







摘要
可控的表到文本生成目的在于为表中需要强调的部分生成自然语言描述。目前(2022.05)的SOTA仍采用序列到序列的生成方法,该方法仅将表捕获为线性结构,并且在表布局改变时表现得很脆弱。我们试图通过(1)有效的表达表中内容块的关系,(2)使得我们的模型对内容不变的结构转换具有鲁棒性这两个改进来超越原本的范式。因此,我们提出了等效方差学习(equivariance learning)框架LATTICE,它使用结构感知的自注意力机制对表进行编码。这个机制把全自注意力结构剪枝成一个顺序不变的图注意力结构,该图注意力捕获属于同一行或同一列单元格的连通图结构,并从结构角度区分相关和不相关单元格。我们的框架还修改了位置编码机制,以保留同意单元格的tokens的相对位置,但强制保留不同单元格之间的位置不变性。我们的技术可以免费插入到现有表到文本生成模型中,并改进了T5-base模型以在ToTTo和HiTab数据集上提供更好的性能。此外,在ToTTo的harder版本上,我们保证了普通版本的性能,而以前的SOTA即使具有基于转换的数据增强,也会出现显著的性能下降。
1.简介
表到文本生成旨在为表中的内容和相关结论生成自然语言描述。它不仅使无处不在的表格数据更容易被发现和访问,而且还支持表格语义检索、推理、事实检测、表辅助的问答等下游任务。虽然丰富多样的事实可以在表格中呈现,但受控的表到文本生成任务(为表格的突出显示子部分生成重点文本描述)最近引起了广泛关注。
先前关于受控的表到文本生成研究通常采用序列到序列的生成方法,该方法仅将表捕获为线性结构。然而,表格布局虽然被先前的研究忽略了,但从两个角度来看,它是生成的关键。首先,表格布局指出了共同呈现事实的单元格之间的关系,然而线性化的表格并不能简单地捕获这些关系。例如,如果我们将下图中的第一个表按行线性化,Wai Siu-bo同时与Royal Tramp和King of Beggers相邻,以至于不清楚这个角色属于哪部电影。

其次,相同的内容可以等效地表达在不同布局的表格中。虽然线性化简化了布局表示,但当表布局改变时,它会导致脆弱的生成。图中为两张内容相同但布局不同的表,由T5生成的两张表在很大程度上不一致。
在本文中,我们通过结合结构感知和转换不变性两个特性来改进受控表到文本生成系统。结构感知(structure -awareness)试图理解由表结构指示的单元格关系,对于捕获上下文化的单元格信息至关重要。转换不变性(Transformationinvariance)旨在使模型对内容不变的结构转换(包括转置、行变换和列变换)不敏感,这对模型的鲁棒性至关重要。然而,将结构感知和转换不变性整合到现有的生成神经网络中并非易事,特别是在尽可能保留预训练模型的生成能力时。
我们使用等效方差学习框架,即布局感知和转换不变的受控表到文本生成(Layout Aware and TransformaTion Invariant Controlled Table-to-Text GEneration,LATTICE),在预训练的生成模型上加强表布局意识和内容不变结构转换的鲁棒性。LATTICE使用变换不变图掩码机制对表进行编码。
