






Datawhale亲测
AI应用:讯飞智作
只用一张照片,就可以定制属于自己的数字人。
这是大模型给数字人领域带来的最新震撼。
就在两周前的 AI 开发者 Talk 合肥站活动上,我们 Datawhale 的一名小伙伴玉鑫化身成数字人亮相大屏幕,为参加活动的开发者们献上了一段欢迎致辞。
玉鑫变的更年轻了👐!
这个短短十几秒的视频在现场引起了热烈的讨论:“数字人玉鑫”声音的自然度简直完全听不出和真人的差别,同时口唇和肢体动作同步也特别自然,有着玉鑫独特的亲和力。
这样的超拟人数字人技术,由「讯飞智作」最新发布。
我们在小程序上使用了讯飞智作的“超拟人数字人”功能,只用了一张照片(下图所示)和一段语音花了几秒钟就生成了这段视频。

现在这个“超拟人数字人”功能已经全面开启,上手门槛特别低,让我们一睹为快。
一张照片实现超拟人数字人
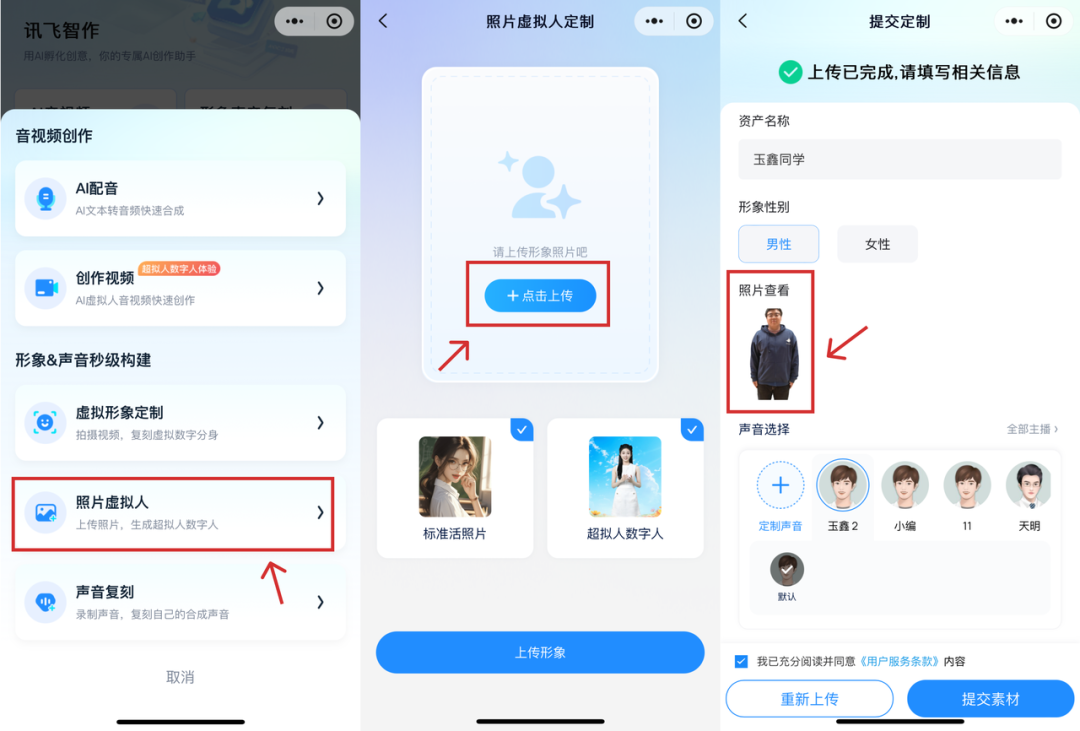
想要变身超拟人数字人,只需上传一张你的照片。
这里,我们还拿上面 Datawhale 小伙伴玉鑫的照片来演示(给玉鑫加鸡腿🍗了)
