









 本文详细介绍了C语言中结构体的内存对齐原理、偏移量计算、为何内存对齐重要以及如何设计内存效率高的结构体。此外,还涵盖了位段的概念、内存分配和在IP数据包处理中的应用。
本文详细介绍了C语言中结构体的内存对齐原理、偏移量计算、为何内存对齐重要以及如何设计内存效率高的结构体。此外,还涵盖了位段的概念、内存分配和在IP数据包处理中的应用。
目录
1.引入
来看这一段代码:
#include<stdio.h>
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
int i;
char c1;
char c2;
};
int main()
{
printf("%d\n", sizeof(struct S1));
printf("%d\n", sizeof(struct S2));
return 0;
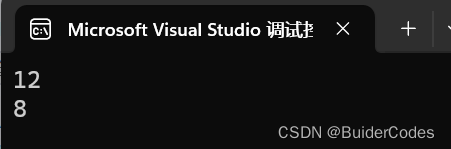
}这是一个计算结构体大小的代码,在学习结构体内存对齐之前可能会简单的认为结构体S1和S2的大小都是 1 + 4 + 1 = 6字节,然而程序实际运行的结果是:
2.offsetof介绍
offsetof是 C 语言标准库<stddef.h>中的一个宏,用于计算结构体中成员的偏移量。它的作用是返回某个结构体中特定成员的偏移量,以字节为单位。这在需要直接访问结构体成员时非常有用,尤其是在涉及底层编程或者实现数据结构时。
原型:
offsetof (type,member)
PS:偏移量
偏移量指的是在数据结构中,某个特定成员相对于结构体(或数组...)起始位置的位置差值,单位为字节。
offsetof需要接收两个参数,第一个(type)是结构体类型,第二个(member)是结构体名。
当我们使用offsetof来计算结构体每个成员的偏移量时
#include<stdio.h>
#include<stddef.h>
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
int i;
char c1;
char c2;
};
int main()
{
//printf("%d\n", sizeof(struct S1));
//printf("%d\n", sizeof(struct S2));
printf("%d\n", offsetof(struct S1, c1));
printf("%d\n", offsetof(struct S1, i));
printf("%d\n", offsetof(struct S1, c2));
return 0;
}发现运行结果如下:
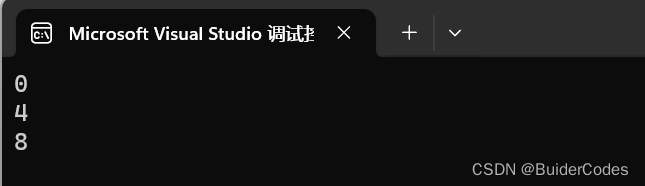
我们画一个内存的示意图,假设图中的0表示结构体S1在内存中的起始位置+

从偏移量为0的位置到偏移量为8的位置,结构体的大小应该是9字节,可是为什么sizeof返回的值是12呢?
3.结构体内存对齐
结构体成员不是按照顺序在内存中连续存放的,而是有一定的对齐规则:
结构体对齐的规则:
- 结构体的第一个成员永远放在相较于结构体变量起始位置偏移量为0的位置;
- 从第二个成员开始,往后的每个成员都要对齐到该成员的对齐数的整数倍处;
- 结构体的总大小,必须是最大对齐数的整数倍。
- 如果是嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对其数(含嵌套结构体的对齐数)的整数倍。
PS.
对齐数:结构体成员自身大小和默认对齐数的较小值,VS上默认对齐数默认是8,gcc没有默认对齐数,对齐数就是结构体成员自身大小;
比如在VS编译器中,变量i的默认对齐数为8,自身大小为4,min{8,4} = 4,所以对齐数就是4。
最大对齐数:所有成员的对齐数中最大的值。
所以,按照这套规则结构S1的大小为12字节就能被合理的解释了。为了遵循这套规则时为结构体分配的内存其实有一部分可能是浪费了的。
4.为什么要结构体内存对齐?
1. 平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。 原因在于,为了访问未对齐的 内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总体来说,结构体的内存对齐是拿空间来换取时间的做法。
举一个例子,对于32位机器(字长为32,一次读数据是32bit也就是4字节),假如没有内存对齐,要访问如图所示的i,需要读取两次才能访问到完整的i
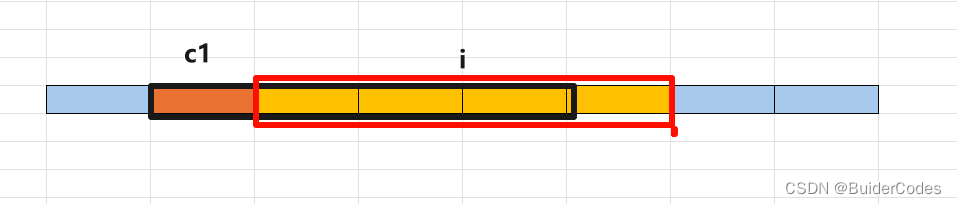
未对齐
而内存对齐之后,一次就能访问到变量i