它用顺序不变的图注意力机制来代替全注意力机制,用以捕获相同行或相同列的单元格的连接图以及从结构视角的相关或不相关单元格的差异。LATTICE还修改了位置编码机制,以保留同一单元格内标记的相对位置,但强制不同单元格之间的位置不变性。
我们的贡献有三方面。首先,我们提出了精确且鲁棒的受控表到文本生成系统的两个基本属性,即结构感知和转换不变性。其次,我们证明了我们的变换不变图掩码技术如何加强这两个属性,并有效地增强一组具有代表性的基于transformer的生成模型,例如T5-base模型,以实现更好的泛化性和准确的生成。第三,除了在ToTTo和HiTab基准上的实验之外,我们还在ToTTo的harder版本上评估了我们的模型,特别关注对内容不变结构转换的鲁棒性。
2.方法
在本节中,我们将首先介绍内容不变的表转换、基本模型和受控表到文本生成的输入格式(§2.1)。然后我们介绍了LATTICE中的变换不变图掩码技术如何使模型具有结构感知和变换不变的技术细节(§2.2)。最后,我们提出了两种增强变换不变性的备选技术,并与LATTICE(§2.3)进行比较。
2.1 预备知识
- 内容不变的表转换
表按行和列组织和显示信息。一条信息以单元格(带有标题)的形式呈现,单元格是表的基本单元。行和列是高级单位,表示单元格之间的关系,并结合起来表示更全面的信息。我们讨论可以在表上进行的两类转换,如图2所示。
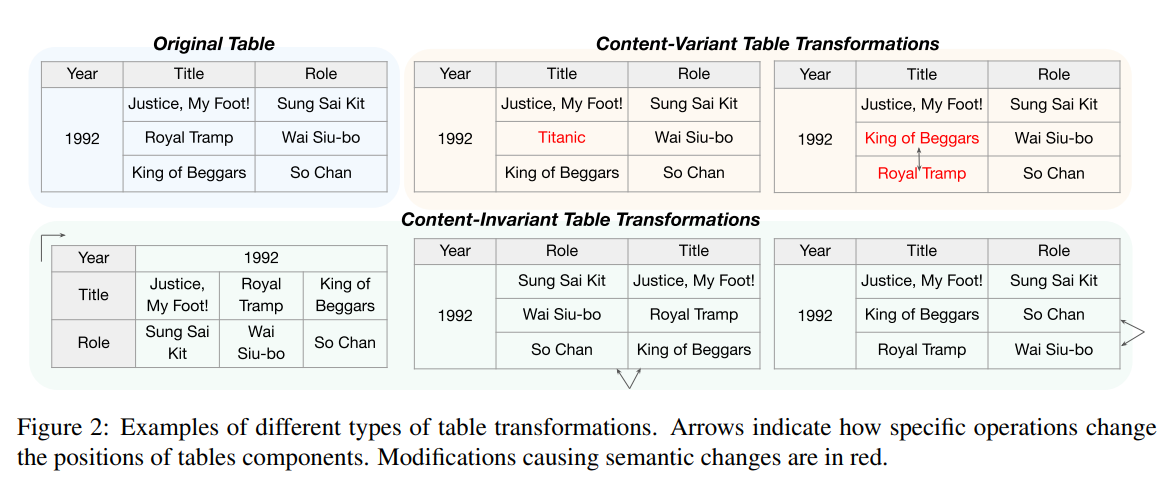 首先,内容变化的转换修改或交换不同行或列中的部分单元格,因此改变了表的语义。在这种情况下,创建新的表格内容来表示与原始表不一致的信息。其次,内容不变的转换由不影响内部内容的操作,同一行或同一列的组合,表示的是语义上相等的子集。具体包括转置、行变换和列变换。通过执行这些操作的一种或多种,我们可以在不同的表布局中表示相同的信息。
首先,内容变化的转换修改或交换不同行或列中的部分单元格,因此改变了表的语义。在这种情况下,创建新的表格内容来表示与原始表不一致的信息。其次,内容不变的转换由不影响内部内容的操作,同一行或同一列的组合,表示的是语义上相等的子集。具体包括转置、行变换和列变换。通过执行这些操作的一种或多种,我们可以在不同的表布局中表示相同的信息。 - 基本模型
预训练的基于transformer的生成模型在各种文本生成任务上实现SOTA性能(Raffel等人,2020;刘易斯等人,2020)。为了使这种模型能应用到表到文本的生成,先前的工作提出将表线性化成文本序列(Kale和Rastogi, 2020;Chen et al., 2020b;Su等人,2021)。我们的方法LATTICE是模型不可知的,可以被纳入到任何这样的模型中。继Kale和Rastogi(2020)之后,我们选择了一个表现最好的模型家族T5 (Raffel et al., 2020)作为我们的基本模型。这个家族的模型在一系列监督和自监督的文本到文本任务上进行联合预训练。模型可以通过在输入前添加特定于任务的前缀来在不同的任务之间切换。我们的实验指出,基本模型对于内容不变的表转换是脆弱的,并且只能捕获有限的布局信息。 - 输入格式
之前的工作(Kale和Rastogi,2020;Chen et al., 2020b;Su等人,2021)线性化
