




上篇介绍了 RNN 快速实践;使用 LSTM 的话,可以解决梯度离散及短期记忆问题;代码部署方面,增加了 c 值 (即 RNN 中的 h 变成了 LSTM 中的 (h,c)), 可对照 RNN 快速实践 来快速掌握。
- LSTM Layer
torch.nn.LSTM(input_size,hidden_size,num_layers,batch_first)input_size: 输入的编码维度hidden_size: 隐含层的维数num_layers: 隐含层的层数batch_first:·True指定输入的参数顺序为:- x:[batch, seq_len, input_size] # 或者用符号 c0
- h0:[batch, num_layers, hidden_size]
- LSTM 的输入:
- x:[seq_len, batch, input_size] # 或者用符号 c0
seq_len: 输入的序列长度batch: batch size 批大小
- (h0, c0):[num_layers, batch, hidden_size]
- x:[seq_len, batch, input_size] # 或者用符号 c0
- LSTM 的输出:
- y: [seq_len, batch, hidden_size]
- (ht, ct):[num_layers, batch, hidden_size]
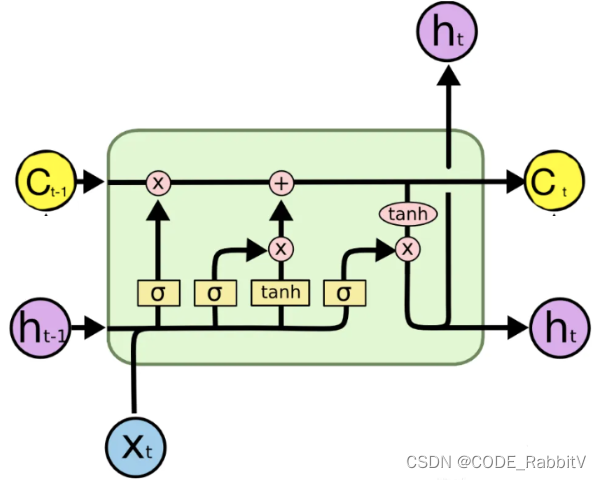 ..........
..........
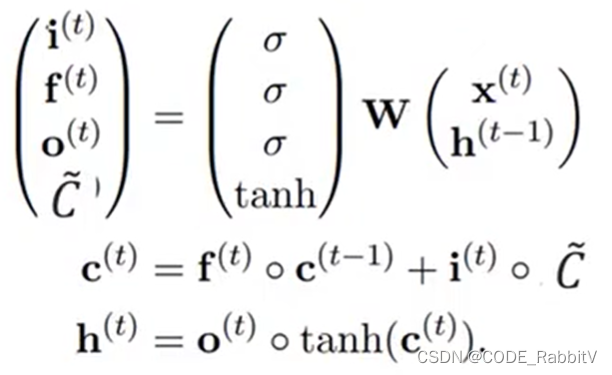
三个门 ( σ \sigma σ处:遗忘f、输入i、输出o) 都是基于 x t \mathbf{x}_t xt 和 h t − 1 \mathbf{h}_{t-1} ht−1 产生,但是分别对应要学习的权重参数 W W W 不同,或可参照下简化图直观理解 LSTM 模块内部的处理流程
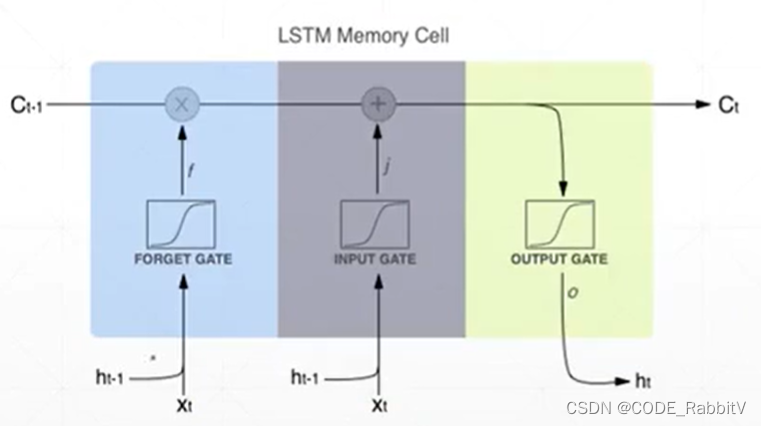
-
实战之预测
正弦曲线:以下会以此为例,演示RNN预测任务的部署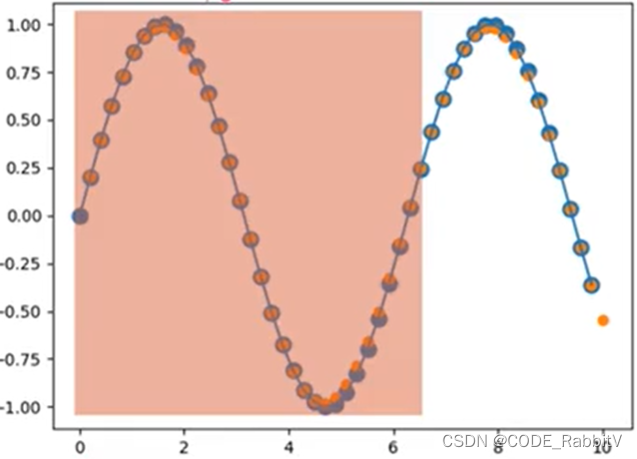
-
下述示例代码已注明
区别行########################### (共3处) -
步骤一:确定 RNN Layer 相关参数值并基于此创建
Net(RNN->LSTM)import numpy as np from matplotlib import pyplot as plt import torch import torch.nn as nn import torch.optim as optim seq_len = 50 batch = 1 num_time_steps = seq_len input_size = 1 output_size = input_size hidden_size =
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4383
4383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









