










概念引入
逻辑回归
线性回归
时间序列分析
神经网络
self-attention与softmax的推导
word2evc
该篇论文的背景
word2evc提出的方法无法使用全局的统计信息
矩阵分解方法在词对推理的任务上表现很差
介绍
LSA和word2vec,一个是利用了全局特征的矩阵分解方法,一个是利用局部上下文的方法。
GloVe模型就是将这两中特征合并到一起的,即使用了语料库的全局统计(overall statistics)特征,也使用了局部的上下文特征(即滑动窗口)。为了做到这一点GloVe模型引入了Co-occurrence Probabilities Matrix。
关键点
• 矩阵分解的词向量学习方法
• 基于上下文的词向量学习方法
• 预训练词向量
该篇论文的成果
• 提出了一种新的词向量训练模型——GloVe
• 在多个任务上取得最好的结果
• 公布了一系列预训练的词向量
摘要大意
当前词向量学习模型能够通过向量的算术计算捕捉词之间细微的语法和语义规律,但是这种规律背后的原理不清楚。经分析,我们发现了一些有助于这种词向量规律的特性,并基于词提出了一种新的对数双线性回归模型,这种模型能够利用全局矩阵分解和局部上下文的优点来学习词向量。我们的模型通过只在共现矩阵中的非0位置训练达到高效训练的目的。在词对推理任务上得到75%的准确率,并且在多个任务上得到最优结果。
模型原理
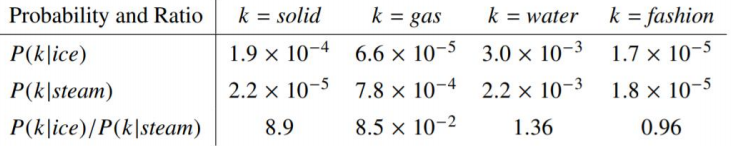

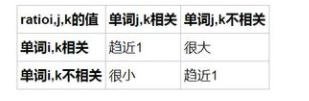
模型的公式推导
通过e的x次方函数是减法变除法,加法变乘法,使参数减少,比如下图中的三个参数变两个,更好地进行计算(将白色部分与黑色部分对照看)
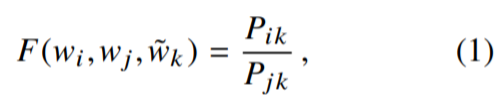
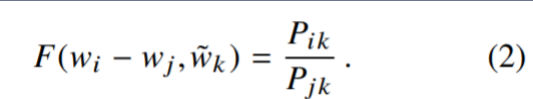
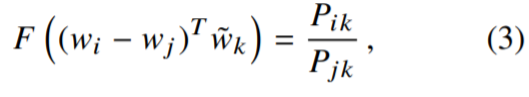
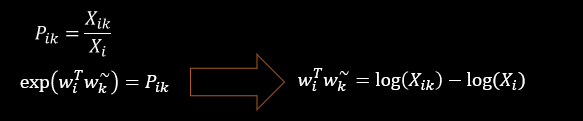
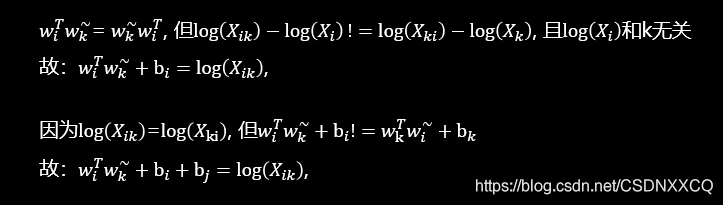
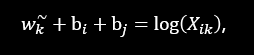
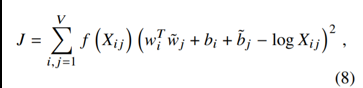
原理:词对出现次数越多,那么这两个词在loss函数中的影响越大。
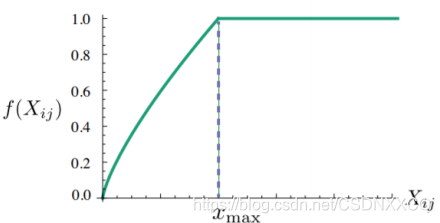
𝑓 (𝑋𝑖𝑗) 需要满足:
• 𝑋𝑖𝑗=0时, 𝑓 𝑋𝑖𝑗 =0:表示没有共现过的权重为0,不参加训练
• 非减函数,因为共现次数越多,权重越高
• 𝑓 (𝑋𝑖𝑗) 不能无限制的大,防止无意义词比如 is,are,the的影响
于是论文如此设计𝑓 (𝑋𝑖𝑗)函数,出现次数多的词其权重不超过1,降低其影响
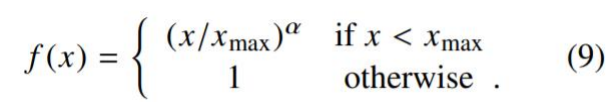
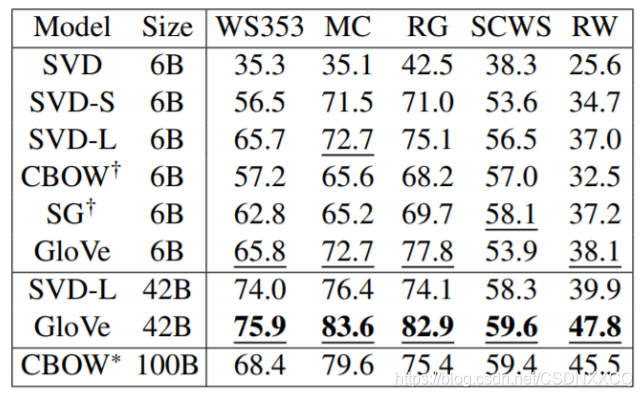
模型效果对比