(突出显示)基于行和列索引的表单元格。输入序列通常从表的元数据开始,例如页标题和节标题。然后,它按行从左上单元格遍历到右下单元格。每个单元格的标题可以作为单独的单元格处理,也可以附加到单元格内容中。每个元数据/单元格/头部都用特殊的标记分开。这种线性化过程适合文本到文本生成模型的输入,但会丢弃表的大部分结构信息(例如,同一列中的两个单元格可以用序列中不相关的单元格分隔,而相邻行中的最后一个单元格和第一个单元格可以相邻,尽管它们是不相关的),并且对内容不变的表转换非常敏感。
2.2 转换不变的图掩码
LATTICE通过修改Transformer编码器架构来实现等值学习。它还提高了基本模型捕获突出显示的表格内容结构的能力。具体来说,我们在基本模型中加入了结构感知的自注意机制和转换不变的位置编码机制工作流程如图3所示。
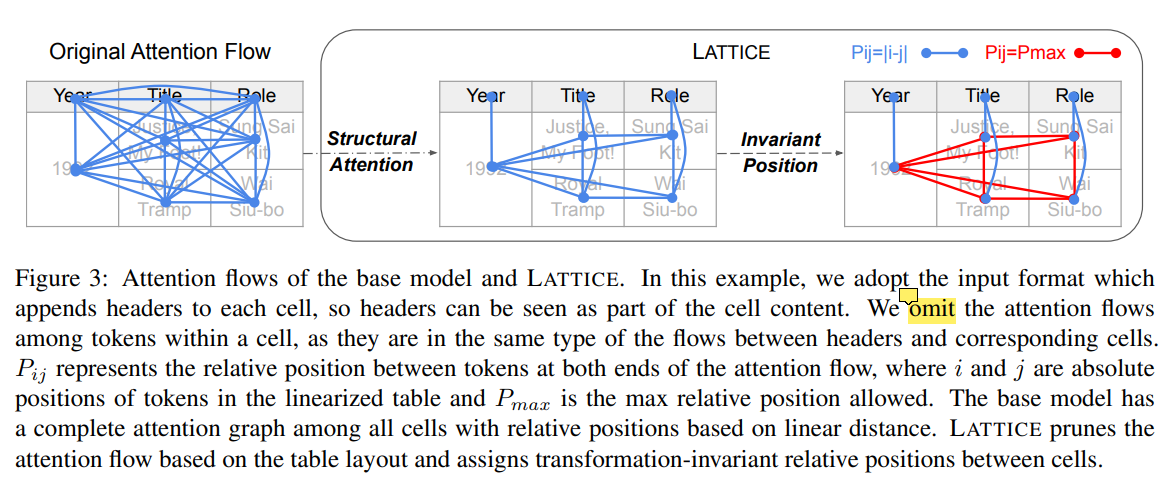
- 结构感知的自注意力机制
Transformer采用自注意力来聚合输入序列中所有token的信息。注意流形成一个连接每个标记的完整图。这种机制适用于序列建模,但不能捕获表状结构。非线性的布局结构反映了单元格之间的语义关系,因此应该被自注意力捕获。
我们通过修剪注意流来合并结构信息。根据表中信息排列的性质,不是同一行或同一列中的两个单元格在语义上没有关联,或者至少它们的组合不能直接表达该表想要传达的信息。直观地说,这些单元格的表示不应该直接相互传递信息。在LATTICE中,从注意图中移除结构不相关的单元格标记之间的注意流,即使他们在元数据中,或者在每个单元格内以及元数据和每个单元格之间都被保存。这样,我们也保证了自注意力机制的变换不变性,因为在注意力图中,同一行或同列的相关单元格都是以无序的方式链接的。容易发现,对于任何一个单元格,在应用任何内容不变操作后,注意力图中的链接将保持不变。 - 转换不变的位置编码
当计算每对标记之间的注意力得分时,基本模型将它们在线性化表序列中的相对位置作为有影响的特征。具体来说,从第 i i i个token到第 j j j个token的注意力流与相对位置 P i j = ∣ i − j ∣ P_{i j}=|i-j| Pij=∣i−j∣配对。这很容易导致不同单元格之间的位置偏差,因为序列中的相对位置不能完全反映表中单元格之间的关系。而且,同一令牌对之间的相对位置会随着表布局的改变而改变,这就是图1所示产生不一致的根源。
如§2.1所述,对于给定的单元格,它与同行或同列的其他单元格的关系应同等考虑。很自然的根据给同行或者同列(tokens)单元格分配相同的相对位置,无论它们在线性序列中的距离有多远。同时,我们保留同一单元格(或元数据)内标记的相对位置。具体地说,输入序列中第i个令牌和第j个令牌之间的相对位置为
P i j = P j i = { ∣ i − j ∣ , if in the same field P max , otherwise P_{i j}=P_{j i}= \begin{cases}|i-j|, & \text { if in the same field } \\ P_{\max }, & \text { otherwise }\end{cases} Pij=Pji={∣i−j∣,Pmax, if in the same field otherwise
