







家人们!数字人已经很普及了!但每次HeyGen的更新,都会推动1次数字人发展小浪潮,想起上次HeyGen的更新,转眼已过了小半年
都以为数字人发展快到天花板时,一瞬间就让之前的AI数字人变成了“传统技术”!
就在本月,代表最新数字人生产力的HeyGen,官网的“Photo Avatar”居然悄悄又丢王炸升级了!
只需几张照片+1句话,无需上传录制视频,直接生成高质量AI动态数字人视频。
AI数字人已成为传统?丢1张图片直接做AI数字人!HeyGen重磅更新!无需录视频!
观看更多转载,AI数字人已成为传统?丢1张图片直接做AI数字人!HeyGen重磅更新!无需录视频!赤辰AI实操记已关注分享点赞在看已同步到看一看写下你的评论
“Photo Avatar”这个功能升级后,实际上是“图片开口说话”的王者版,之前这个功能生成的视频样式只有嘴巴动及头部有轻微动的效果,身体都是固定不动的,视觉上非常僵硬。
而HeyGen此次升级后,就只需从几张照片或简单的文本提示,无需拍摄,直接可创建一个AI数字人分身。
创建好的数字人分身,可以随意改变背景环境,服装或姿势。告别纯图说话,生成很逼真的外观,有非常完美的外观及自然的动作。
话不多说先上教程,教程最后,我会给大家做些数字人领域发展预判和展望!
接下来手把手演示具体操作流程:
进入Heygen官网,在左侧导航栏中,选择“Avatars”功能,点击“Photo Avatar”-“Create Photo Avatar”。
直达网址:https://app.heygen.com/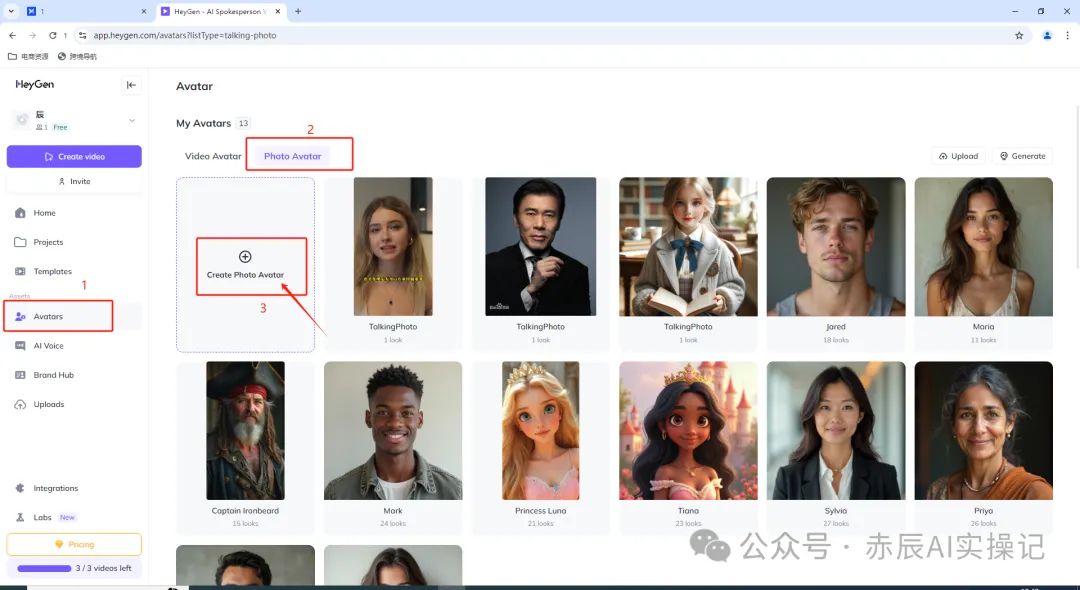
