






文章目录
前言
过拟合与欠拟合的概念
过拟合(overfitting)指的是模型在训练数据上表现良好,但在测试数据上表现不佳的情况。过拟合的主要原因是模型过于复杂,在训练数据上出现了“死记硬背”的情况,导致模型在未见过的数据上无法泛化。
欠拟合(underfitting)指的是模型无法在训练数据上得到很好的拟合,也无法在测试数据上得到很好的表现。欠拟合的主要原因是模型过于简单,无法捕捉到数据中的复杂关系。
一、如何解决过拟合问题?
原因:
-> 模型过于复杂(维度过高)
-> 使用了过多的属性,模型训练时包含了干扰项信息
解决方案:
-> 简化模型结构(使用低阶模型,比如线性模型)
-> 数据预处理,保留主成分信息(数据PCA处理)
-> 在模型训练时,增加正则化项
1.增加正则化
线性回归增加正则项方法如下:
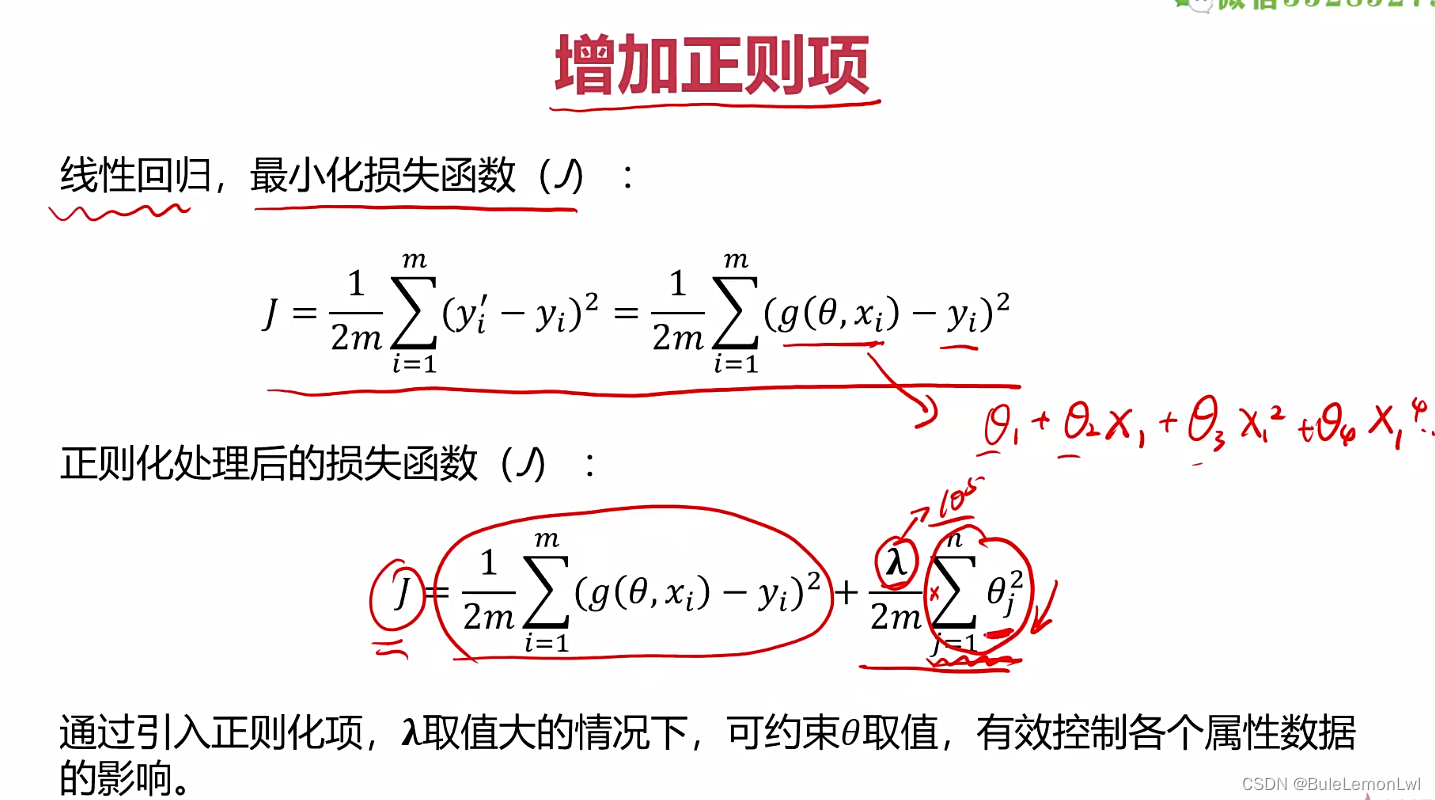
逻辑回归增加正则项如下:

二、数据分离与混淆矩阵
建立模型的意义,不在于对训练数据做出准确预测,更在于对新数据的准确预测
 对全数据进行数据分离,部分用于训练,部分用于新数据的结果预测
对全数据进行数据分离,部分用于训练,部分用于新数据的结果预测