其中“same field”意味着两个标记来自同一个单元格,或者它们都来自元数据。而 P max P_{\max } Pmax是允许的最大相对位置。因此,LATTICE表示单元格(和元数据)的方式对它们在序列中的相对位置是不变的。由于内容不变的表转换不会改变表中单元格之间的关系(即两个单元格是否来自同一行或同列),这种位置编码机制是转换不变的。 - 训练和推理
在获得结构感知和变换不变的表表示法后,LATTICE进行与基础模型类似的训练和推理。给定线性化的表格 T i T_i Ti,以及其布局结构 S i S_i Si,还有目标句 Y i = { y 1 i , y 2 i , … , y n i i } Y_i=\left\{y_1^i, y_2^i, \ldots, y_{n_i}^i\right\} Yi={y1i,y2i,…,ynii},训练最小化负对数似然。对于N个样本的数据集(或批次),损失函数为 L = − 1 N ∑ i = 1 N ∑ j = 1 n i log P ( y j i ∣ y < j i , T i , S i ) L=-\frac{1}{N} \sum_{i=1}^N \sum_{j=1}^{n_i} \log P\left(y_j^i \mid y_{<j}^i, T_i, S_i\right) L=−N1i=1∑Nj=1∑nilogP(yji∣y<ji,Ti,Si)
在推理过程中,模型逐个标记生成一个句子,每次输出一个词汇表的分布。
替代技术
除了由变换不变图掩码实现的等值方差学习之外,我们还提出并比较了两种替代技术。
- 布局不可知的输入
第一种技术是将输入序列调整为内容不变的表转换。一种简单的方法是按任意顺序重新排列headers和单元格,而不是基于表布局(例如按照字母顺序),以构成一个序列。分隔单元格和headers的特殊标记也应该不包括任何布局信息。因此,这种输入格式会丢失所有关于表布局的信息,以确保转换不变性。 - 数据增强
第二种技术是通过内容不变表转换进行数据扩充。该技术通过训练数据的不同布局来扩充表格,力求通过暴露基本模型给更多不同的训练实例以增强其鲁棒性。
我们的实验系统地将这两种技术与§3.3中的变换不变图掩码进行了比较,揭示了从神经网络结构的角度直接执行等效方差学习如何比使用布局不可知输入或数据增强获得更好的性能和鲁棒性。
3. 实验
在本节中,我们将在两个基准数据集上进行实验。首先,我们介绍了数据集、基线、评估指标和我们的实现(§3.1)的细节。然后,我们展示了LATTICE的整体性能(§3.2)。之后,我们在引入内容不变的扰动的harder版本ToTTo数据集上分析了模型的鲁棒性(§3.3)。最后,我们对变换不变图掩码的部分进行了消融学习(§3.4)。
3.1 实验设置
- 数据集
