







RecDCL: Dual Contrastive Learning for Recommendation
论文链接:RecDCL: Dual Contrastive Learning for Recommendation | Proceedings of the ACM on Web Conference 2024
代码链接:GitHub - THUDM/RecDCL: RecDCL: Dual Contrastive Learning for Recommendation (WWW'24, Oral)
简介
自监督推荐(Self-supervised recommendation,SSR)在协同过滤任务中展示了巨大的成功。其中一个重要分支——对比学习(contrastive learning,CL)通过对比原始数据和增强数据的嵌入来缓解推荐的数据稀疏问题。然后,现有的基于CL的SSR方法大多数直观一个batch的对比,而没有探索特征维度的潜在规律。此外,在推荐场景,还没有工作考虑过基于batch的对比(BCL)和基于特征的对比(FCL)。因此,本文提出了用于推荐的双对比方法,简称为RecDCL。
预备知识
协同过滤
设用户、物品和用户-物品二部图的符号分别是U、I和G。协同过滤模型致力于排序所有物品,并预测用户可能会交互的新物品。目前,用于协同过滤的流程框架是GCN。给出用户u和物品i,GCN致力于迭代地执行邻居信息传播和聚合,以此更新交互图G上的所有节点。最后用户和物品的排序分数使用内积进行计算。目前的流行优化策略是使用成对化优化损失(例如Bayesian Personalized Ranking):
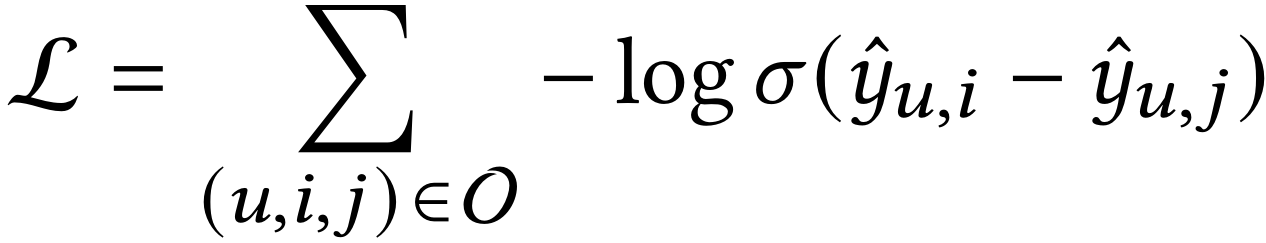
其中O是训练数据,u、i和j分别是用户u、正样本i(用户u交互过的物品)和负样本j(物品u没有交互过的物品),σ是非线性激活函数。
Batch-wise Contrastive Learning(BCL)
最近的趋势是采用自监督学习中的对比学习进一步提升协同过滤模型的性能。其核心思想是通过数据增强构造原始数据的新视角,并且通过InfoNCE损失来增强同一节点的不同视角的一致性:
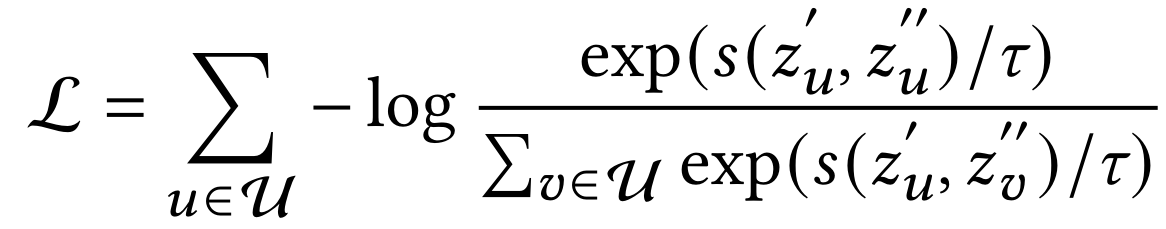
其中s()是余弦相似度函数,是温度系数,z_u'和z_u‘’分别是节点u的两个增强视角的嵌入。关于InfoNCE和对比学习的更多介绍可以参考:
经典图推荐系统论文Self-supervised Graph Learning for Recommendation算法及代码简介-CSDN博客
Feature-wise Contrastive Learning(FCL)
