







 文章探讨了基于对比学习的图推荐系统,尤其是SGL和XSimGCL方法。研究发现,对比损失对于推荐性能的提升更为关键,而非数据增强。SimGCL和XSimGCL提出简化对比学习的方法,通过直接在嵌入空间添加噪声实现数据增强,减少了计算复杂度,同时保持了推荐效果。实验显示,这些方法能有效缓解流行度偏差问题,提高推荐的多样性和准确性。
文章探讨了基于对比学习的图推荐系统,尤其是SGL和XSimGCL方法。研究发现,对比损失对于推荐性能的提升更为关键,而非数据增强。SimGCL和XSimGCL提出简化对比学习的方法,通过直接在嵌入空间添加噪声实现数据增强,减少了计算复杂度,同时保持了推荐效果。实验显示,这些方法能有效缓解流行度偏差问题,提高推荐的多样性和准确性。
Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation [SIGIR'22]
XSimGCL: Towards Extremely Simple Graph Contrastive Learning for Recommendation
论文链接:XSimGCL: Towards Extremely Simple Graph Contrastive Learning for Recommendation
背景/动机
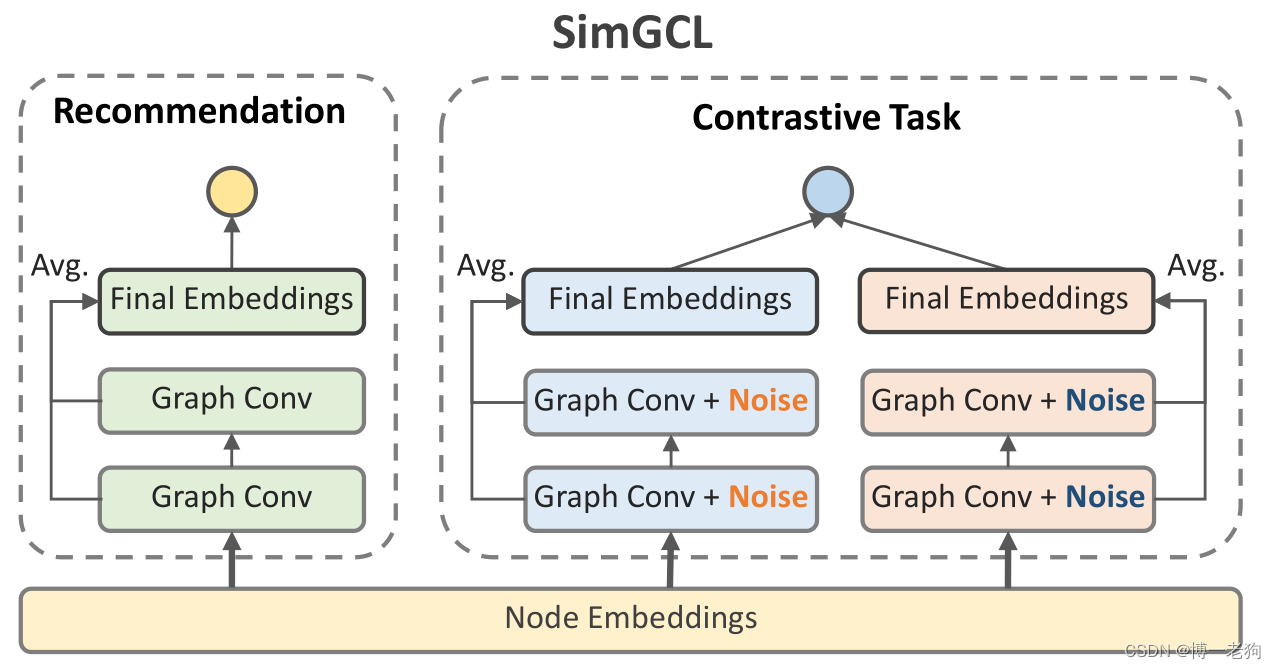
基于对比学习的图推荐系统已经引起了广泛的关注,并且在收敛速度、推荐性能和鲁棒性等方面均占山出明显优势。以SGL为代表的图对比推荐方法采用基于抽样、dropout等方式的图数据增强策略来构造用户-物品交互图的不同视角,以此提供额外监督信号,该过程如下图所示:
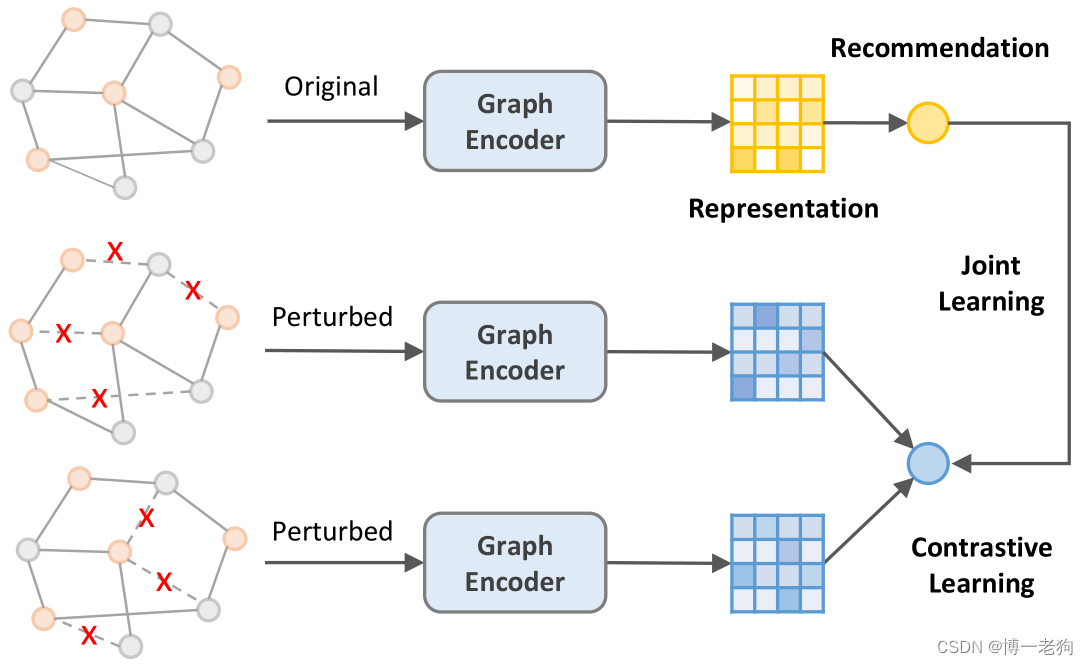
