






SimGCL与XSimGCL
这段时间阅读了一下将对比学习应用到推荐系统中的一篇性能比较好的文章,对比了一下该文章作者在SIGIR‘22会议上发表的SimGCL模型和之后同作者在SCI一区中发布的XSimGCL模型。
1. 特征的对齐性和均匀性:
- 对齐性指的是相似的样本拥有类似的特征向量,它应该对无关的噪声保持不变。
- 均匀性的特征能够保存更多的信息,也就是特征大致均匀的分布在超球面上。均匀性之所以能够保留更多特征,是因为相对只有几个值比较突出的非均匀分布,均匀分布的特征分布更广,每个特征都保留自己独特的信息,也可以通过这些信息的运算组成更多的结果。
2. 二者的模型框架图
SimGCL:模型框架中包含两部分,分别为推荐任务和对比学习任务,最终损失为两个任务各自的损失之和。
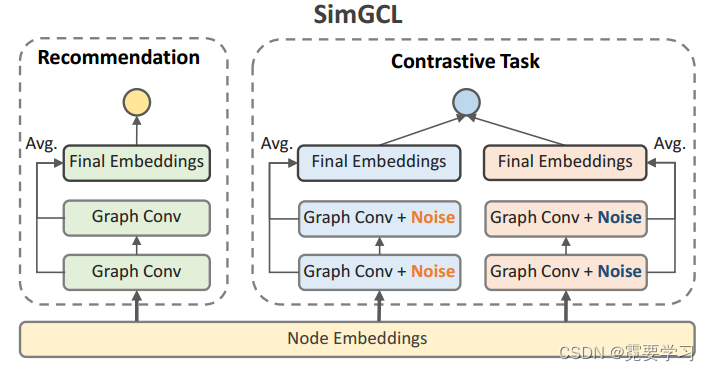
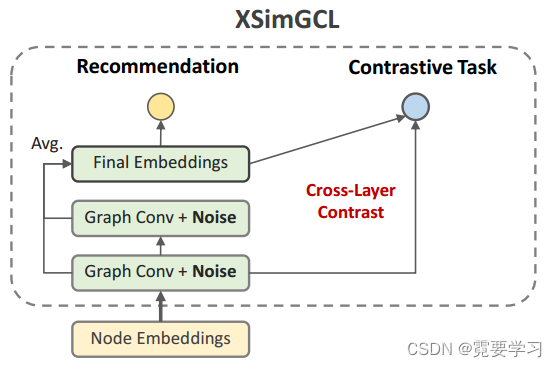
XSimGCL:模型框架中只包含一次前向传播过程,对比学习任务是通过将某一层的嵌入作为增强的数据来获得对比学习损失。
3. 二者的联合优化损失函数
SimGCL: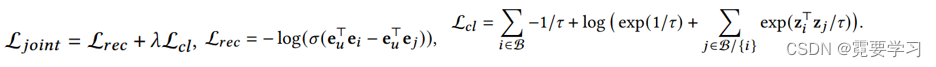 XSimGCL:
XSimGCL: 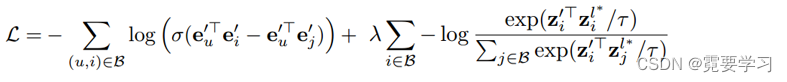
l
∗
l^*
l∗表示与最终层对比的层
3. 论文中的最佳超参数设置
SimGCL与XSimGCL最佳性能时的层数设置为
l
a
y
e
r
=
3
layer=3
layer=3