在对比表示学习领域的近期工作进一步强调面向特征目标的表示的重要性。给定两个批次的扰动视角,Barlow Twins首先将这些输入送入编码器并得到对应的批表示。最后,它通过构造两个视角的嵌入之间的互相关矩阵(cross-correlationmatrix)C来优化损失:
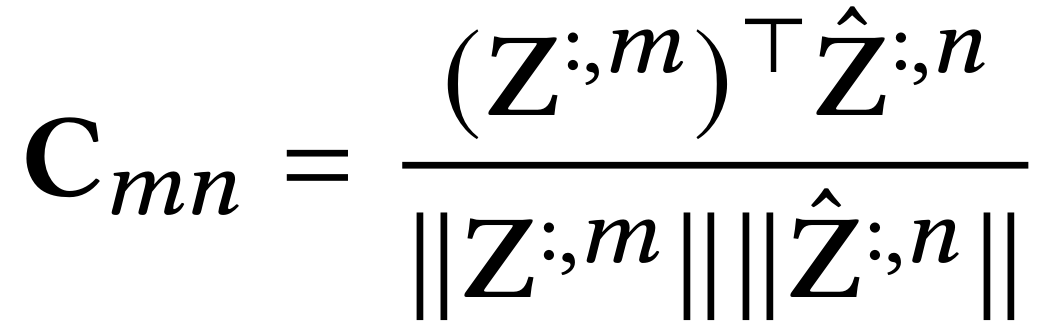
其中 表示嵌入矩阵的特征索引。C是一个方阵,与编码器的输出具有相同的维度:
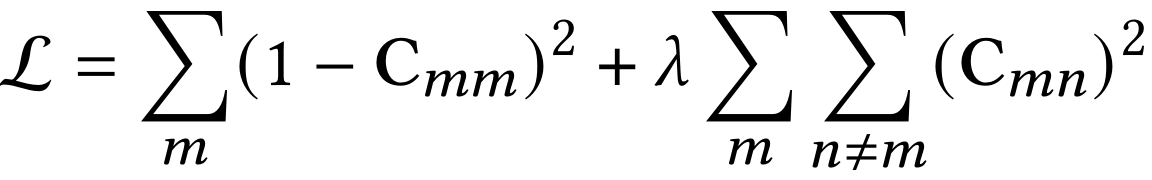
上式第一项被称为不变性项(invariance term),目的是使对角线值接近1,并且即使应用扰动也保持嵌入不变。另一方面,另一方面,冗余减少项被定义为使非对角线元素接近0,并且去相关嵌入的每个维度表示。
分析
许多基于BCL的方法遵循InfoNCE,其核心思想是对比原始样本和增强样本的嵌入,从而增强两个输入视角的互信息。后续的研究进一步表明BCL的核心在于两个量化指标:正样本对的对齐(alignment)和特征空间分布的均匀性(uniformity)。直觉上,BCL和FCL具有类似的机制:让正样本对拉近,同时让负样本对彼此远离。区别在于构造样本对。这种不同赋予两种对比方法不同的优化效果。
形式上,设和