虽然这些基于图数据增强的方法取得了令人瞩目的性能提升,但隐藏在提升背后的真正原因并未被挖掘,即对比学习为什么会提升推荐性能,以及数据增强是否真的必要?
回顾基于对比学习的图推荐系统
一般地,基于对比学习的图推荐系统通过构造两个不同的图视角,并计算跨视角的对比损失以向主推荐任务提供额外的监督信号,这样的对比损失定义如下:
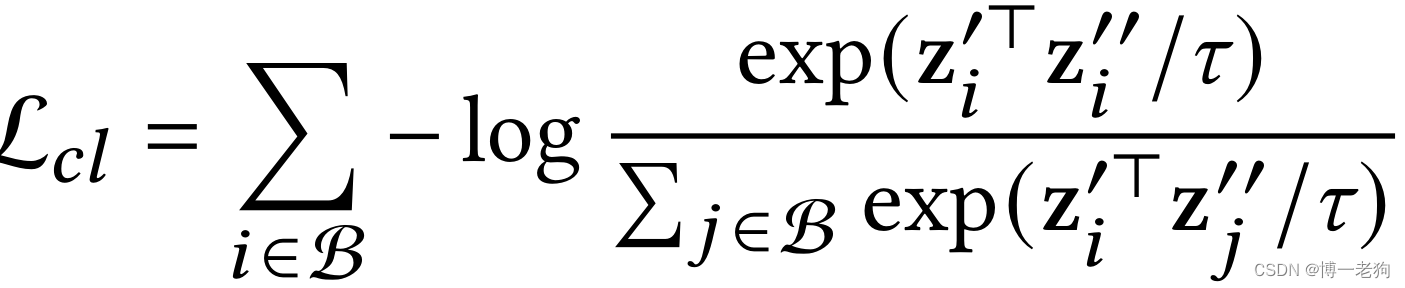
其中和
是在不同图视角里学习得到的嵌入表示,
是温度系数。具体来说,对比损失鼓励同一节点的两个视角的一致性,同时让负样本节点在特征空间里远离正样本节点。不失一般性,在不同视角里的嵌入表示通常是利用LightGCN进行学习。
很显然,为了执行该对比损失,数据增强环节必不可少,这包含一系列复杂且耗时的矩阵运算。为了进一步分析对比损失,作者为SGL构造了一个变体,称为SGL-WA(WA代表without augmentation,即不进行数据增强),其对应的对比损失定义为:
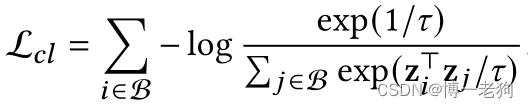
作者在Yelp2018和Amazon-Book数据集上将SGL-WA与LightGCN和SGL的三种数据增强方法(分别为SGL-ND,SGL-ED和SGL-WA)进行了对比实验,结果如下表所示:
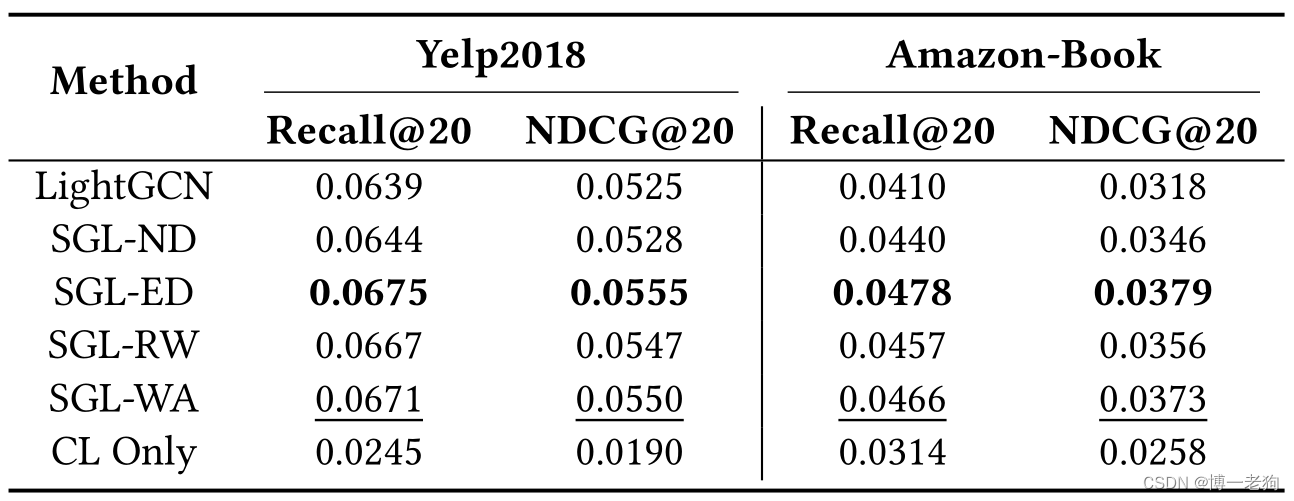
其中CL Only代表只最小化SGL中的对比损失。实验结果表明所有SGL的变体均优于没有应用对比学习的LightGCN,这展示了对比学习的有效性。另一方面,移除数据增强后,SGL-WA的性能和SGL-ED仍然具有可比性,这一结果反映出一个结论:影响性能的核心是对比损失本身,而非数据增强。
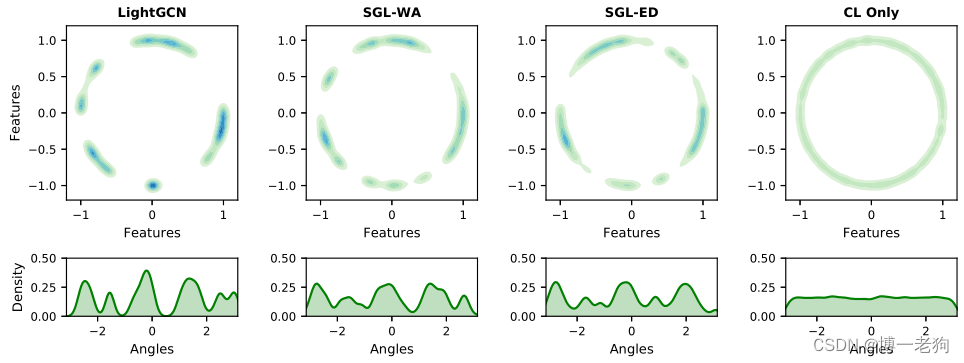
