







正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项或罚项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。
最小化loss的同时,让w也最小化,L1可能会有部分w为0,L2会让部分w很小但不是为0
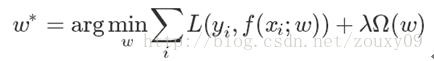
L1 regularization(lasso)
在原始的代价函数后面加上一个L1正则化项,即所有权重w的绝对值的和,乘以λ/n

L2 regularization(权重衰减)(ridge)
L2正则化就是在代价函数后面再加上一个正则化项:

C0代表原始的代价函数,后面那一项就是L2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整。
L2 和 L1 采用不同的方式降低权重:
- L2 会降低权重2。
- L1 会降低 |权重|。
因此,L2 和 L1 具有不同的导数:
- L2 的导数为 2 * 权重。
- L1 的导数为 k(一个常数,其值与权重无关)。
可以将 L2 的导数的作用理解为每次移除权重的 x%。如 Zeno 所知,对于任意数字,即使按每次减去 x% 的幅度执行数十亿次减法计算,最后得出的值也绝不会正好为 0。(Zeno 不太熟悉浮点精度限制,它可能会使结果正好为 0。)总而言之,L2 通常不会使权重变为 0。
可以将 L1 的导数的作用理解为每次从权重中减去一个常数。不过,由于减去的是绝对值,L1 在 0 处具有不连续性,这会导致与 0 相交的减法结果变为 0。例如,如果减法使权重从 +0.1 变为 -0.2,L1 便会将权重设为 0。就这样,L1 使权重变为 0 了。
L1 正则化 - 减少所有权重的绝对值 - 证明对宽度模型非常有效。
总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。















 7117
7117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