首先打开「讯飞智作」小程序,点击最下面的➕,然后把刚才的图片上传即可。
PS:大家在上传的时候记得一定要选择正面平视的全身高清照,这样出效果才会更好。
接下来是对数字人声音的选择,可以选择音库里面的声音,也可以复刻自己的声音。

讯飞智作的音库预制了海量的声音,支持各个年龄段、多种语言风格、多种行业领域、甚至多门国家语言。
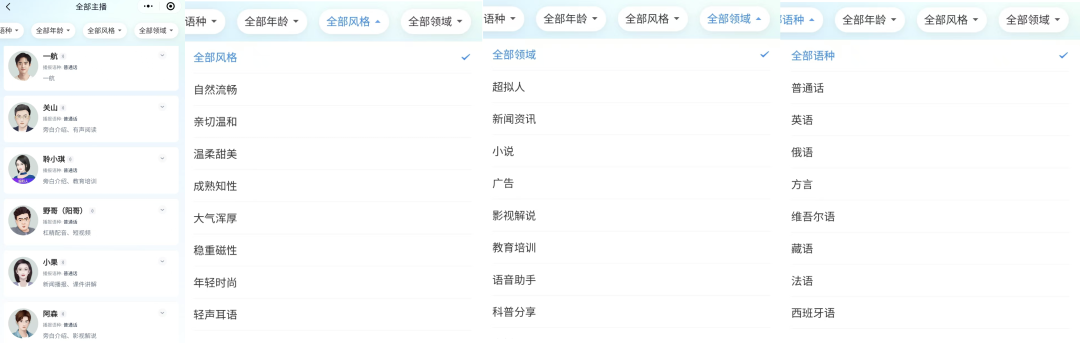
我们可以直接使用音库里的丰富声音,也可以选择一键「声音复刻」自己的声音。
这个步骤也很简单(如下图所示),只需要朗读一段文字就行,此时我们保存这段声音为“玉鑫”。
至于声音复刻的效果如何,待会儿和视频一起检验。

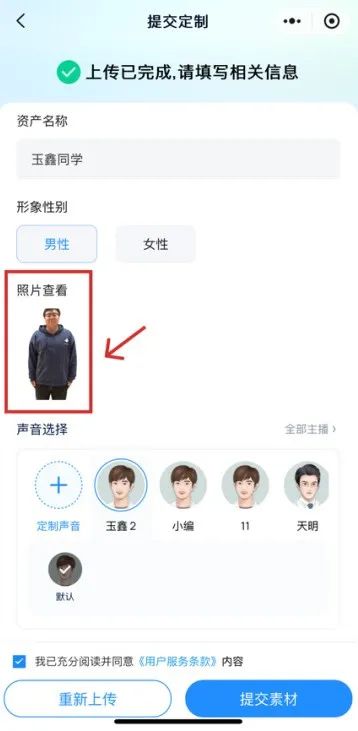
接下来我们返回刚才的页面,在声音部分选择刚才复刻好的“玉鑫”,然后点击提交就行。
也就是几秒钟的时间,玉鑫同学的超拟人数字人就构建完成了。
说是「秒级构建」还真不是吹的啊!
然而,光是快可不保险,毕竟业内可是有个知名的梗:“ 你别管我算的对不对,就问你快不快吧!”