分离训练数据与测试数据

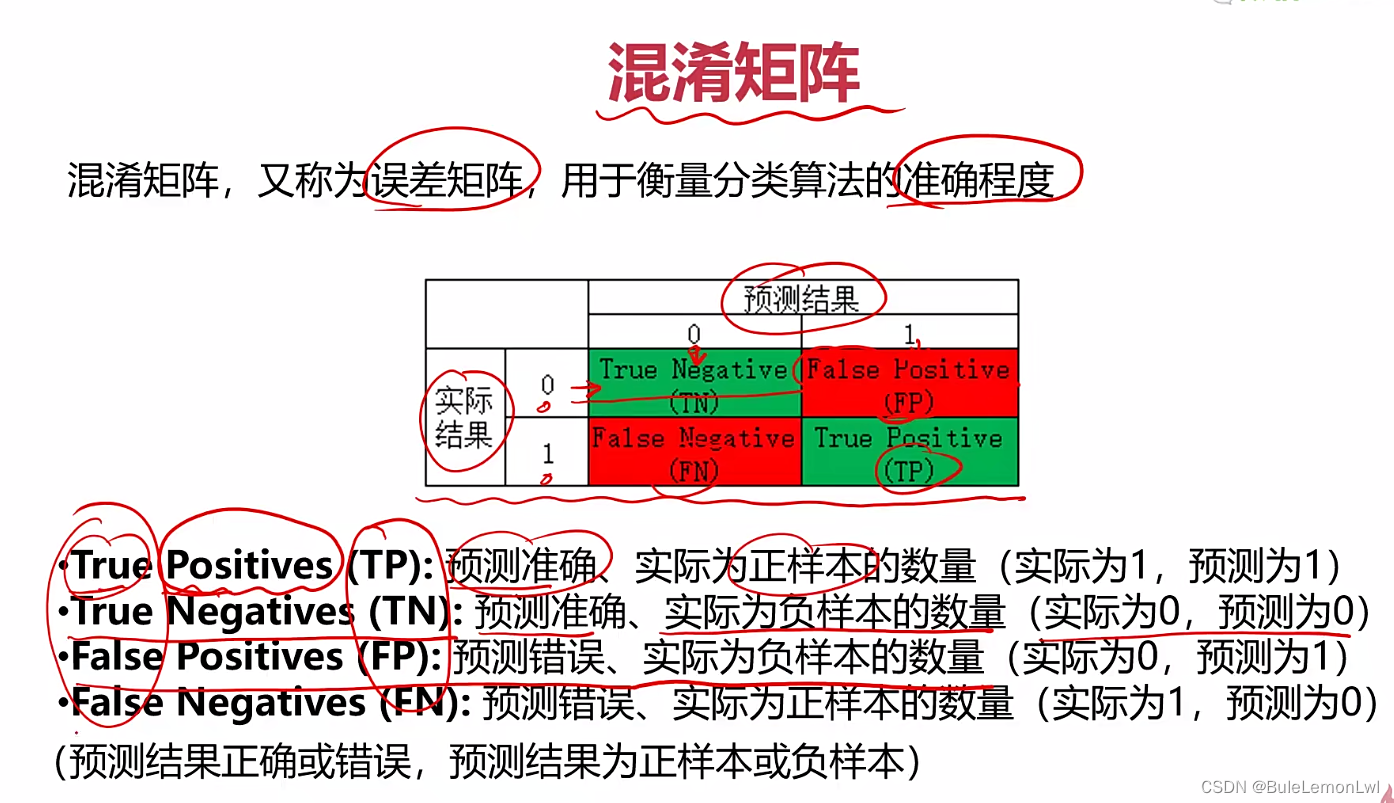
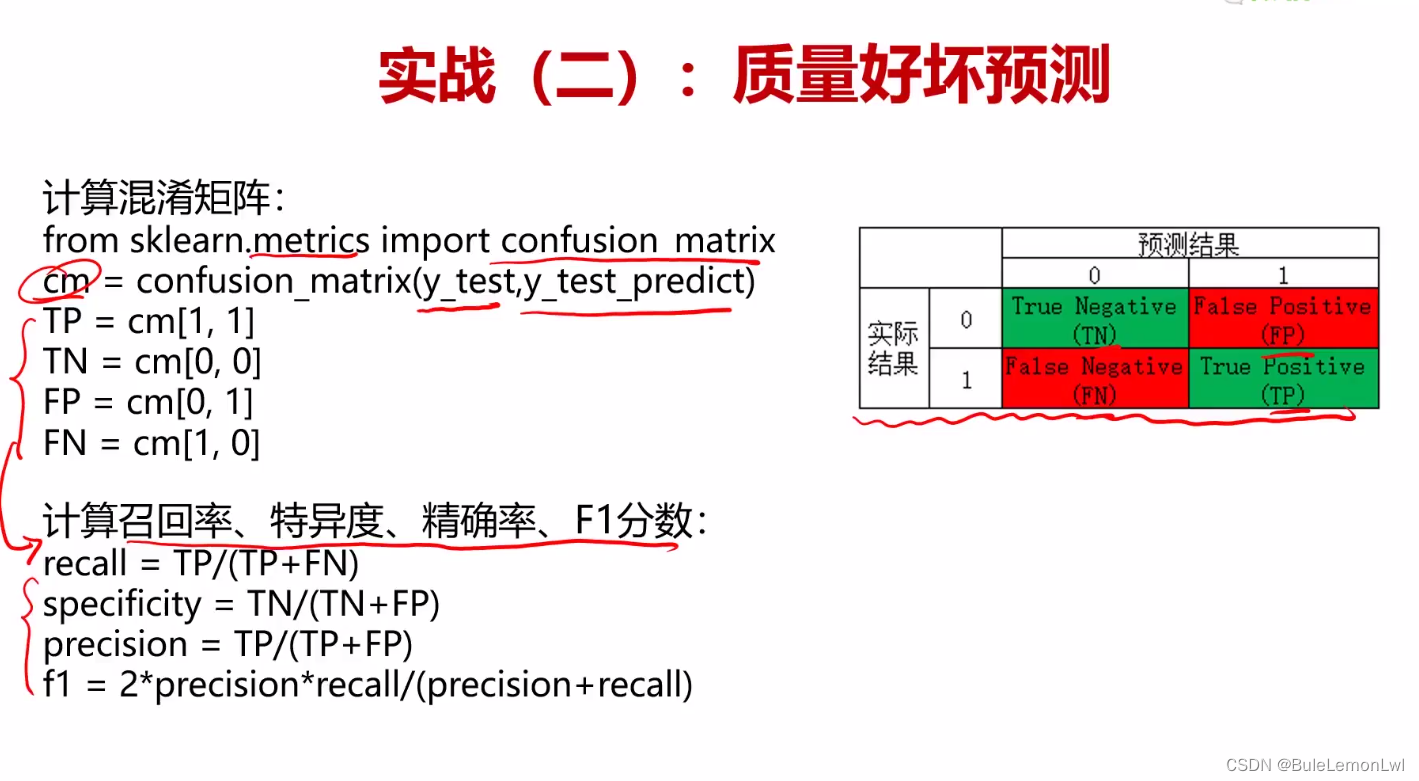
混淆矩阵
问题:使用准确率进行模型评估,可能会产生以下问题:当不同类别的样本差别很大时即使预测的结果完全偏于一方(数量较大的一方)也能有很高的准确率、 预测结果不均衡,如好的结果正确率100%,不好的结果准确率只有60%,但是总的准确率却挺高的、在某些情况下,不同类别的错误分类对应的代价是不一样的,使用准确率无法区分不同类别的重要性,无法评估模型在误分类方面的影响。。