接着选择生成数字人方式,“Upload”代表可以选择上传图片生成Avatar,“Generate”则是发送一句描述词即可在线生成Avatar。
两个形式分别给大家演示
1.Upload
其实这一步的生成原理,系统将用户上传的真人图片进行人脸LORA模型训练。
点击Upload后,需要上传PNG、JPG或WebP文件格式的个人多角度自拍照,10-20张图片数量,最大200MB。
照片要求:个人近期自拍照,从不同角度近景、全身照片,表情(微笑、中立、严肃)和多种服装。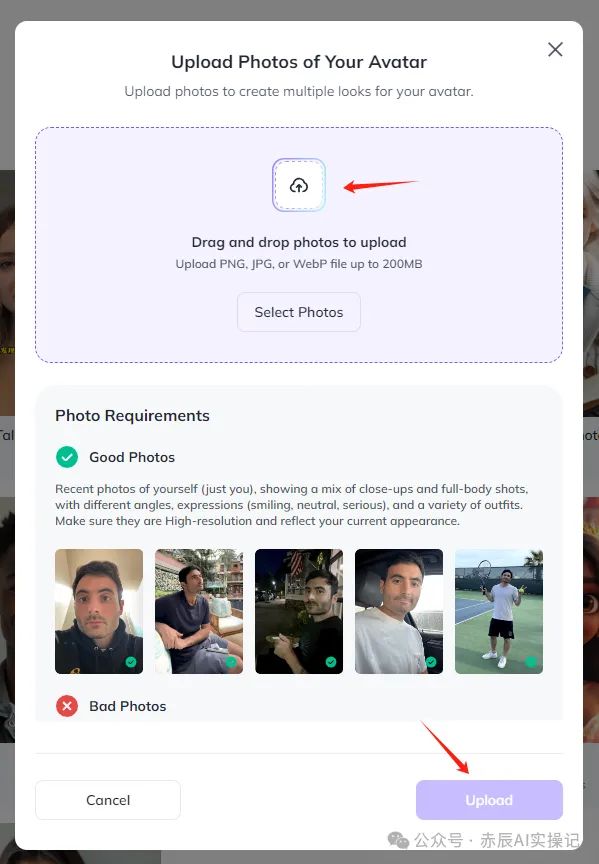
上传完后,将会进行初级的照片审核,点击“Continue”。
接着填写创建信息,例如名称、年龄阶段、性别、种族。并勾选隐私政策,点击“Continue”提交。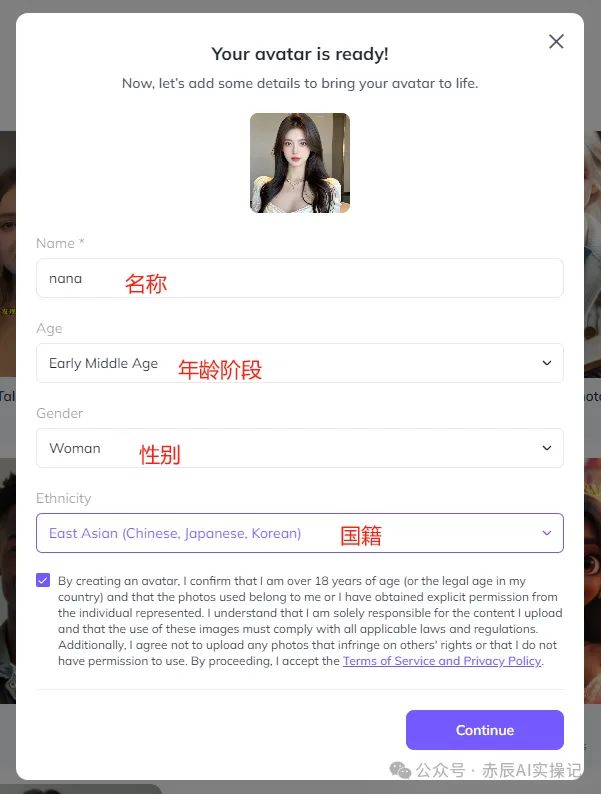