接下来就创作一个视频检验一下生成的数字人效果。
创作视频的方法也很简单,首先如下图(图中),生成效果选择超拟人数字人,形象 & 声音选择刚才创建好的“玉鑫同学”。
接下来输入一段想让数字人说话的文案,当然,文案也可以利用讯飞的 AI(星火文案助手)帮你生成。
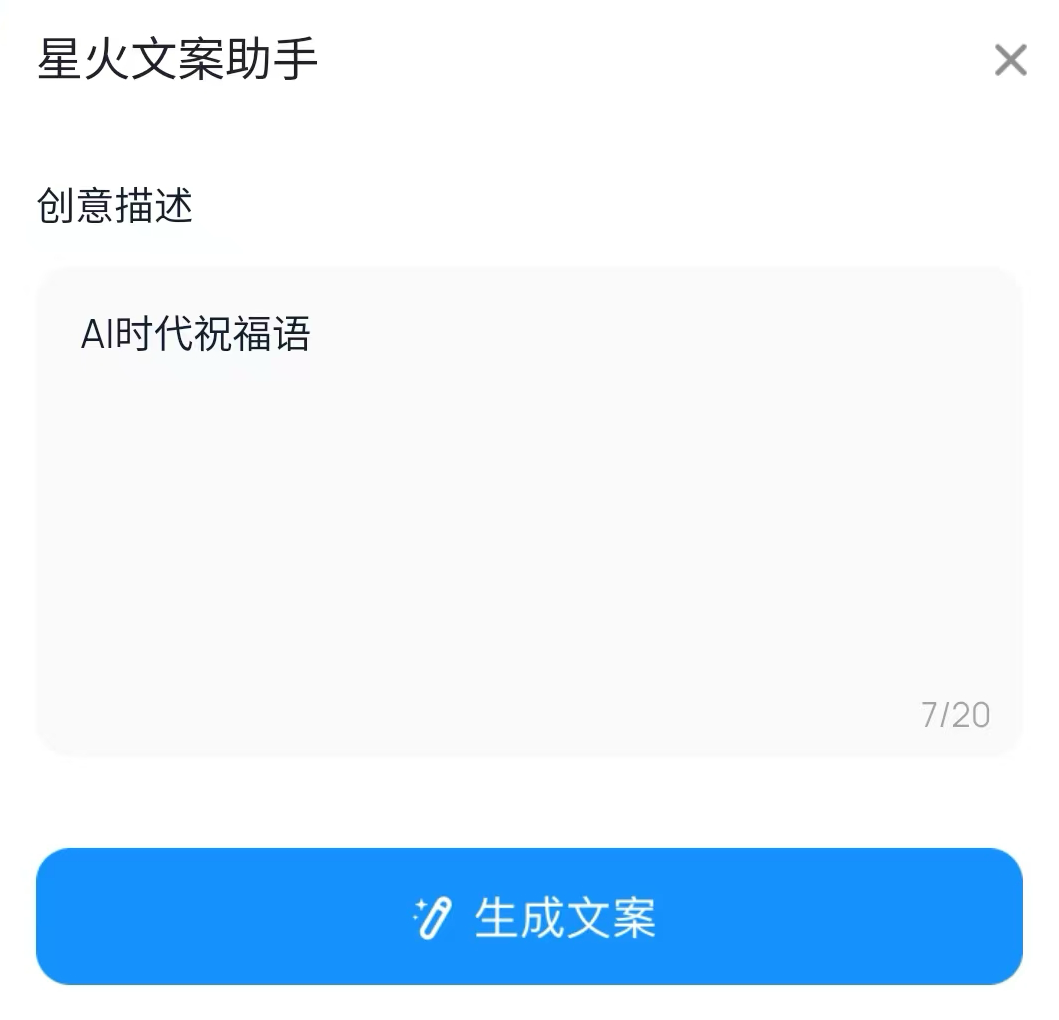
比如输入关键词“AI 时代祝福语”,星火文案助手直接秒出了一段文案。
AI 时代,愿智慧之光照亮你的每一天。愿你在数据的海洋中畅游,收获知识与创新的力量。祝你在这个智能互联的世界里,事业腾飞,生活美满!
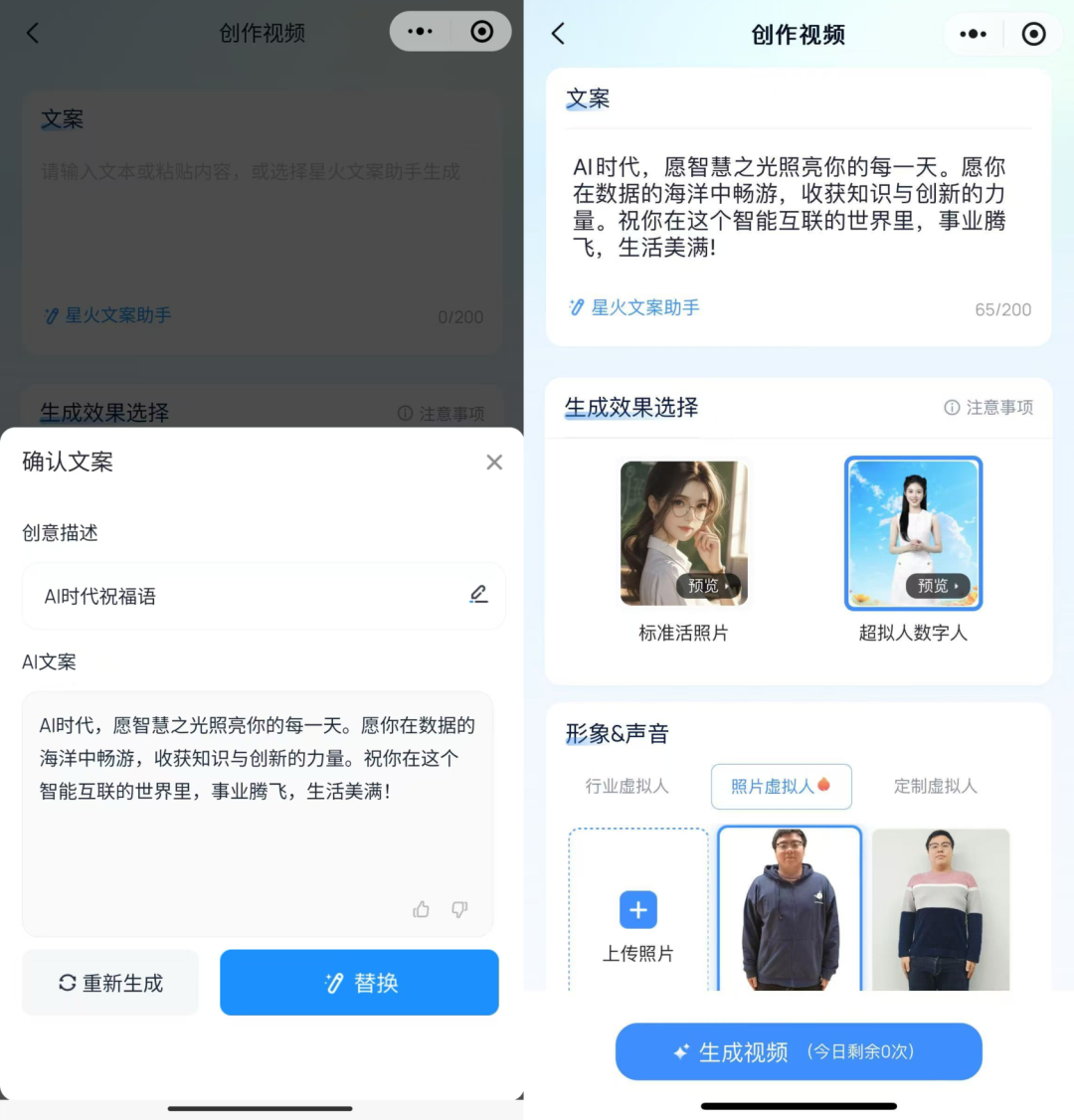
最后点击“生成视频”,然后只需等待几秒。
欣赏成片:
在效率如此大幅提升的前提下,超拟人数字人的细节质量依然保持着高水准。
今年的除夕,我们就可以用超拟人数字人给朋友家人道一声新年快乐。
如今,超拟人数字人的应用场景非常可观,它可以让任何人任何角色几秒钟化身为数字人视频分身。
不论是自媒体带货直播、赋能文旅,亦或者在新范式的驱动之下,步入“寻常百姓家”正在成为可能。
超拟人数字人,步入大模型时代应用新范式
大模型带来的规模化应用的时代变革,已经成为科技圈新的热议焦点。
「讯飞智作」的超拟人数字人生成,核心受到关注的,其实还是多模态交互技术:
比如在肢体动作驱动方面,讯飞智作针对此次超拟人数字人进行了大胆的技术创新——通过多模扩散生成大模型的应用,数字人的四肢动作能够与语音内容自然匹配,摆脱了传统预设动作的局限,数字人动作更加自然、流畅和逼真,也更有生命力。
在表情动作的语义贯穿方面,讯飞智作利用大模型的多模态交互技术将语义贯穿“口唇-表情-动作”生成,实现了跨模态的语义一致性。

讯飞智作的超拟人数字人将构建提升到了秒级,降低了数字人定制的门槛,让大家看到了其在 AI 数字人领域的领先性。
解放生产力、释放想象力,让创意生产,变得简单、高效、人人可用。
体验通道:讯飞智作
 一起“点赞”三连↓
一起“点赞”三连↓

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