解决方案:采用混淆矩阵,来计算更丰富的模型评估指标
混淆矩阵的特点:第一、提供了更全面的模型评估信息、第二、因为不同类别的错误分类对应的代价是不一样的而混淆矩阵可以计算出多样的模型表现衡量指标,从而更好选择模型
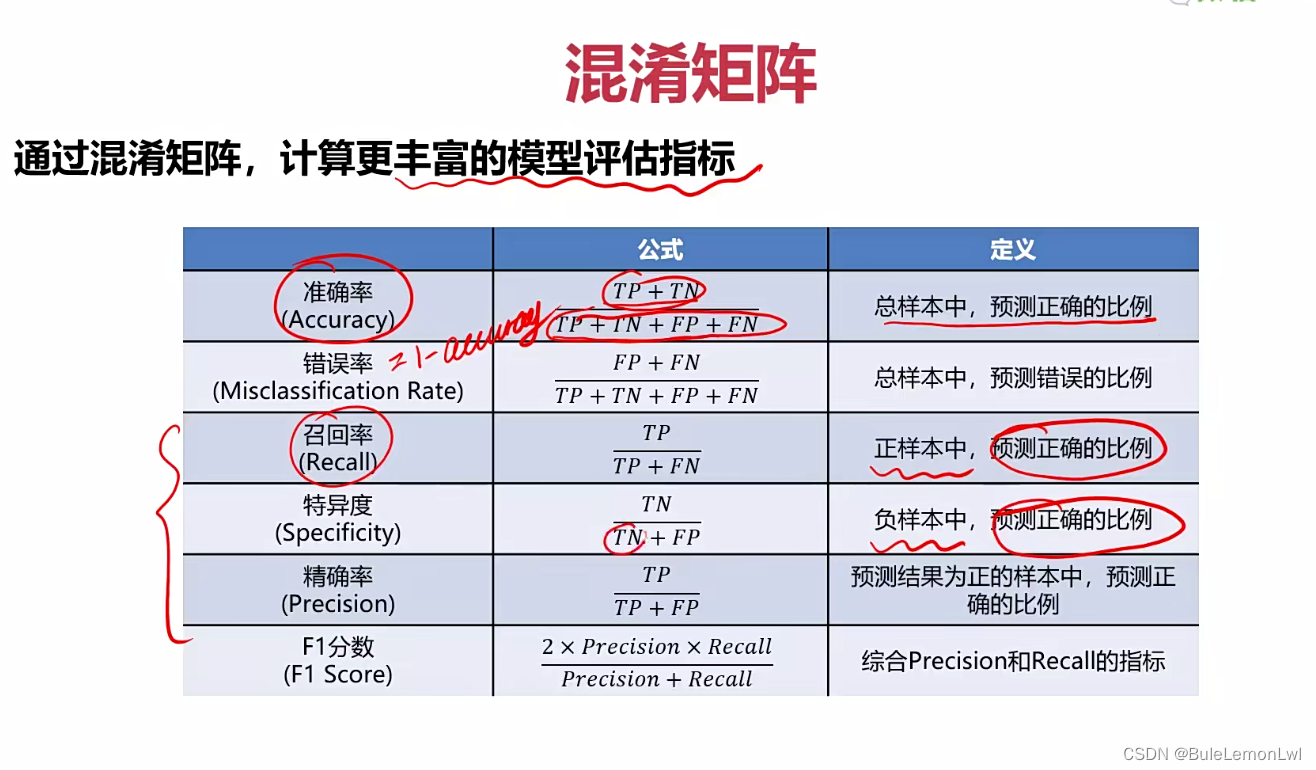

模型优化
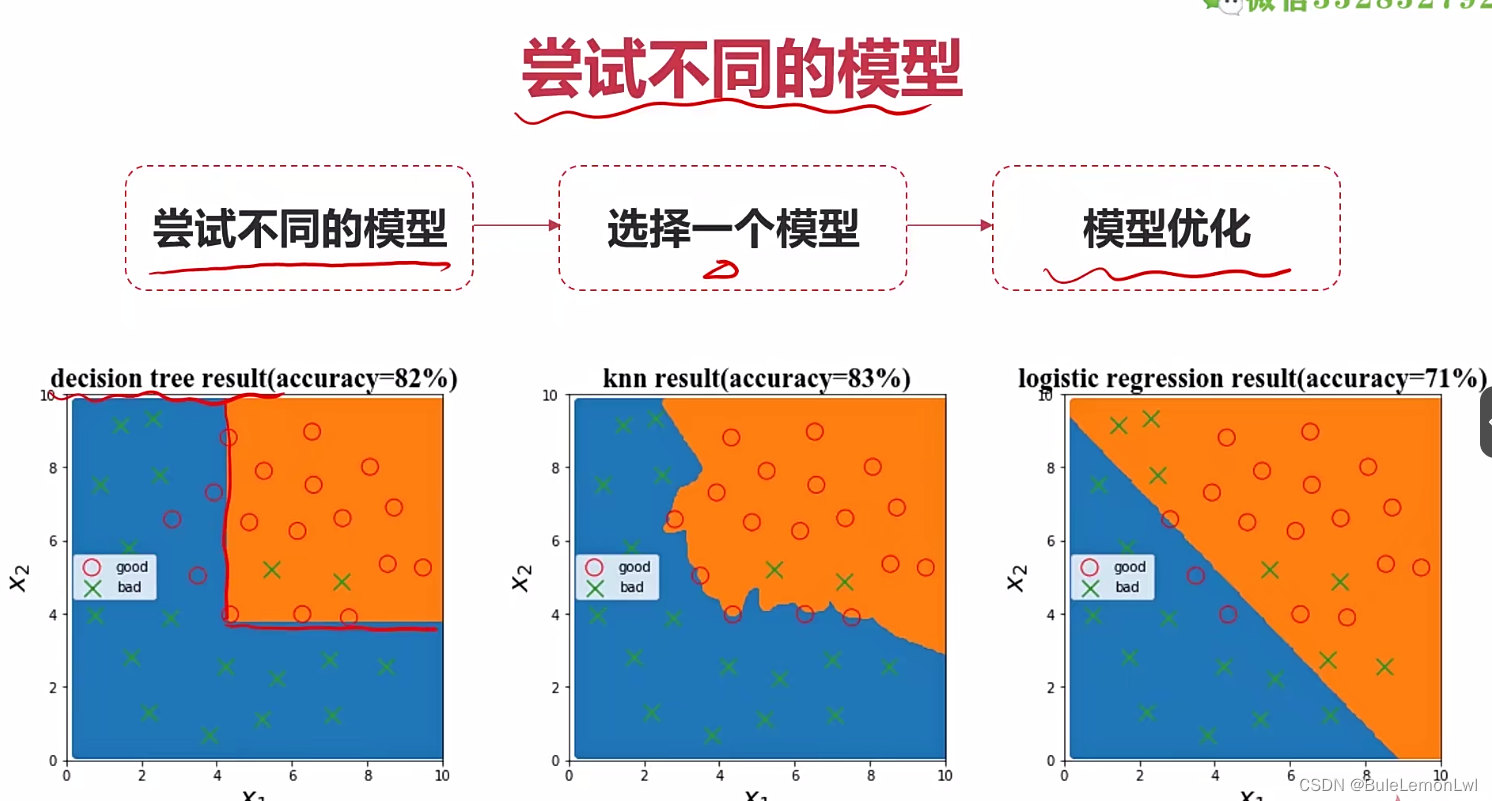
如何提高模型表现
主要思想:拿到一个问题我该如何去思考
第一步我应该选哪种算法?
第二步具体算法的核心结构或者参数如何选择?
第三步模型表现不佳,怎么办?
一个原则:数据的质量决定模型表现的上限
如何确保数据的质量:


模型优化:在确定模型类型后,如何让模型表现更好

模型关键参数的选择:
模型的复杂度会随着模型参数的改变而改变
->训练数据集准确率:随着模型复杂而提高
->测试数据集准确率:在模型过于简单或过于复杂的情况时下降
实战















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