对齐
5.如何设计一个内存浪费小的结构体?
由上面的例子可以看出,S1和S2类型的成员一模一样,但是S1和S2所占空间的大小有了一些区别。所以这就要求我们掌握一定方法,设计出一个内存浪费小的结构体。
措施:
1.让占用空间小的成员尽量集中在一起。
2.修改默认对齐数:
#pragma 这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
#pragma pack(1) //设置默认对齐数为1
#pragma pack() //还原默认对齐数
6.位段
位段(Bit Fields)是C语言中一种数据结构,用于有效地使用内存空间来存储小的位字段(即比特位)。它允许定义结构成员的宽度,从而控制结构的大小,并使程序员能够在结构中使用比特位作为数据成员。
使用位段可以有效地节省内存空间,尤其适用于对内存要求较为严格的系统。我们可以在结构中指定每个成员的位数,这样可以使得结构中的成员紧凑排列,减少了内存的浪费。
位段的声明和结构是类似的,但有两个不同点:
1.位段的成员必须是 int,unsigned int 或signed int ;
2.位段的成员名后边有一个冒号和一个数字。
#include <stdio.h>
// 定义一个包含位段的结构体
struct {
unsigned int isStudent : 1; // 学生标志,占用1位
unsigned int age : 7; // 年龄,占用7位
unsigned int gender : 1; // 性别,占用1位
} student;
int main() {
// 设置位段的值
student.isStudent = 1; // 表示是学生
student.age = 20; // 年龄为20
student.gender = 1; // 表示是男性
// 输出位段的值
printf("是否为学生:%d\n", student.isStudent);
printf("年龄:%d\n", student.age);
printf("性别:%d\n", student.gender);
return 0;
}需要注意的是,位段的长度不能超过其数据类型的大小。
7.位段的内存分配
1. 位段的成员可以是 int unsigned int signed int 或者是 char (属于整形家族)类型
2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
在VS2013平台下举一个例子:
//一个例子
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
如果位段中的成员在内存中从右向左分配标准且当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,选择舍弃剩余的位,那么可以做出一下推测:
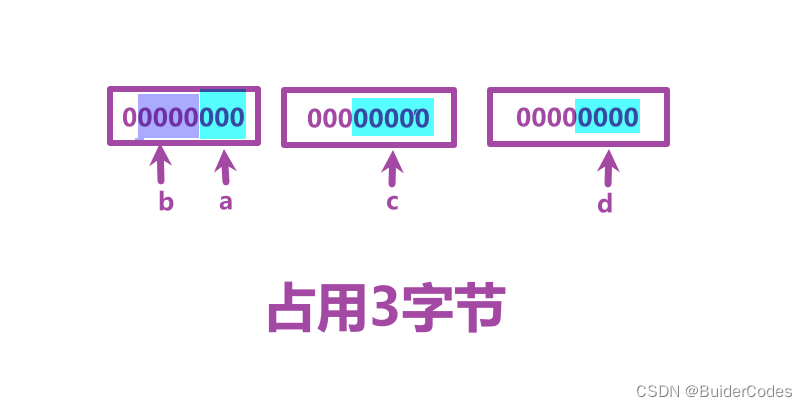
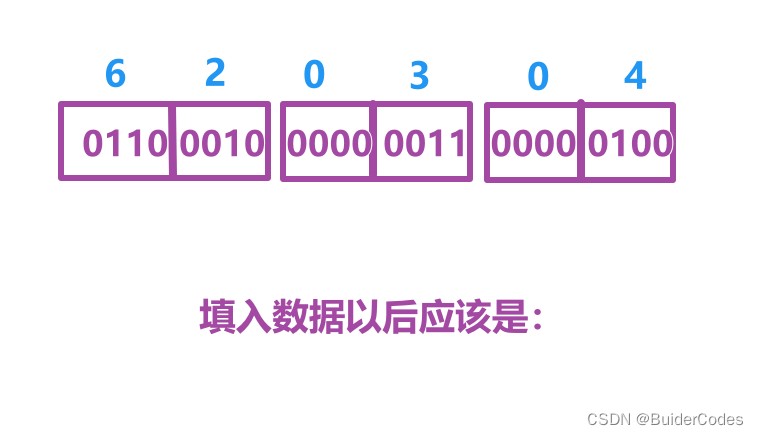
现在我们在内存中检查结果与猜想是否一致:
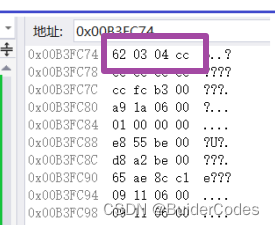
8.位段的应用
位段可以实现对IP数据包的高效处理和管理,从而更好地支持网络通信和数据传输。
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|Version| IHL |Type of Service| Total Length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Identification |Flags| Fragment Offset |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Time to Live | Protocol | Header Checksum |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source IP Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Destination IP Address |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options (if IHL > 5) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data (Payload) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
(IP数据包格式)















 8505
8505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