是原始样本和增强样本对嵌入矩阵,BCL的优化目标被定义如下:
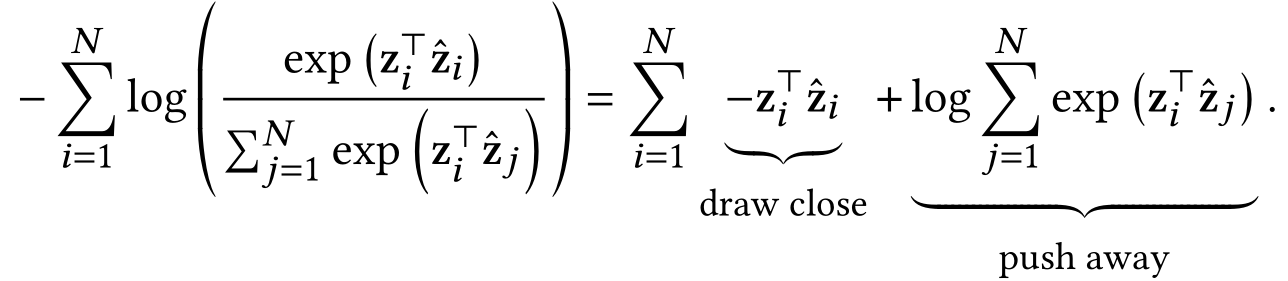
对于等式右边,有:
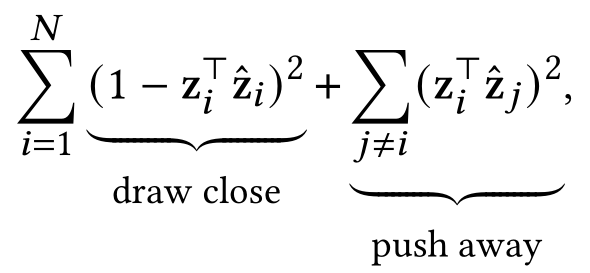
push-away项是上面BCL优化目标中对应项的合理近似,因为sum-square函数和log-sum-exponential函数相对地增强较大项,而对于非负值削弱较小项。根据上面的替换,我们可以将BCL转变为矩阵形式:
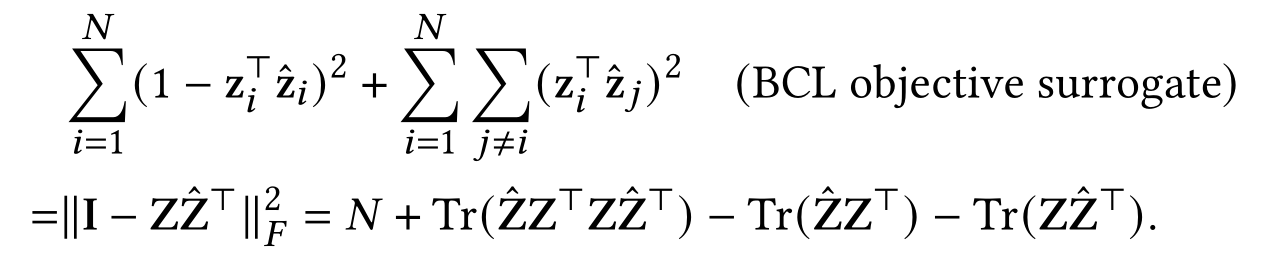
另一方面,设FCL的冗余减少项的权重为1,则FCL的矩阵形式为:
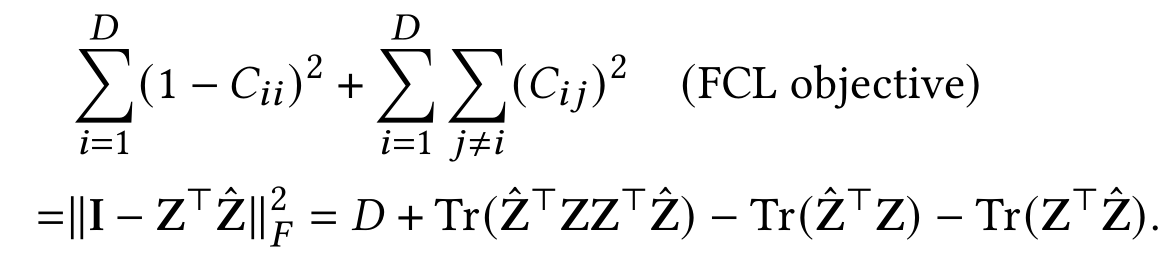
对比BCL和FCL的矩阵形式,可以发现它们具有形式相似性,即BCL和FCL的目标可以彼此相互近似地转换。
另一方面,对于归一化的样本嵌入,BCL和FCL中让负样本远离对于嵌入优化具有不同的影响。具体来说,BCL鼓励样本在嵌入空间内均匀分布,而对于FCL,它倾向于让样本的表示正交。这种不同主要来自于BCL鼓励负样本对的内积(在batch维度)尽可能地小,而FCL只约束负样本对的内积(在特征维度)尽可能接近于0。
