192, n_classes, 1)
self.fca1_up = nn.UpsamplingBilinear2d(scale_factor=4)
self.fca2_conv = ConvBlock(192, n_classes, 1)
self.fca2_up = nn.UpsamplingBilinear2d(scale_factor=8)
self.fca3_conv = ConvBlock(192, n_classes, 1)
self.fca3_up = nn.UpsamplingBilinear2d(scale_factor=16)
self.final_up = nn.UpsamplingBilinear2d(scale_factor=4)
# ------- init weights --------
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
# -----------------------------
def forward(self, enc1, enc2, enc3, fca1, fca2, fca3):
"""Note that enc1 denotes the output of the enc4 module of backbone instance 1."""
e1 = self.enc1_conv(enc1)
e2 = self.enc2_up(self.enc2_conv(enc2))
e3 = self.enc3_up(self.enc3_conv(enc3))
e = self.enc_conv(e1 + e2 + e3)
f1 = self.fca1_up(self.fca1_conv(fca1))
f2 = self.fca2_up(self.fca1_conv(fca2))
f3 = self.fca3_up(self.fca1_conv(fca3))
o = self.final_up(e + f1 + f2 + f3)
return o
DFANet
from models.backbone import backbone
from models.decode import Decoder
import torch
import torch.nn as nn
class DFANet(nn.Module):
def __init__(self, n_classes=1000):
super(DFANet, self).__init__()
self.backbone1 = backbone()
self.backbone1_up = nn.UpsamplingBilinear2d(scale_factor=4)
self.backbone2 = backbone()
self.backbone2_up = nn.UpsamplingBilinear2d(scale_factor=4)
self.backbone3 = backbone()
self.decoder = Decoder(n_classes=n_classes)
def forward(self, x):
enc1_2, enc1_3, enc1_4, fc1, fca1 = self.backbone1(x)
fca1_up = self.backbone1_up(fca1)
enc2_2, enc2_3, enc2_4, fc2, fca2 = self.backbone2.forward_concat(fca1_up, enc1_2, enc1_3, enc1_4)
fca2_up = self.backbone2_up(fca2)
enc3_2, enc3_3, enc3_4, fc3, fca3 = self.backbone3.forward_concat(fca2_up, enc2_2, enc2_3, enc2_4)
out = self.decoder(enc1_2, enc2_2, enc3_2, fca1, fca2, fca3)
return out
结果


总结
感兴趣的可以加入我们的星球,获取更多数据集、网络复现源码与训练结果的。
 加入前不要忘了领取优惠券哦!
加入前不要忘了领取优惠券哦! 
往期精彩



本文由 mdnice 多平台发布
















 3049
3049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