在ToTTo和HiTab数据集上评价我们的模型,细节如下:- ToTTo:一个apach v2许可下发行的英文数据集,数据集专门用于可控的表到文本生成。它由83,141个维基百科表格组成,120,761/7,700/7,700个句子(即表格数据的描述)用于训练/验证/测试。测试集中的目标句子是不可获得的。每个句子都与表中的一组突出显示的单元格配对。每个表都有元数据,包括其页面标题和节标题。验证集和测试集可以进一步划分为两个子集,即重叠(overlap)和非重叠(non-overlap),这两个自己的划分依据是看该表是否存在在训练集中。
- HiTab:一个微软数据计算使用协议(C-UDA)下发行的英文数据集。它既用于可控的表到文本生成,也用于基于表的问答,特别关注分层表。它包含3597个表,包括来自统计报告和维基百科的表,形成10,686个样本分布在训练集(70%)、验证集(15%)和测试集(15%)。每个样本都包含一个目标句和一个带有突出显示的单元格和分层标题的表格。
- 评价指标
我们采用三种广泛使用的文本生成评估指标。BLEU是基于n-gram共现的文本生成最常用的指标之一。在之前的工作中,我们使用了常用的BLEU-4 。PARENT是一种数据到文本评估的指标,同时考虑了引用和表格。BLEURT是一种基于BERT的文本生成的学习评估指标。根据先前的研究,我们使用这三个指标在ToTTo上,而在HiTab上的只使用前两个指标。 - 基线
- Pointer-Generator(指针生成):一个基于LSTM的encoder-decoder模型,使用注意力机制和copy机制,最先为了文本摘要提出。
- BERT-to-BERT:一个基于Transformer的encoder-decoder模型,encoder和decoder都是用BERT初始化的。
- T5:一个基于Transformer的预训练模型,在文本到文本的任务上进行预训练,在线性表上进行微调,从而达到SOTA的性能。
上述基线在ToTTo上的表现都可以在官方排行榜上找到,除了T5-small和T5-base,因为我们在Kale等人的验证集上的结果进行改动,并将隐藏测试集上的预测提交到排行榜。对于HiTab,我们使用Cheng等人提出的线性化处理在T5和LATTICE运行。其余的极限结果来自Cheng的这篇论文。
- 实验细节
我们采用了Raffel等人的权重。具体来说,使用了T5-small和T5-base,在微调阶段,我们的batch size为8,学习率为 2 e − 4 2 e^{-4} 2e−4,输入序列的长度限制在512以内(为了适配预训练模型的限制),LATTICE不再新增任何参数,所以LATTICE(T5-base)有220百万参数,(T5-small)有60百万参数。对于ToTTo,用beam size为4来生成句子,并且最多有128tokens。对于HiTab,用beam size 为5来生成句子,并且最多有60个token。实验用Pytorch和Transformer实现。我们使用GeForce RTX 2080 GPU的商用服务器上运行实验。大约花了半个小时训练LATTICE (T5-small) 每10000步,约1小时训练LATTICE (T5-base) 每10000步。考虑到两个数据集的大小不同,我们训练ToTTo用15000步,在HiTab上用20000步。ToTTo验证集和HiTab上的结果是多次运行的平均值。
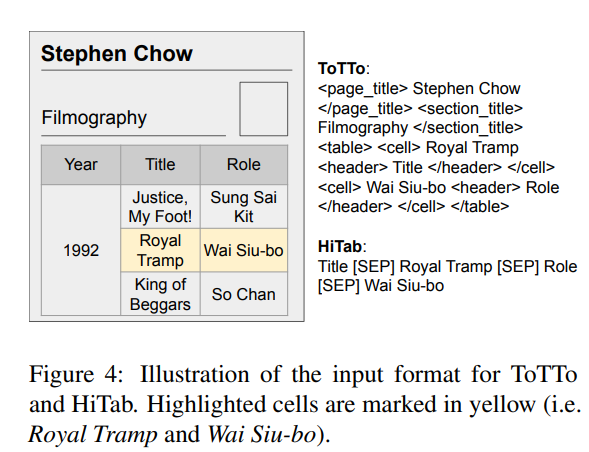
