







Abstract
- 同构的图网络用于表示异构的数据可能不够适用。本文提出了异构图transformer对于异构数据进行建模。
- 分别对于三个问题进行解决:模型异构性,图动态特性以及web-scale图数据。第一个使用节点和边特定类型的参数依赖,构建交互异构注意力。第二个提出了相对时序编码机制,第三个聚焦于训练效率方面。在这里我们聚焦于第一个方面,如何对图的操作。
- 对公开学术网络的图数据集(大规模图)进行实验,相对于SOTA效果提升了9-21个百分点
Introduction
- 一个meta-path的例子




Method
本文提出了异构图transformer,主要思想是使用异构图中的meta relation参数化(parameterize)异构交互注意力,消息传播以及聚合的参数矩阵。
1 整体架构:

目标:聚合源节点s的信息形成一个具有上下文表示的目标节点t。
- 可以将这个过程分为三个阶段:
- Heterogeneous Mutual Attention
- Heterogeneous Message Passing
- Target-Specific Aggregation
2 通常基于注意力的GNN的范式

分别包括了Attention,Message以及Aggregate。
以GAT为例子:

其假设每一个节点都是同一个类型的,因此在计算过程中都使用相同的权重。对于异构图来说,每一个类型可能包含了不同的特征分布,因此用相同的权重可能不合适。
3
- 基于这个motivation,本文使用了异构交互注意力。其想通过meta-relation计算交互注意力,在transformer的基础上改动,主要的不同在于,原始的transformer对于所有的单词都使用同一个映射函数,而本文通过meta relation对于不同的类型设置不同的权重。并且将目标节点作为Query vector,源节点作为Key vector,基于此计算注意力。公式如下所示:

对于分布不同的建模。以及异构图的一个特点是节点之间的边有着不同类型的关系,这里不同于原始的transformer直接计算dot-product,而是添加了基于边的类型的可训练的矩阵,用于捕获不同的类型的边的语义关系。并且添加了一个先验张量表示每一个meta-relation的重要程度。 - Heterogeneous Message Passing
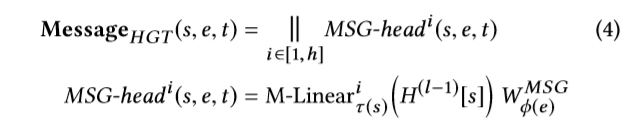
- target-specific aggregation
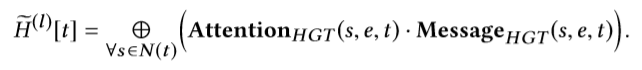
聚合源节点更新表示,并且对表示进行类型转换,以及残差连接
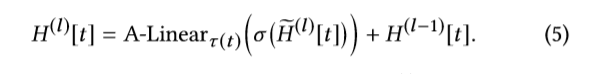
4 RTE
















 2280
2280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