跳转到模型训练界面,满足10张以上,就可以点击“Train Model”进行人脸训练。提交后等待3分钟左右。
此次模型还有一个非常惊艳的功能,就是系统会根据人物的外形,去匹配声音。单次会提供3条音色,当然如果你觉得不满意,还可以在公告配音中心去挑选。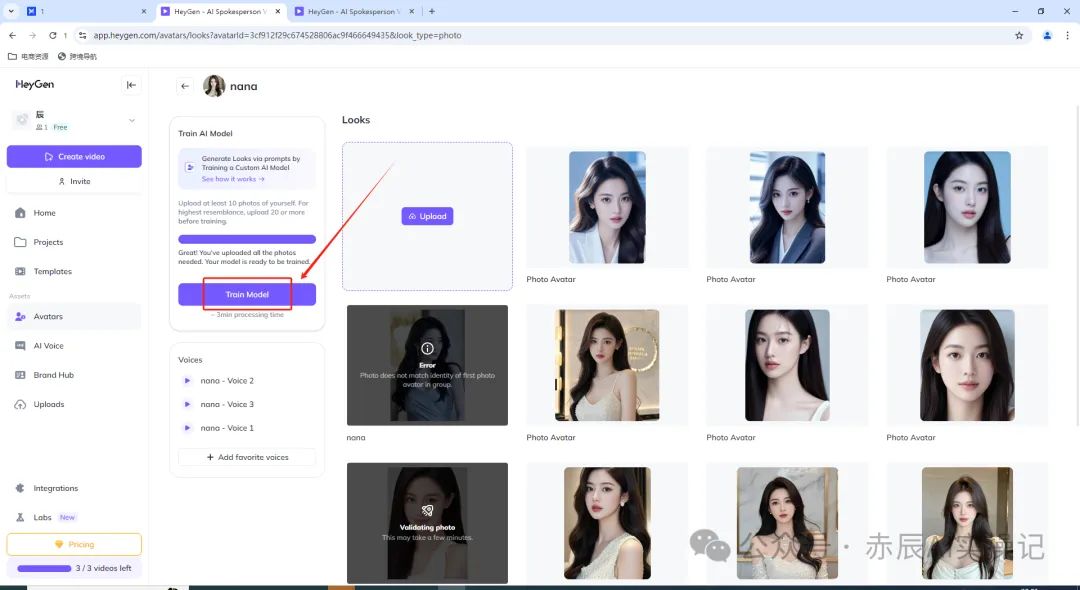
大概等待3分钟需要,模型就训练完成了,在输入框中填写人物外形描述,点击“Generate Looks”。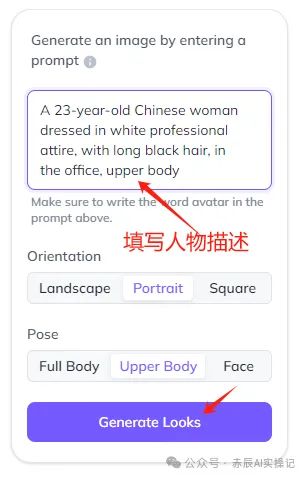
AI会单次生成4张图片,咱可以根据做下角的“Al Photo”标注来识别。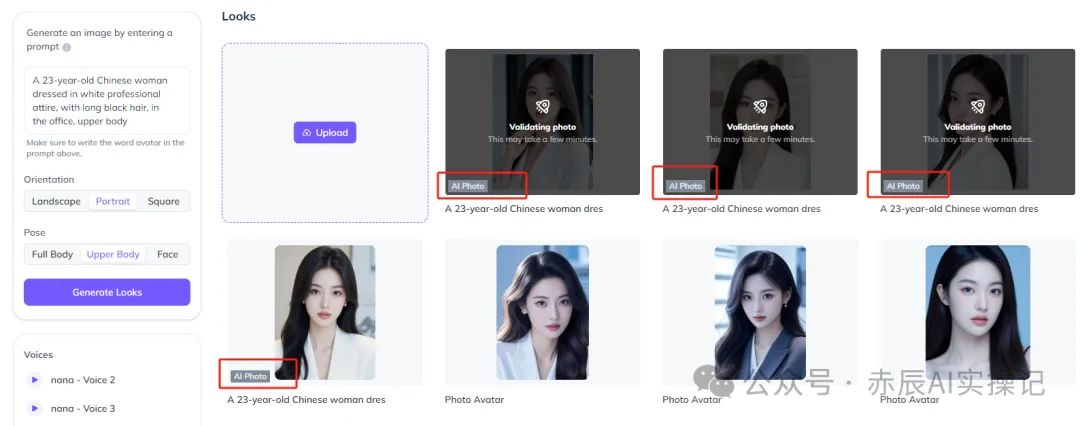