基于此,作者进一步给出了将学习到的嵌入表示映射至超球面上的2维向量的t-SNE图 ,随后用非参数高斯核密度估计绘制特征分布 。简单来说,映射的嵌入表示在超球面越接近圆环,或者特征分布越平滑,则代表该分布越接近均匀分布。从上图可以清晰地看出LightGCN表现出明显的聚类效应,而后续几个利用对比学习的方法的分布则更接近于均匀分布。
LightGCN作为一种基于信息传播和信息聚合的图推荐范式,随着图卷积层的变多,节点之间的相似性开始变大,并且趋向于高度流行的物品,从而加剧流行度偏差问题(popularity bias),这一问题在使用基于BPR损失的优化措施的情况下变得更为严重,推荐模型的训练梯度会大幅偏向于热门物品。
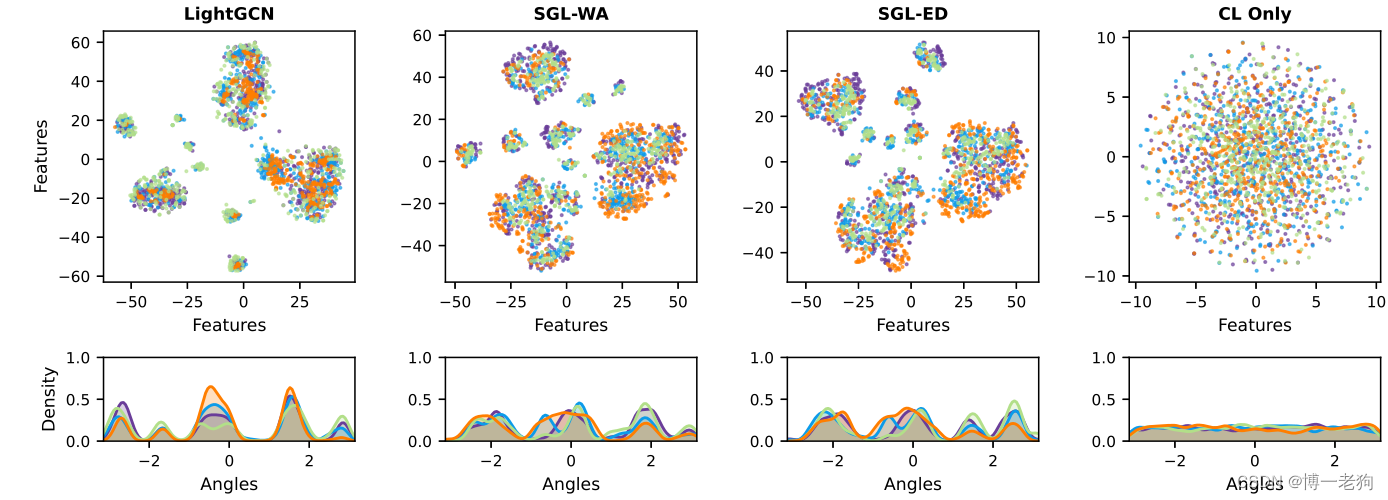
在XSimGCL论文中,作者则给出更为清晰的分析。具体来说,随机选择用户绘制t-SNE图的策略转变为绘制流行/冷启动用户和物品的t-SNE图,如下所示:
![]()
一个清晰的发现是活跃用户和热门物品具有相似分布,同时冷启动用户同样贴近于热门物品,于此同时冷启动物品则“无人问津”,独自形成一种分布。这一结果更加凸显出LightGCN会倾向于推荐热门物品的偏向性,从而导致长尾物品无法被推荐。
对于SGL-WA,可将其对比损失进行改写:
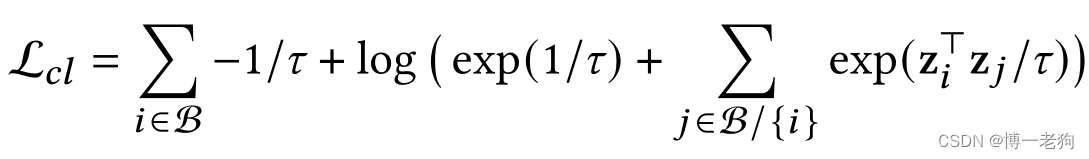
可以看出优化对比损失的本质是最小化不同节点嵌入之间的相似性(通常通过内积计算),这会使节点在特征空间里相互远离,从而形成均匀分布。至此,可以得出结论:分布的均匀性(uniformity)是SGL的推荐性能得到提升的核心因素,而不是冗余的数据增强。至此,则又有一个新的问题,即如何在不进行数据增强的前提下进行高效的对比学习?
SimGCL
