







事务
介绍和操作
事务是一组操作的集合,是不可分割的工作单位。这一组操作要么都失败要么都成功。
事务是为了在数据相关联时对表的操作之后保持表之间数据关系的一致性。
MySQL默认执行一条SQL语句就是提交完成一个事务,所以当执行多条SQL语句时,当有部分SQL语句执行不成功就会出现数据的不一致。

SQL语句写在 开始事务和提交事务之间,所有SQL都成功执行commit,失败执行rollback
先执行开启事务,再执行SQL语句会发现表中的数据并没有发生变化但是你去查询时会发现数据其实已经被操作了,执行的事务是和表那个地方的事务其实是隔离的(这么理解吧)
提交事务之后,查看表就会发现表数据完成了操作
回滚事务,当SQL语句有一条执行失败就会rollback,将之前成功执行的SQL语句操作的数据复原
四大特性 ACID
原子性(Atomicity):事务是不可分割的最小单元,要么全部不成功,要么全部失败。
一致性(Consistency):事务完成时,必须使所有的数据都保持一致的状态。
隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的的独立环境下进行。
持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
索引
介绍
索引是帮助数据库高效获取数据的数据结构
数据量太大时,普通查询会非常的耗费时间。
创建索引是一次性的操作,创建后索引将会一直存在刚开始建表的时候就可以创建索引,如果之后再创建,虽然第一次创建的时候会费点时间但是之后的查询效率将会非常高,并且不用每查一次创建一次索引。
无索引时,查询将会进行全表扫描就是每条记录都进行比对。
有索引时,数据结构就可以是二叉排序树(举个例子),将建索引的字段值建立成一颗二叉排序树查找效率就会非常高效,索引建好那么二叉排序树就建好了,查询就按二叉排序树的查询来查了。

增删改时就会让索引调整来维护数据结构
不过现在都是磁盘空间都用T做单位了索引空间也占不了多少,其次查询在业务中几乎占90%以上,其它操作相比起来也就无关紧要了。
结构
MySQL支持的索引结构很多,Hash索引,B+树索引,Full-Text索引等,平常默认就是B+树的结构组织的索引。(数据结构的话,反正之前是看严蔚敏出的那本书吧)
B+树(多路平衡搜索树)
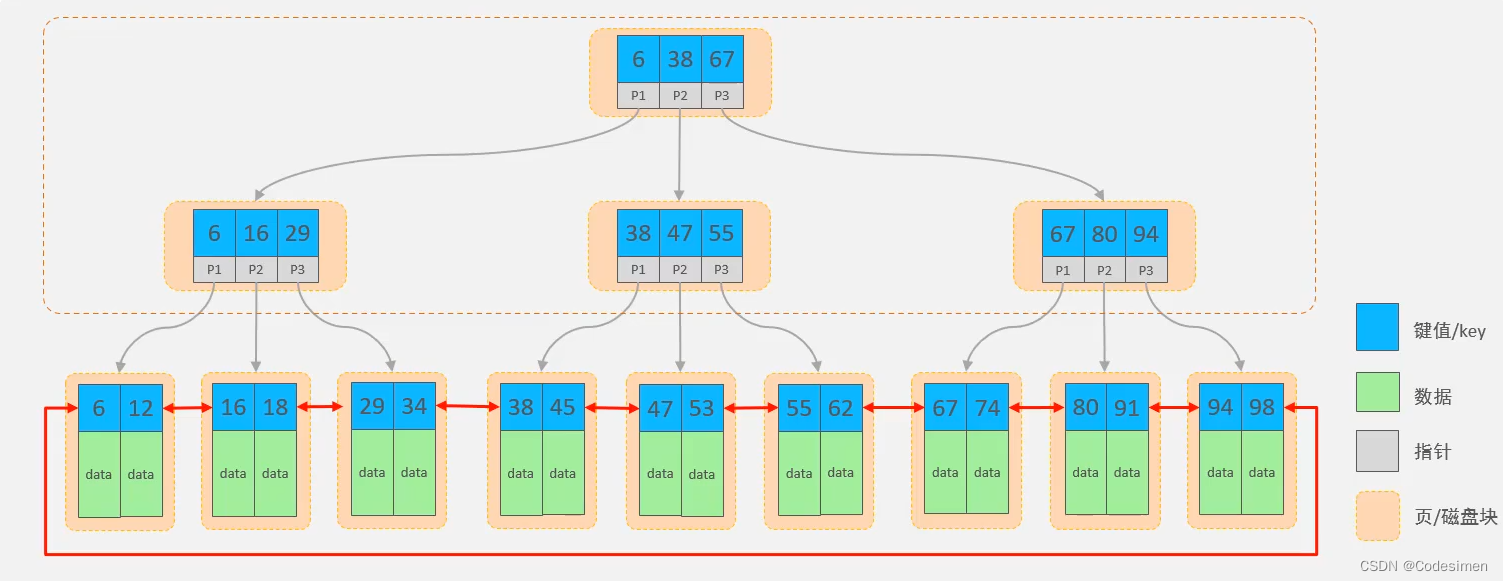
特点:
一个节点可以存多个key,一个key对应一个指针
所有数据存在叶子结点,非叶子节点仅用于索引数据
叶子结点形成双向循环链表,便于数据的排序和区间的范围查询
不用什么红黑树,二叉排序树等是因为大数据量建成的数高度太高了,非常影响查询效率
语法

多字段名用逗号分隔,创建唯一索引才添加 unique
建表时主键会自动创建主键索引,设置为unique的字段 会创建对应的unique的索引















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