我们在ToTTo和HiTab上使用的输入格式不同,如下图所示。因为两个数据集中表和注释是不同的。对于ToTTo我们采用线性处理,具体来说,文本序列由页面标题、节标题、表头和单元格组成。每个单元格可以与多个行标题和列标题相关联。使用特殊标记来表示每个字段的开始和结束。我们的行标题和列标题的标记是一致的。对于HiTab,文本序列由高亮显示的单元格及其标题组成。使用通用分隔符标记[SEP]。虽然我们的模型可以在任何输入顺序下实现一致的相同性能,但我们采用了与布局不可知输入格式相同的字典结构(§2.3),以避免由于截断和特殊标记引起的不确定性。
3.2 实验结果
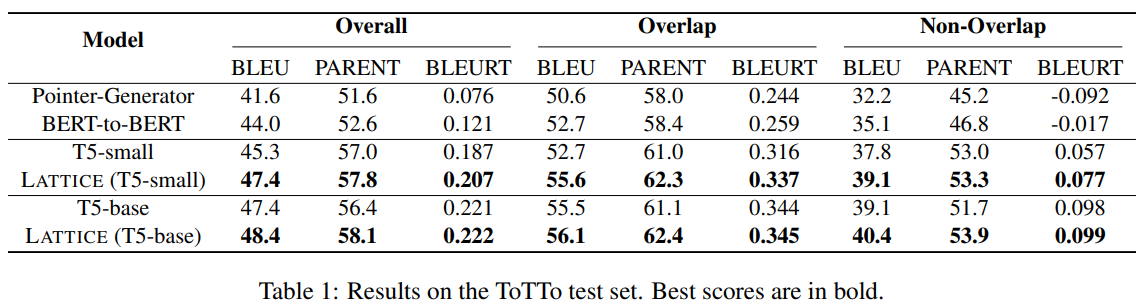
下表展示了模型在ToTTo上的表现。

3.3 鲁棒性评价
为了进一步评估模型对表上内容不变扰动的鲁棒性,我们创建了ToTTo验证集的harder版本,其中每个表都被按行变换、按列变换和表转置的组合打乱。模型不能再同时出现在训练集和验证集中的表布局受益。我们基于T5比较了四种方法,包括基础版本、用布局扰动的增强T5版本或者用数据增强的T5版本,以及融入了LATTICE的T5。
根据表3所示的结果,当引入内容不变扰动时,原本的T5模型面临严重的性能下降。总的来说,T5-small的BLEU分数下降3.4,T5-base的BLEU分数下降4.5。我们还观察到重叠子集上的性能下降比非重叠子集上的性能下降更大。这表明,T5模型的性能增益在某种程度上是由于它们对训练集中存在的一些表的记忆,而这些是脆弱的,不可泛化的。应用布局不可知的输入格式,即按字典顺序而不是单元格索引顺序线性化表格,可以确保模型返回稳定的预测,但由于结构信息的丢失,导致整体性能较差。毫无疑问,与布局无关的输入会导致性能下降。
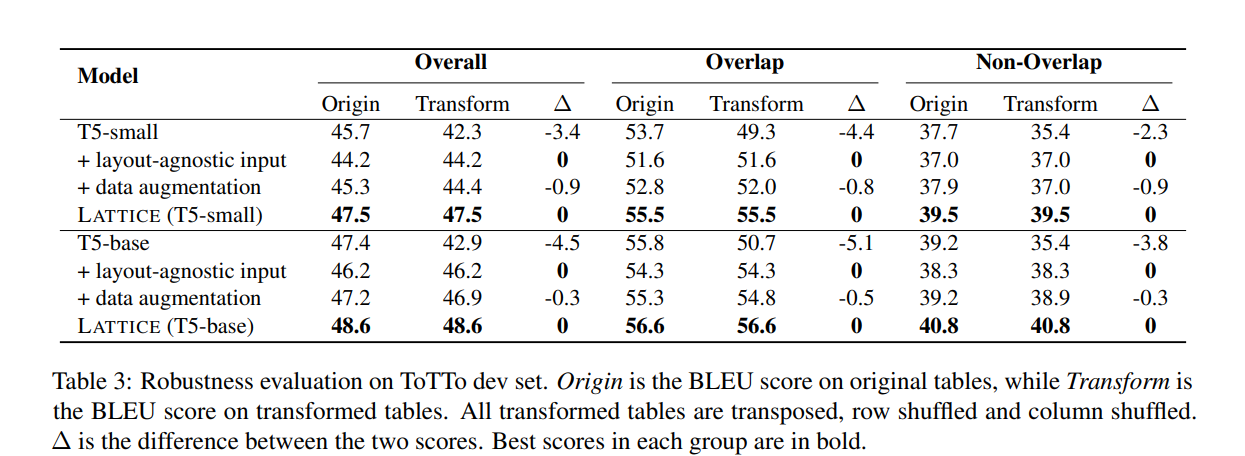
消融学习
为了帮助理解两个关键机制在变换不变图掩码中的作用,我们在表4中给出了消融的研究结果。

- 结构感知的自注意力机制
-我们研究了结构意识自我注意的有效性。与原始的(全连接的)自我注意相比,通过修剪注意流来整合结构信息可以使整体表现提高1.3个BLEU点。在两个子集上的详细分数表明,训练期间seen和unseen表格都可以从结构信息中受益。在两个子集上的一致性提高表明,结构感知自注意提高了模型捕捉单元格关系的能力,而不是记忆表格的能力。 - 转换不变的位置编码
我们进一步测试了转换不变位置编码的有效性。我们观察到,虽然该技术主要是为了确保模型对布局变化的鲁棒性而设计的,但它可以为整体性能带来0.5个BLEU点的额外改进。改进主要集中在重叠子集上。我们将其归因于训练集和验证集中的同一个表可能有不同的突出显示单元格,因此记忆训练集中的布局信息会阻碍域内泛化。
4. 相关工作
- 表到文本生成(Table-to-text Generation)