点击其中一张满意的图片,创建“ Create with Al Studio”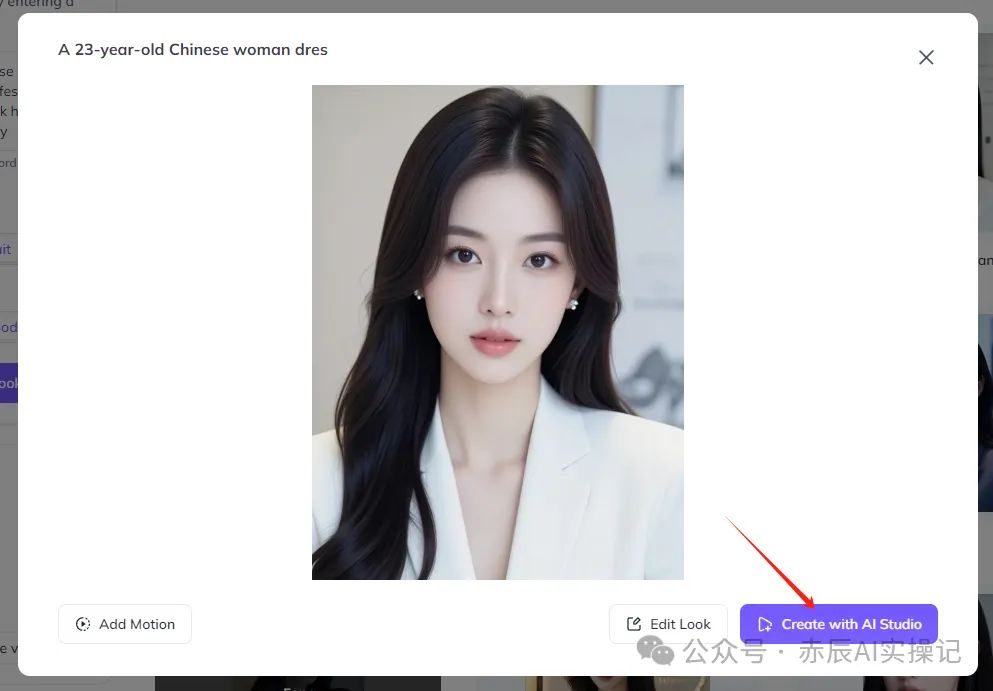
接着选择音色,在文本框将文案复制进来,点击右上角的提交即可。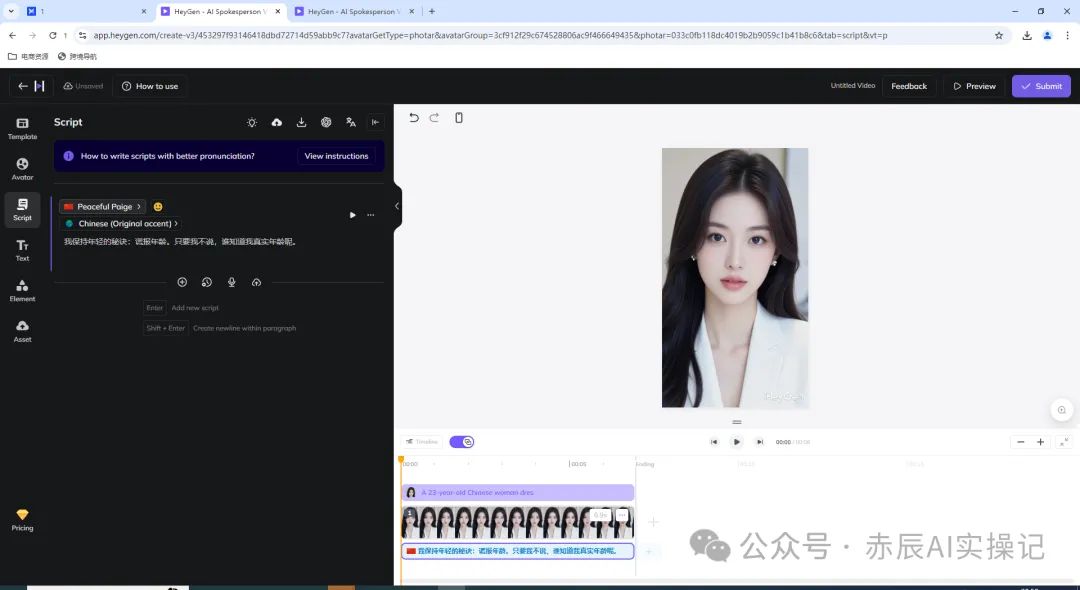
接着点击继续提交生成。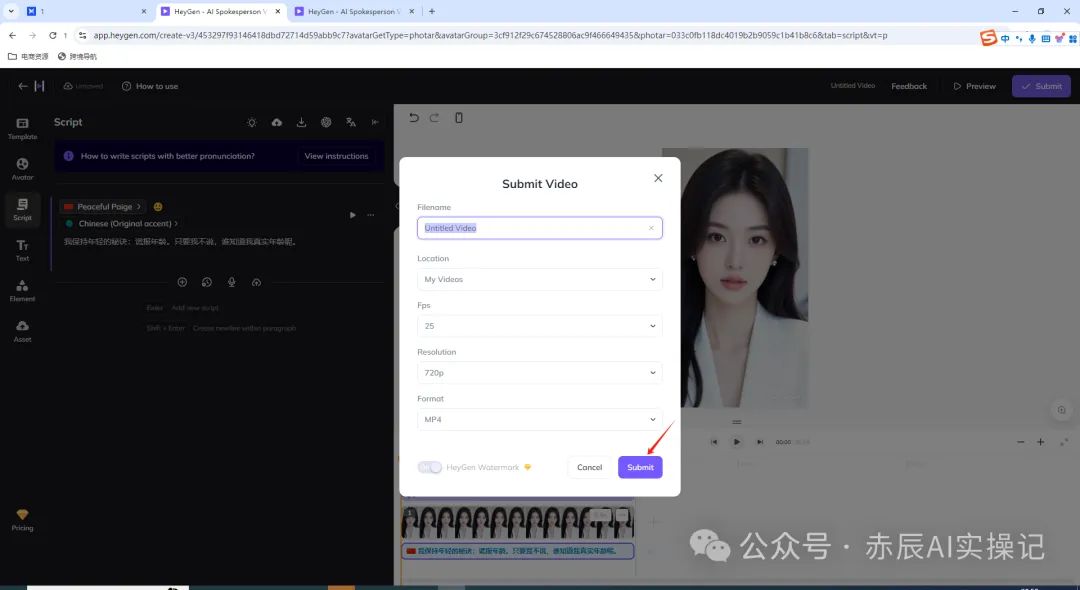
大概静等几分钟视频就生成完毕后,可以在“Projects”项目中查看生成好的视频。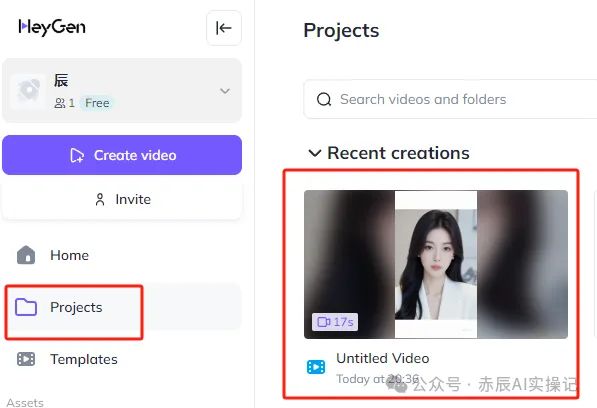
视频查看没有问题后,点击下载即可。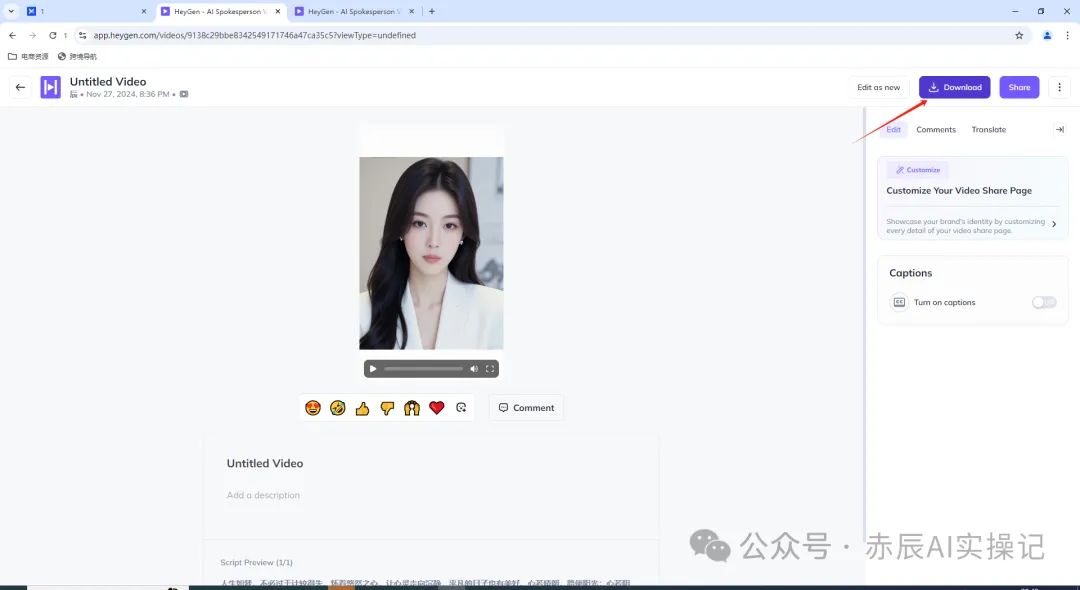
AI数字人已成为传统?丢1张图片直接做AI数字人!HeyGen重磅更新!无需录视频!