为了验证上述观点,作者设置了消融实验。具体来说,作者粉笔对比了Yelp数据集中FCL、BCL和FCL+BCL的嵌入的平均熵。设X表示一个样本的嵌入。作者选择通过两种方法的x的Top-K(1024和2048)绝对值,并且将他们归一化为K-维度的概率分布。第一种方法是降序排序每个样本的嵌入值并获得Top-K值,称之为each-sample。第二种方法计算所有样本的每个维度的均值,对值排序,获得top-K索引,并提取每个样本的Top-K值,称之为mean-sample。实验结果如下表所示(更小的平均熵表明更尖锐的嵌入分布)。
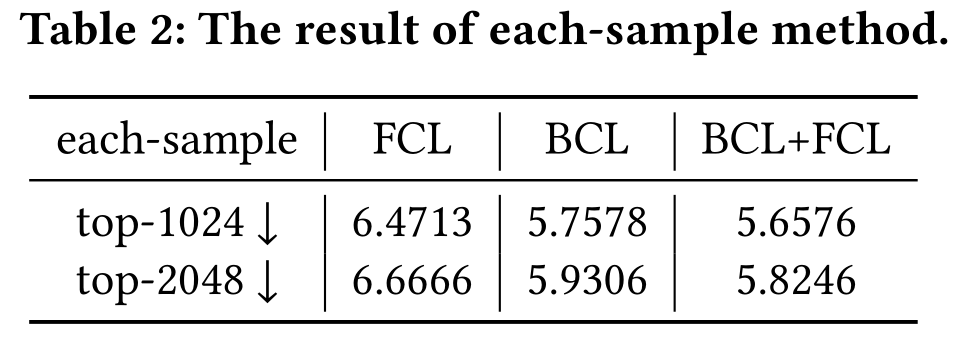
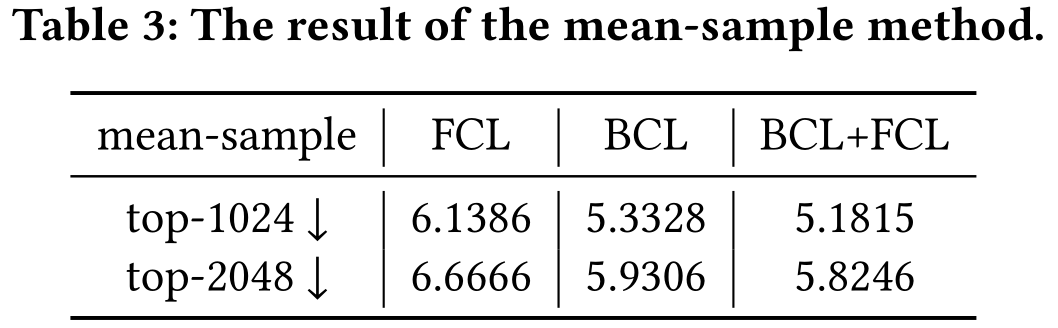
从上表可以观察到,BCL+FCL取得了最小的平均熵,这表明BCL+FCL的嵌入分布更尖锐。
RecDCL
根据上面的分析,作者提出了用于推荐的双对比学习框架,称之为RecDCL,框架图如下所示:
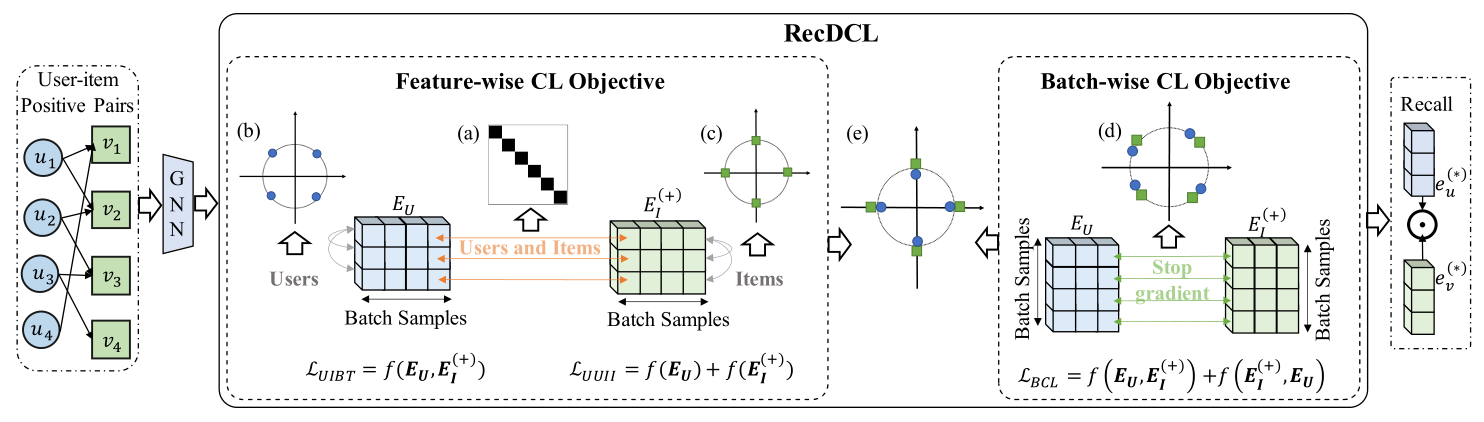
FCL Objective
消除用户和物品之间的冗余
为了利用FCL实现对齐,作者提出UIBT,其计算用户和物品嵌入得到互相关矩阵,并通过不变项和方差项使它接近于单位矩阵。形式上,用户嵌入和物品嵌入之间的互相关矩阵C可以通过计算得到,其是一个方阵,与编码器的输出具有相同的维度。注意到作者定义了不变项和 冗余减少项(系数为1/F):