表到文本生成寻求为表格数据生成文本描述。与文本到文本生成相比,表到文本生成的输入是半结构化数据。早期的研究使编码器-解码器框架适应数据-文本生成,编码器聚集细胞信息(Lebret et al.,2016;怀斯曼等人,2017;Bao等人,2018)。随后,大规模预训练的序列到序列Transformer模型取得了成功(Raffel等人,2020;Lewis等人,2020),最近的SOTA系统将这些模型应用于表到文本生成(Kale and Rastogi, 2020;Su等人,2021),其中输入表被线性化为文本序列。
一个表格可以包含足够的信息,它并不总是能够用一句话概括。一行工作通过关注表格中的关键信息来学习生成选择性描述(Perez-Beltrachini和Lapata, 2018;Ma等人,2019)。然而,当关注表的不同部分时,可以从一个表中引入多条语句。为了弥补这一差距,Parikh等人(2020)提出了受控的表到文本生成,允许生成过程根据不同的突出显示单元格做出不同的反应。突出显示的单元格可以在任何位置,任意的数量,简单的线性化,这些都会破坏布局结构,阻碍单元格之间的关系被捕获,因此导致不可靠或产生幻觉的描述。
一些先前的研究引入了结构信息来提高表到文本生成的模型性能,要么通过合并标记位置,要么通过聚合行和列级信息。然而,现有的方法都不能直接应用于预训练的基于transformer的生成模型,特别是当我们想要确保模型对内容不变表转换的鲁棒性时,我们的方法同时强化了结构感知和转换不变性。 - 等变表示学习(Equivariant Representation Learning)
等效方差是一种广泛存在于现实任务中的先验知识。早期研究表明,结合等值方差学习可以提高视觉感知模型对几何变换引起的湍流的鲁棒性,例如实现图像的平移、旋转和尺度等值方差。这些任务的输入是非结构化的信息,神经网络中加入了几个几何不变的操作来实现上述的等方差特性。例如,卷积神经网络(cnn)在本质上对翻译是等变的。谐波网络和球面cnn将cnn的等效方差扩展到旋转。群等变卷积网络对包括平移、旋转和反射在内的更多空间变换都是等变的。尽管如此,这些几何不变的技术都不能直接应用于基于transformer的生成模型,以确保结构化表格数据(部分)的等值方差,这正是这项工作的重点。我们的方法在表到文本生成中实现了针对内容不变表转换的等变中间表示。
其他一些工作,虽然没有明确使用等变模型结构,但试图通过在训练数据中增加更多样化的变化来实现等变表示,尽管这个模型可以从涉及内容转换不变的更多样化的输入中受益,但这个策略仍有两个缺点。具体来说,增强数据虽然为训练引入了大量的计算开销,但永远不足以保证真正的等值方差。相比之下,我们的方法通过神经网络设计保证了等效方差,并且不引入任何训练开销。
5. 总结
我们提出了LATTICE,一种结构感知的等值方差学习框架,用于受控的表到文本生成。我们的实验结果验证了结构感知和转换不变性的重要性,这是LATTICE中强制执行的两个关键属性,对表格内容的精确和健壮的描述生成具有重要意义。所提出的属性和等值方差学习框架很好地与表中组织的信息的性质保持一致。未来的研究可以考虑将结构感知的等值方差学习框架扩展到其他数据到文本生成任务,表格推理或检索任务,以及对文本和表格数据的预训练表示。














 9862
9862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