观看更多转载,AI数字人已成为传统?丢1张图片直接做AI数字人!HeyGen重磅更新!无需录视频!赤辰AI实操记已关注分享点赞在看已同步到看一看写下你的评论
2.Generate
这个功能生成原理,就是直接提供提示词在线生成人物脸,然后基于生成的图片去训练模型,进而通过描述词来控制角色一致性,生成各种服装或者动作姿势的图片转口播视频。
首先点击“Generate”
接着需要描述你的数字人外观,例如填写名称、年龄段、性别、种族、外形描述,其他的默认即可,最后点击“Generate Preview”等待生成。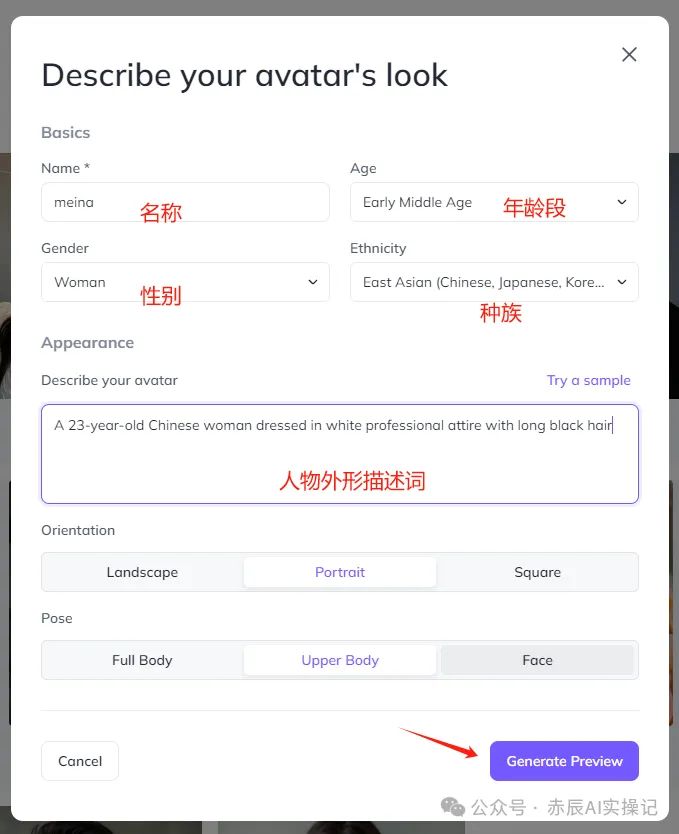
大概静等15-30秒,系统即可生成,单次生成4张,咱只需选择一张满意的即可,点击“Save”。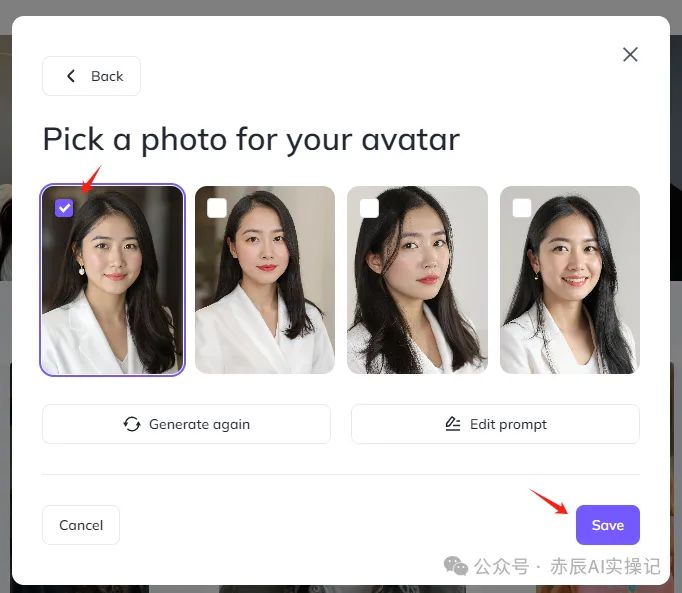