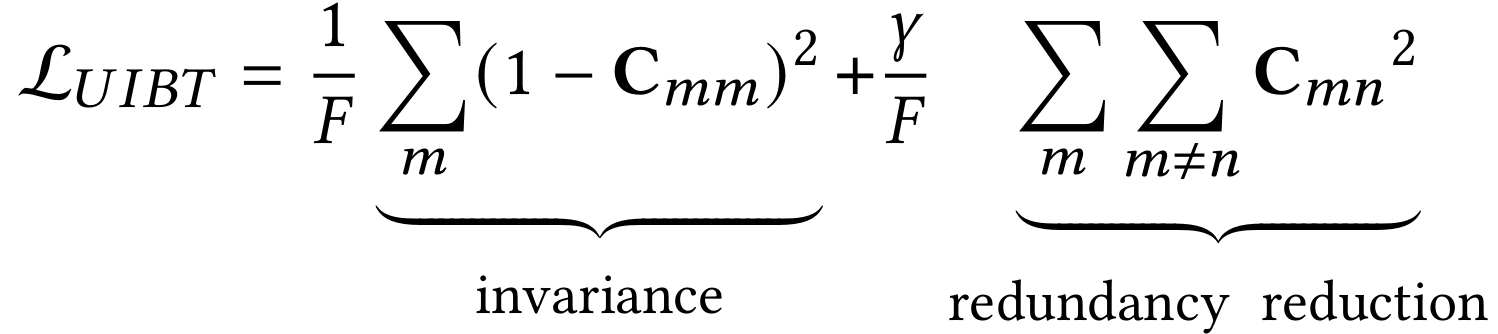
上式中,不变项旨在让矩阵C的对角元素为1,并且满足矢量不变性。此外,冗余减少项致力于让矩阵C的非对角元素等于0,并减少输出表示的冗余。
消除用户和物品内部的冗余
进一步,为了增强不同特征之间的嵌入多样性,作者提出基于多项式核的特征均匀性优化。多项式核是一种天然的特征方法在超球面上表示样本。考虑到用户和物品之间的分布差异性,作者分别计算用户和物品内部的均匀性:
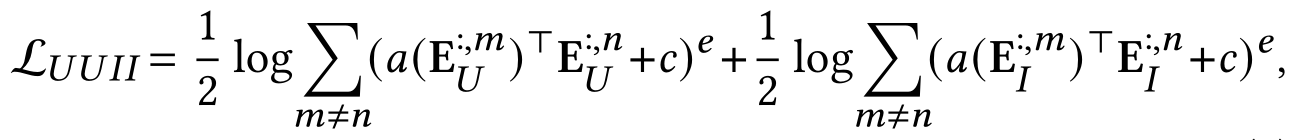
其中表示用户嵌入的第m行,而
表示用户嵌入的第n列。上式中a、c和e分别是多项式核的参数,分别默认设置为1,1e-7和4。由于批内样本与实际用户和物品数据分布更一致,因此仅通过批内样本的表示来计算特征均匀性损失。
BCL Objective
基本的BCL
为了验证通用性,作者采取了一个基线,其只结合了基本的BCL(DirectAU)和FCL(仅非对角元素),称之为DCL:
![]()
改进的BCL
正如之前的分析,直接结合FCL和BCL可以直观地增强模型训练。作者在输出的表示上执行数据增强,并行生成对比但相关的视角。作者采取了LightGCN的图编码器来进行节点的聚合和传播。在进行多层的传播后,作者使用历史嵌入来执行增强。