由于操纵图结构来实现均匀的表示分布是费时且棘手的,所以可以从嵌入空间的视角重新考虑。具体来说,可以向嵌入表示直接添加随机噪声以实现数据增强:
![]()
其中添加的噪声变量满足,并且有
![]()
该过程如下图所示,通过向原始表示增加随机噪声向量,原始表示通过两个很小的角度进行旋转:
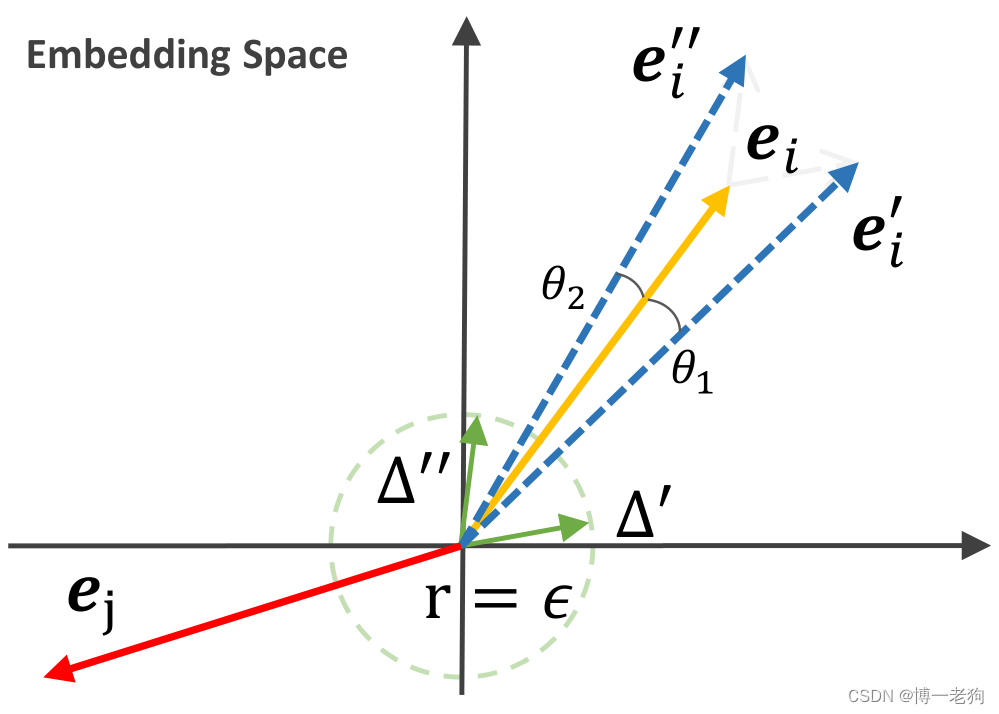
由于旋转足够小,增强后的嵌入表示依然保留着大部分原始信息。
与SGL一致,SimGCL同样采用LightGCN作为GNN模型。在每个图卷积层,不同的噪声向量均被加入目前的节点嵌入:
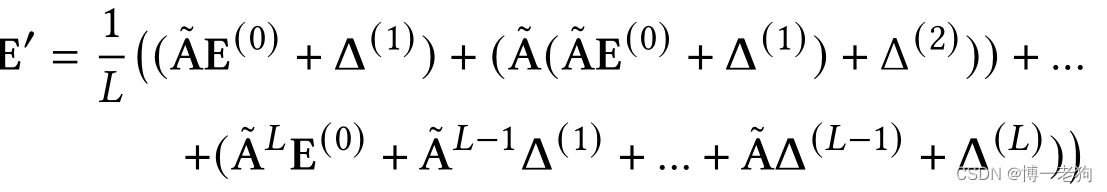
其中
![]()
XSimGCL
相比于SGL,SimGCL更为轻量级,因为其无需额外的数据增强操作。然而,SimGCL仍然受限于对比学习辅助任务,这使得其训练过程变得冗余。在每次迭代中,其都需要计算三次图卷积才能获得损失并反向传播。基于此,作者采用了跨层对比(cross-layer contrast)的思想,如下图所示:
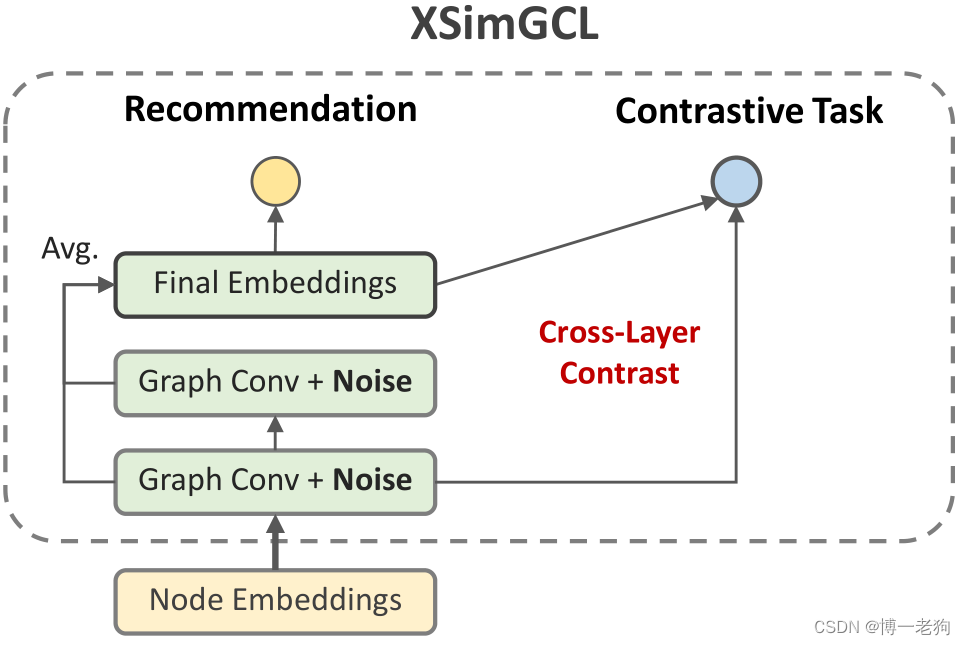
可以看出XSimGCL将辅助的对比学习任务融于主推荐任务中,并且采用跨层对比来计算对比损失:
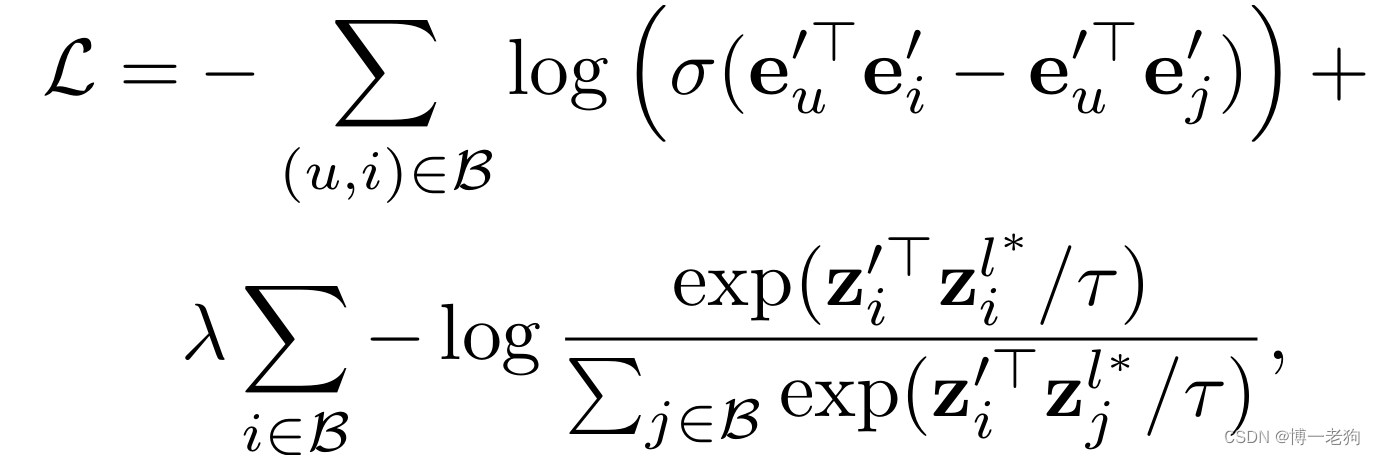
其中表示与最终层进行对比的指定层数。
时间复杂度
下表给出了LightGCN、SGL、SimGCL和XSimGCL的时间复杂度对比:
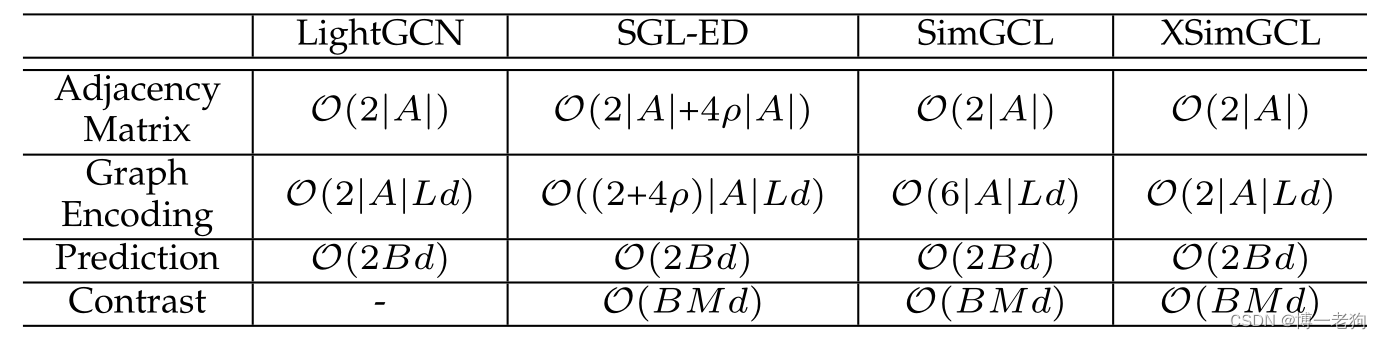
其中 是交互图的边数,
是嵌入大小,
是批大小,
表示每个批次中用户个数,
表示GCN层数,
表示SGL-ED的边保留比率。