在词对推理的数据集上取得了良好的效果(图中模型中的最好结果)
多个词相似度任务的实验结果
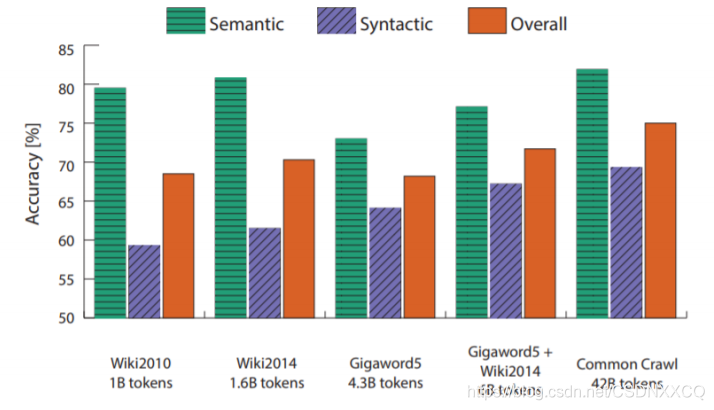
命名实体识别任务的实验结果
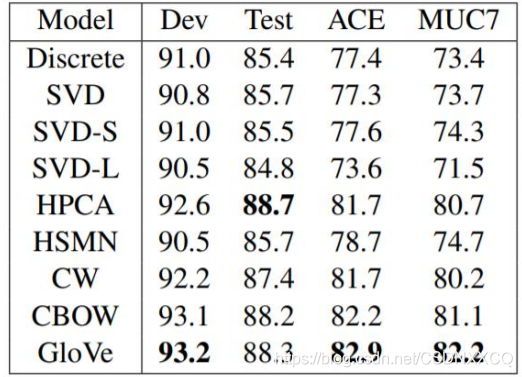
向量长度与窗口大小对结果的影响
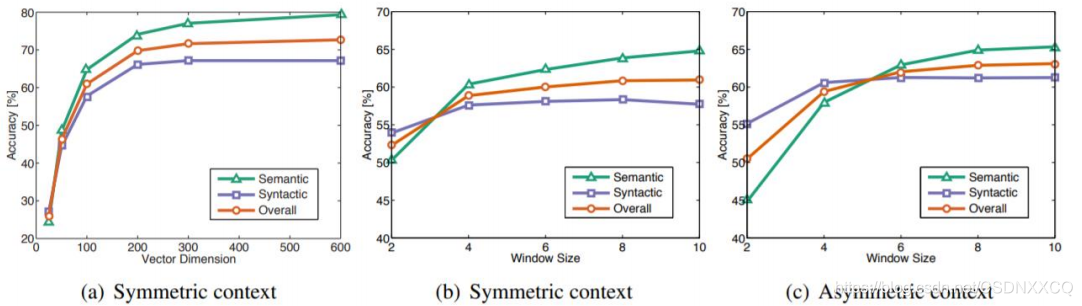
训练语料对结果的影响
与Word2vec对比

















 572
572











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