4. SimGCL主要代码
- 以下为前向传播函数,即最终嵌入表示向量的计算过程。
在推荐任务的前向传播过程中perturbed=False,不为嵌入表示加入噪声。
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)#将用户嵌入和项目嵌入按行拼接
all_embeddings = []
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings) #计算得到当前层的嵌入表示
if perturbed: #是否为嵌入添加噪声
random_noise = torch.rand_like(ego_embeddings).cuda() #生成随机噪声,由区间[0,1)上均匀分布的随机数填充
ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.eps #对应噪声的两个限制
all_embeddings.append(ego_embeddings)
all_embeddings = torch.stack(all_embeddings, dim=1) #将嵌入表示拼接为一个69716,2,64维度的tensor
all_embeddings = torch.mean(all_embeddings, dim=1) #对不同层嵌入的同位置元素求均值获得得最终表示
user_all_embeddings, item_all_embeddings = torch.split(all_embeddings, [self.data.user_num, self.data.item_num])
return user_all_embeddings, item_all_embeddings
- 对比学习损失计算
以下为SimGCL模型的 L c l L_{cl} Lcl的计算过程,最终的 L c l L_{cl} Lcl为用户损失、项目损失之和。
def cal_cl_loss(self, idx): #idx为一个列表,包含两个列表,分别为一批次的用户id及对应的正样本id
u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long)).cuda() #unique挑出tensor中的独立不重复元素
i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long)).cuda()
user_view_1, item_view_1 = self.model(perturbed=True) #为原始表示添加噪声生成视图1
user_view_2, item_view_2 = self.model(perturbed=True) #为原始表示添加噪声生成视图2
user_cl_loss = InfoNCE(user_view_1[u_idx], user_view_2[u_idx], 0.2)
item_cl_loss = InfoNCE(item_view_1[i_idx], item_view_2[i_idx], 0.2)
return user_cl_loss + item_cl_loss #最终的对比学习损失为用户损失和项目损失之和
5.XSimGCL主要代码
- 以下为前向传播函数,即最终嵌入表示向量的计算过程。
与SimGCL不同之处在于SimGCL需要在单独在对比学习任务中为嵌入添加不同噪声生成多个视图,而XSimGCL直接在前向传播过程中,直接获得用于对比学习的嵌入,即将指定层的嵌入表示作为SimGCL中不同的视图。
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0)
all_embeddings = []
all_embeddings_cl = ego_embeddings
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)
if perturbed:
random_noise = torch.rand_like(ego_embeddings).cuda()
ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.eps
all_embeddings.append(ego_embeddings)
if k==self.layer_cl-1: #判断当前层是否为设定的对比层
all_embeddings_cl = ego_embeddings #获取对比层的嵌入
final_embeddings = torch.stack(all_embeddings, dim=1)
final_embeddings = torch.mean(final_embeddings, dim=1)
user_all_embeddings, item_all_embeddings = torch.split(final_embeddings, [self.data.user_num, self.data.item_num])
user_all_embeddings_cl, item_all_embeddings_cl = torch.split(all_embeddings_cl, [self.data.user_num, self.data.item_num])
if perturbed:
return user_all_embeddings, item_all_embeddings, user_all_embeddings_cl, item_all_embeddings_cl
return user_all_embeddings, item_all_embeddings
- 对比学习损失计算
在XSimGCL中将最终嵌入作为视图1,指定层的嵌入作为视图2来完成对比学习任务
def cal_cl_loss(self, idx, user_view1, user_view2, item_view1, item_view2): #idx为两个链表,0为用户、1为正样本,最终嵌入作为视图1,指定层的嵌入作为视图2
u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long)).cuda()
i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long)).cuda()
user_cl_loss = InfoNCE(user_view1[u_idx], user_view2[u_idx], self.temp)
item_cl_loss = InfoNCE(item_view1[i_idx], item_view2[i_idx], self.temp)
return user_cl_loss + item_cl_loss
原文及代码链接
SimGCL
原文:Are Graph Augmentations Necessary?
代码:SELFRec/SimGCL.py at main · Coder-Yu/SELFRec · GitHub
XSimGCL:
原文:XSimGCL: Towards Extremely Simple Graph Contrastive Learning for Recommendation
代码:SELFRec/XSimGCL.py at main · Coder-Yu/SELFRec · GitHub
存在的疑问
- 在损失等计算过程中,为什么要给一些结果添加值10e-6,以InfoNCE损失为例
cl_loss = -torch.log(pos_score / ttl_score+10e-6)
已解决:对比损失中包含对数函数,为了防止出现0,需要在最后增加一个极小项
- batch_loss式子中l2_reg_loss是作用?
batch_loss = rec_loss + l2_reg_loss(self.reg, user_emb, pos_item_emb) + cl_loss
- 每一轮次结束前这个语句作用是什么?
我个人认为是用来保存当前轮次无梯度值的嵌入用于测试用。
with torch.no_grad():
self.user_emb, self.item_emb = self.model()















 1863
1863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