从上表可以看出,在移除了数据增强操作后,SimGCL和XSimGCL的时间复杂度显著降低。由于SGL-ED和LightGCN需要分别完成主任务和辅助任务,这使得SGL-ED和SimGCL在图卷积过程中的时间复杂度为LightGCN的3倍,而XSimGCL与LightGCN的时间复杂度一致。
实验
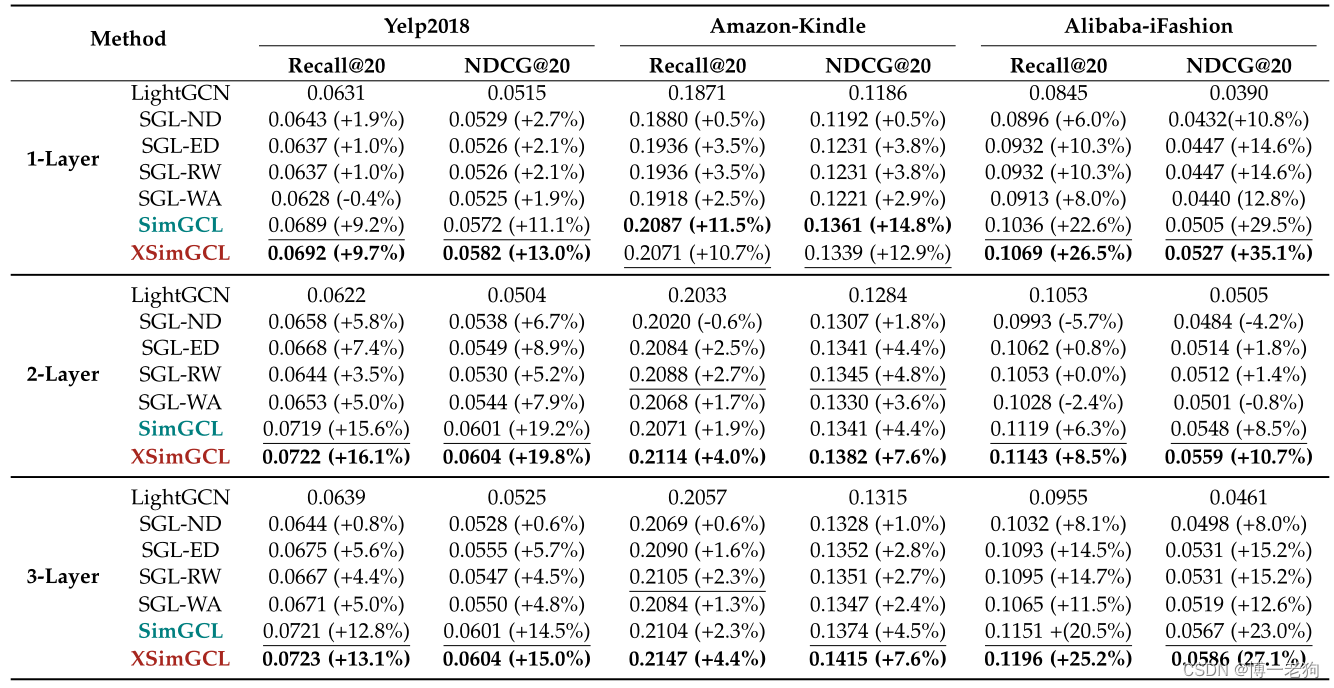
SimGCL和XSimGCL在推荐任务上的性能表现如下表所示:
除去性能方面,下图给出了LightGCN、SGL、SimGCL和XSimGCL的训练效率对比:
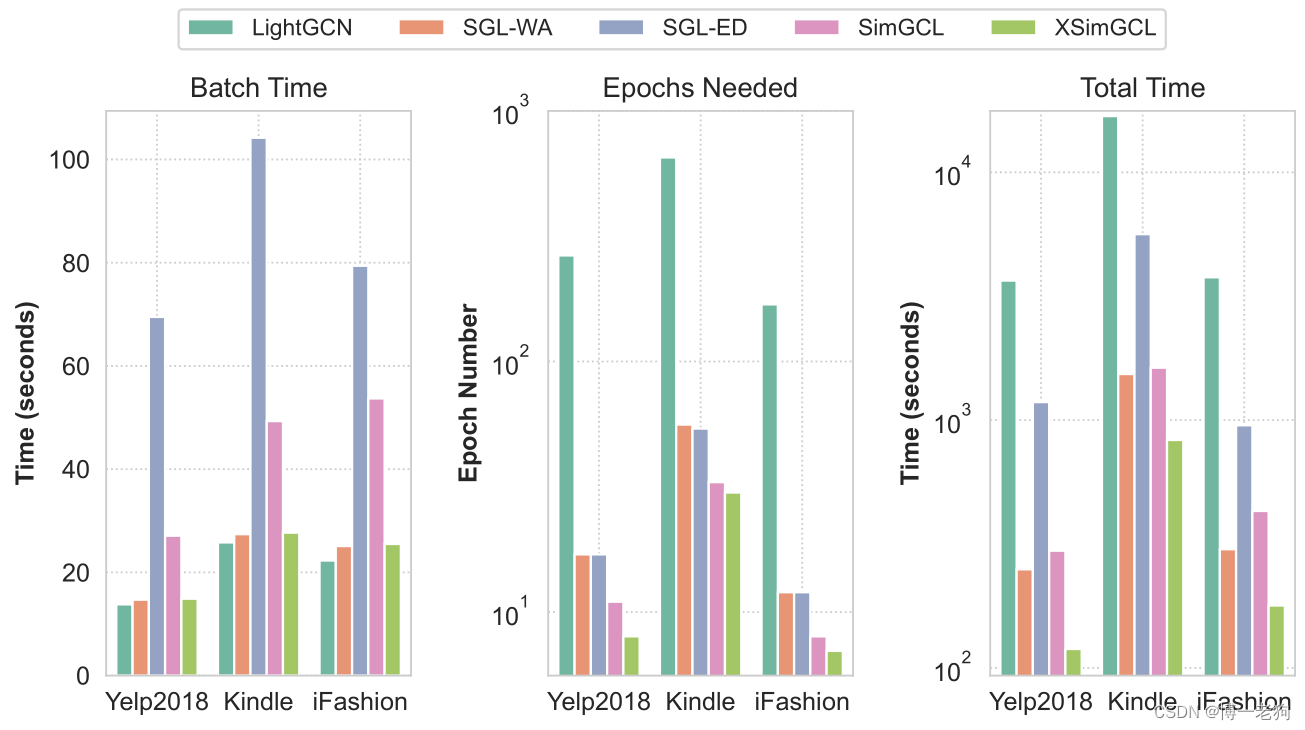
上图可以看出虽然基于对比学习的方法在每次迭代所需要的时间增加,但只需要非常少的epoch进行收敛,这使得基于对比学习的方法的总训练用时远低于LightGCN。XSimGCL通过融合推荐任务和对比任务,使得在保持良好性能的同时进一步降低了时间开销。
另一个值得关注的实验是XSimGCL中提出跨层对比的思想,用于对比的层数作为一个超参数。不同层数对于性能的影响如下图所示:
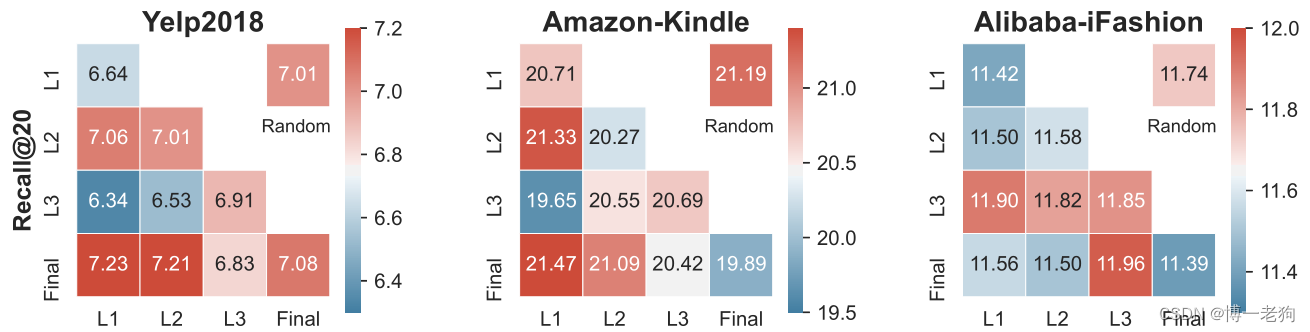
可以发现虽然不同数据集的层数选择不尽相同,但都不约而同地均是与最后一层的输出嵌入进行对比的性能最好。作者表示在3层LightGCN的基础上进行调整层数的调参次数是可以接受的。
代码
SimGCL的官方开源代码如下:
TensorFlow:QRec/SimGCL.py at master · Coder-Yu/QRec · GitHub
PyTorch:SELFRec/SimGCL.py at main · Coder-Yu/SELFRec · GitHub
XsimGCL的官方开源代码如下:
PyTorch:SELFRec/XSimGCL.py at main · Coder-Yu/SELFRec · GitHub
