







目录
问题场景
一群鸟在随机搜索食物,在这个区域里只有一块食物。所有的鸟都不知道食物在那里。但是他们知道当前的位置离食物还有多远。那么找到食物的最优策略是什么呢?最简单有效的就是搜寻离食物最近的鸟的周围区域。
基于上述模型的启发,通过模拟鸟群的觅食行为, Eberhart 博士和 kennedy 博士最早提出了粒子群优化(PSO)算法,又可称为粒子群算法、微粒群算法或 微粒群优化算法。该算法一种基于群体协作的随机搜索算法,属于群集智能 (Swarm intelligence, SI)方法。
1 算法原理
在 PSO 算法中,优化问题的解代表搜索空间中的鸟(称为“粒子)”,所有 的粒子都有一个由被优化的函数决定的适应值(fitness value),以及每个粒子 有一个速度来决定它们飞翔的方向和距离。在具体搜索过程中,每一粒子通过跟 踪两个“极值”来更新自己。其中,第一个粒子是自身所找到的最优解,称为个 体极值 pbest;另一个是整个种群所找到的最优解,称为全局极值 gbest。
特别地,针对上节中的优化问题,PSO 算法的具体操作如下。
1.1 初始化
在问题的决策空间中随机生成 NP 个粒子,具体方式与 DE 算法相同
差分进化算法链接地址:http://t.csdn.cn/WDdQo
1.2 更新速度
对每一个粒子
x
i
,找出其相应的 pbest 和 gbest,根据下式来更 新自己的速度
v
i。

其中,w 为惯性权重,
c
1
和
c
2
分别为认知加速常数或学习因子(cognitive acceleration coefficient)和社会加速常数或学习因子(social acceleration coefficient),
r
1
和
r
2
为区间[0,1]内的两个随机值。
1.3 更新位置
根据上述更新后的速度更新自身的位置。具体过程如下:
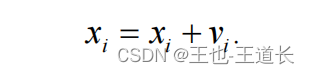
注 2: 粒子的在每一维上的速度都应被限制在一个预先给定的范围内。当某一维的速 度超过Vmax 时,则将该维的速度限定为 Vmax。
2 算法流程
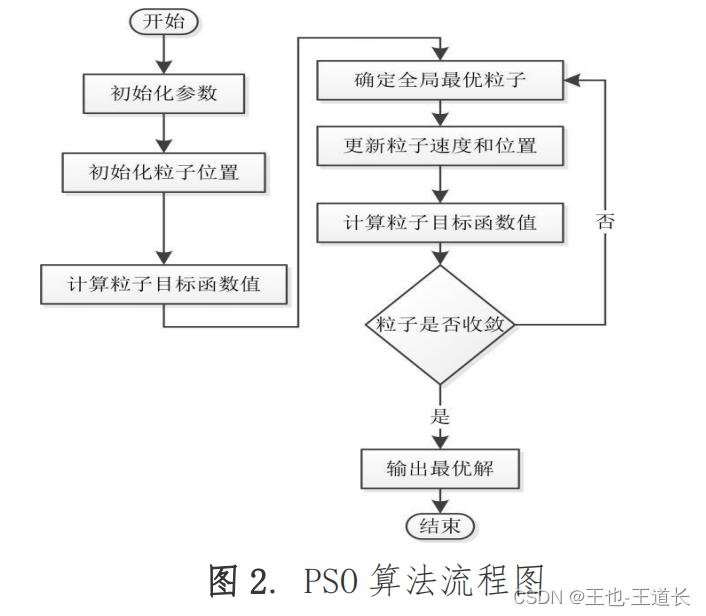
根据上述操作,PSO 算法的具体实现流程如下。
步 1:确定算法中的相关参数(包括粒子个数 NP、惯性权重 w、学习因子
c
1
和
c
2
),确定适应度函数。
步 2:随机产生初始粒子群。
步 3:对初始粒子进行评价,即计算初始每个粒子的适应度值。
步 4:判断是否达到终止条件。若是,则终止搜索,将得到历史最佳粒子作 为最优解输出;若否,继续。
步 5:更新粒子速度和位置。
步 6:迭代次数 g=g+1,转步(4)
3 参数说明
3.1 粒子数 NP
一般取 20–40。实际上,对于大部分的问题,一般取 10 个粒子 就可以得到好的结果。然而,对一些比较难(复杂)的问题或一些特定类别的问 题而言, 粒子数可以取到 100 或 200。
3.2 粒子的长度(维数)
由优化问题决定, 即问题解的维数。
3.3 粒子的范围
由优化问题决定,每一维可设定不同的范围。
3.4 最大速度 Vmax
决定粒子在搜索过程中的最大移动距离,通常设为粒子的范 围宽度。
3.5 学习因子 c1 和 c2
通常等于 2. 一些文献中也有其他的取值,但一般取 c1 等于 c2 且在 0 到 4 之间取值。
4 算法的不足和改进
与 DE 算法相似,PSO 算法随着迭代的进行,粒子之间的多样性也会降低,导 致过早收敛到局部极小点,或者发生停滞现象。 目前,为进一步提高 PSO 算法的性能,一些动态的参数控制方法及拓扑结构 被研究和引入。
(注:本资料来自导师田梦男上课讲义,转载请注明出处)
[1] R. Eberhart, J. Kennedy, Particle swarm optimization, in: Proceedings of the IEEE international conference on neural networks, Vol. 4, IEEE, 1995, pp. 1942–1948.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