设定是当前通过图编码器得到的嵌入,而
是历史嵌入。而扰动的表示
通过下面的方式得到:
![]()
其中是一个超参数。随后,优化过程被定义为:
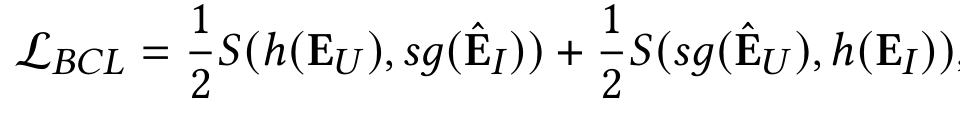
其中h是一个多层感知机,sg()是停止梯度操作,而S()是余弦相似度。
完整的RecDCL的训练目标是FCL和BCL的联合训练,定义如下:
![]()
其中α和β是两个权衡超参数。 RecDCL的完整训练过程如下所示:

实验
作者在四个数据集上将提出的DCL、RecDCL与许多经典方法进行了对比实验,实验结果如下所示:
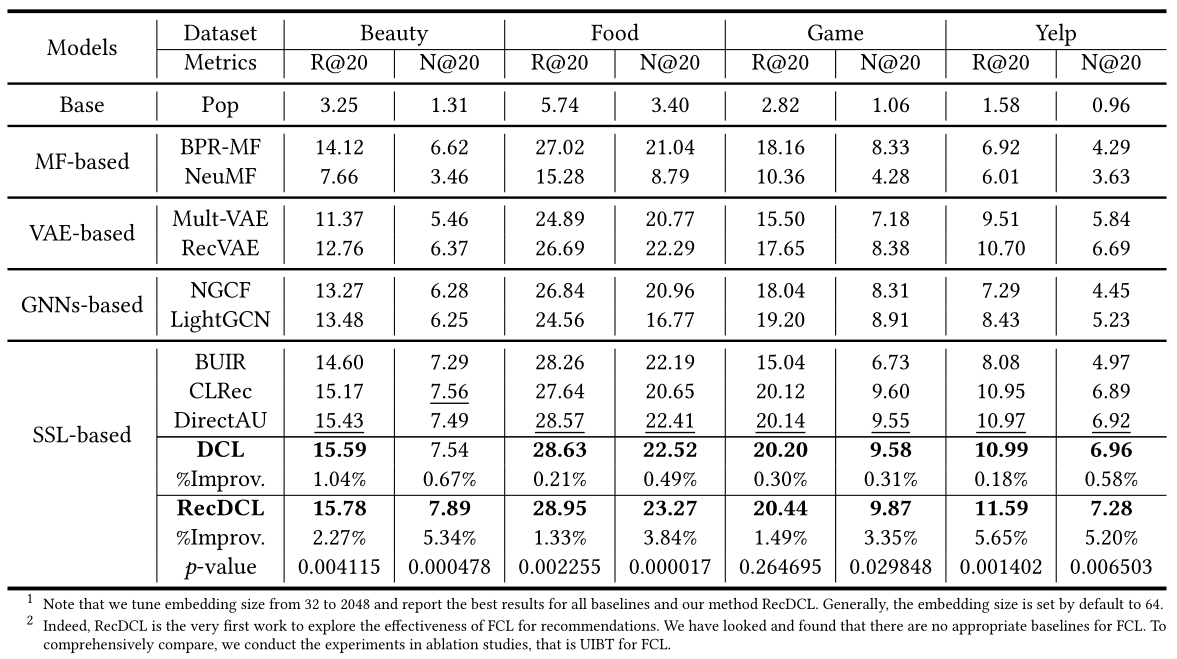
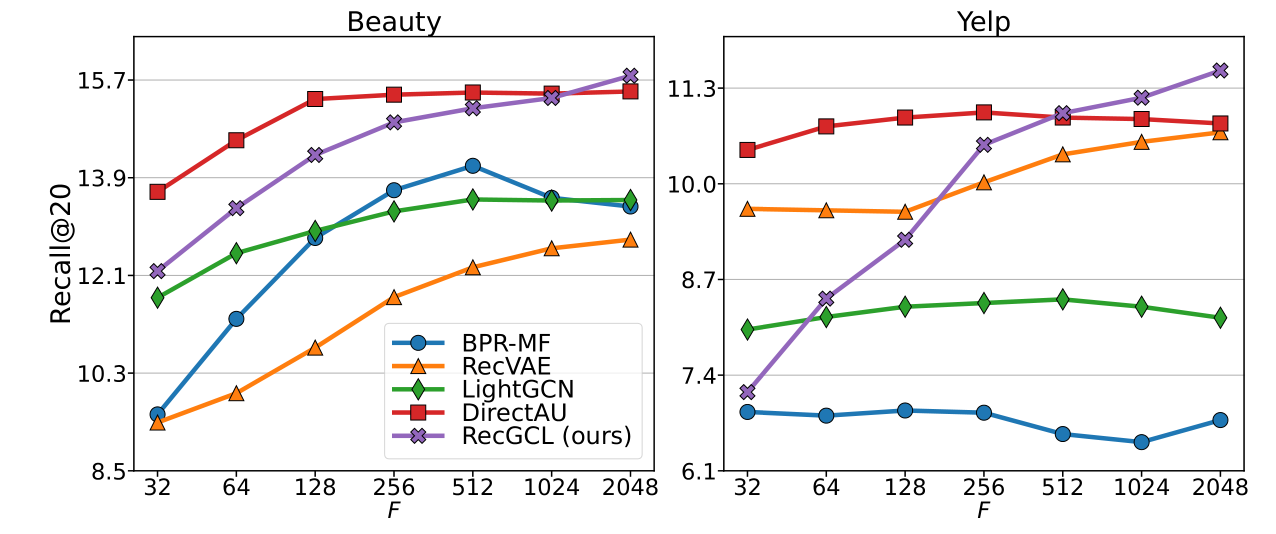
一个需要注意的实验室RecDCL似乎在更大维度下表现良好。在论文中,作者指出在嵌入维度设置为2048时,RecDCL可以取得相比于基线更好的性能表现,这一点与现有的主流设置(默认为64)相差比较大:















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