这里以PyTorch版本为例,简要介绍SimGCL和XSimGCL的对比学习过程。
SimGCL
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)
all_embeddings = []
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)
if perturbed:
random_noise = torch.rand_like(ego_embeddings).cuda()
ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.eps
all_embeddings.append(ego_embeddings)
all_embeddings = torch.stack(all_embeddings, dim=1)
all_embeddings = torch.mean(all_embeddings, dim=1)
user_all_embeddings, item_all_embeddings = torch.split(all_embeddings, [self.data.user_num, self.data.item_num])
return user_all_embeddings, item_all_embeddingsSimGCL的数据扰动的过程通过向图卷积过程中得到的嵌入表示添加噪声向量完成,具体过程如上所示。第5行计算得到当前层的嵌入表示后,在第7行生成与其维度一致的噪声向量,并将其加入嵌入表示中。其余过程与LightGCN一致。
def cal_cl_loss(self, idx):
u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long)).cuda()
i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long)).cuda()
user_view_1, item_view_1 = self.model(perturbed=True)
user_view_2, item_view_2 = self.model(perturbed=True)
user_cl_loss = InfoNCE(user_view_1[u_idx], user_view_2[u_idx], 0.2)
item_cl_loss = InfoNCE(item_view_1[i_idx], item_view_2[i_idx], 0.2)
return user_cl_loss + item_cl_loss在计算对比损失过程中,需要首先分别调用forward()以获得用户和物品的两个视角下的嵌入表示(第4~5行),随后分别计算InfoNCE损失(第6~7行,InfoNCE损失可以参见经典图推荐系统论文Self-supervised Graph Learning for Recommendation算法及代码简介_博一老狗的博客-CSDN博客),完整的对比损失为用户损失和物品损失之和(第8行)。
XSimGCL
相比于SimGCL,XSimGCL将对比任务和主推荐任务融为一体,对应代码如下:
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)
all_embeddings = []
all_embeddings_cl = ego_embeddings
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)
if perturbed:
random_noise = torch.rand_like(ego_embeddings).cuda()
ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.eps
all_embeddings.append(ego_embeddings)
if k == self.layer_cl - 1:
all_embeddings_cl = ego_embeddings
final_embeddings = torch.stack(all_embeddings, dim=1)
final_embeddings = torch.mean(final_embeddings, dim=1)
user_all_embeddings, item_all_embeddings = torch.split(final_embeddings, [self.data.user_num, self.data.item_num])
user_all_embeddings_cl, item_all_embeddings_cl = torch.split(all_embeddings_cl,
[self.data.user_num, self.data.item_num])
if perturbed:
return user_all_embeddings, item_all_embeddings, user_all_embeddings_cl, item_all_embeddings_cl
return user_all_embeddings, item_all_embeddings其中多了额外的参数self.layer_cl用于选择进行对比的层数,其他部分没有区别。

















 745
745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