接着需要基于单张图片训练模型,点击“Train Model”即可进行训练。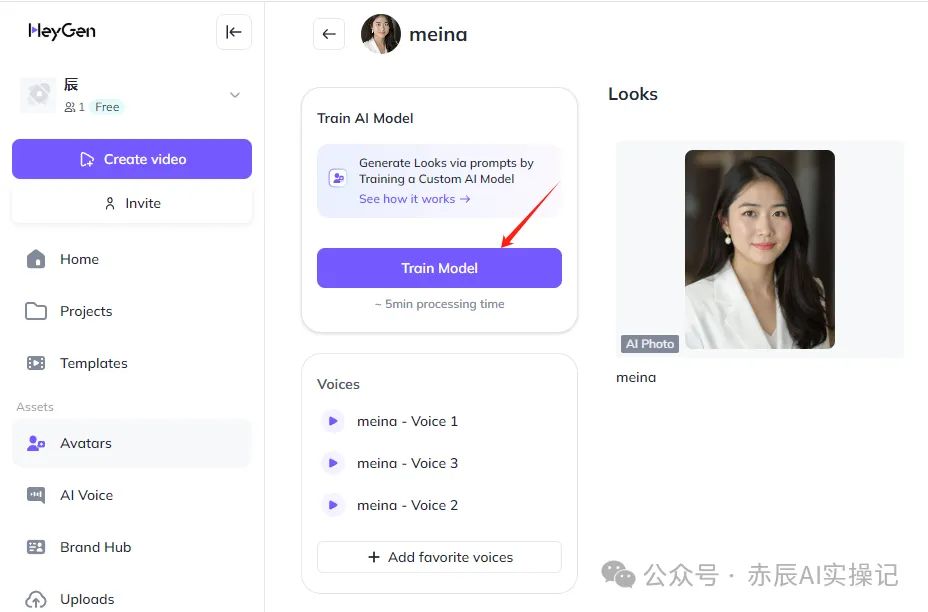
目前新用户每日有一次限免生成次数,由于我的次数用完了,所以这一部分的模型训练这步就介绍到这,感兴趣伙伴们,抓紧试玩一下!
写在最后 | 赤辰AI预判
AI数字人的发展一定会结合最新“AI视频生成技术”+“大模型语义理解能力”;
往后终极形态,仅需1张图+1段文字,AI就能解读字面意思,直接生成能匹配语义的表情+身体动作的视频,且衣服跟背景都可以自定义!
无痛出镜创作时代加速到来,国内即梦和可灵预估很快也会跟进!期待吧!

















 9345
9345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









