






Tokenzation: Beyond Tokenizers of LLMs
1 什么是Tokenization
Tokenzation,指的是将数据转换为离散序列的过程。例如,我们在阅读英语时,我们是一个一个单词阅读的,也就是说,人类的Tokenization就是把句子按照空格和标点符号切分。在大语言模型中,Tokenizer将语言的字符串转化为token序列,token来自于一个固定词汇表。为了缩减词汇表大小,token与单词略有不同,可以看作“词根词缀”,根据BPE算法得到的。例如,Llama的词汇表大小是32000 token。

LLM的Tokenization
2 视觉(Vision)的Tokenization
NLP领域中,自然语言的Tokenization较为直观,并且已经有比较成熟的实现方法。随着大模型领域迈向多模态时代,一个热点的研究方向是构建视觉、音频等模态和文本模态统一的大模型,即使用一个多模态大模型(MLLM)进行理解与生成。
以Transformer为基础架构,我们需要将文本之外的其他模态进行Tokenization。用于理解任务的MLLM通常将visual feature投影至LLM的空间,将投影后的Visual Token和自然语言指令共同输入LLM中进行理解任务。经典的架构包括LLaVa[1],BLIP-2[2]等。模型通过Instruction Tuning的方式训练投影器的参数,或者同时对LLM进行参数高效微调。这里的投影,不论是线性投影还是Q-Former,并不完全算是Tokenizer,因为生成的vision token并不在一个固定的词汇表中。
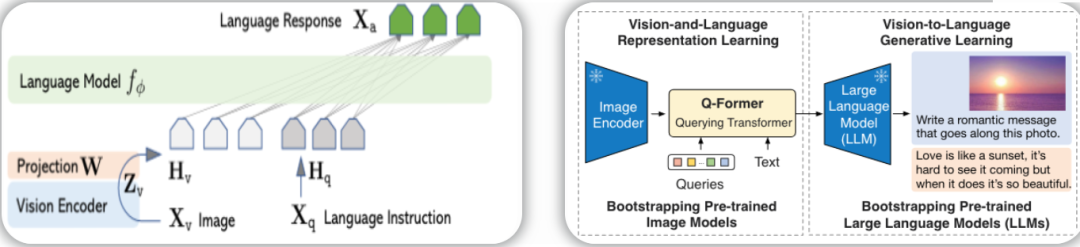
由于LLaVa和BLIP-2的backbone都是LLM,因此只能进行文本的生成。DALL·E[3]是一个经典的文生图模型,该模型的pipeline为:先训练一个离散VAE将图像中的patch转换为8192大小的词汇表中的某个token,再结合text token训练一个Transformer。
进入大模型时代,以SEED[4]为代表的多模态模型实现了文本和图像的自回归生成。以一个Frozen的ViT输出的visual feature为输入,该模型使用Causal Q-Former生成causal embeddings(causal指的是序列的前后关系,和Causal LLM的Causal是一个意思),再通过VQ-VAE进行离散化,维护一个vision vocabulary,与自然语言的vocabulary共同构成MLLM的词表,进行自回归生成。模型首先训练Q-former,得到text-grounded的causal feature;再通过重构目标训练VQ-VAE,得到Codebook。最后,在各种多模态任务上使用next token prediction的目标进行多模态自回归训练。与其类似的模型还有Emu3[5],进行了更多模态的自回归预训练。Emu3的Tokenizer是SBER-MoVQGAN,基于VQ-GAN的架构,与VQ-VAE有一些相似性。
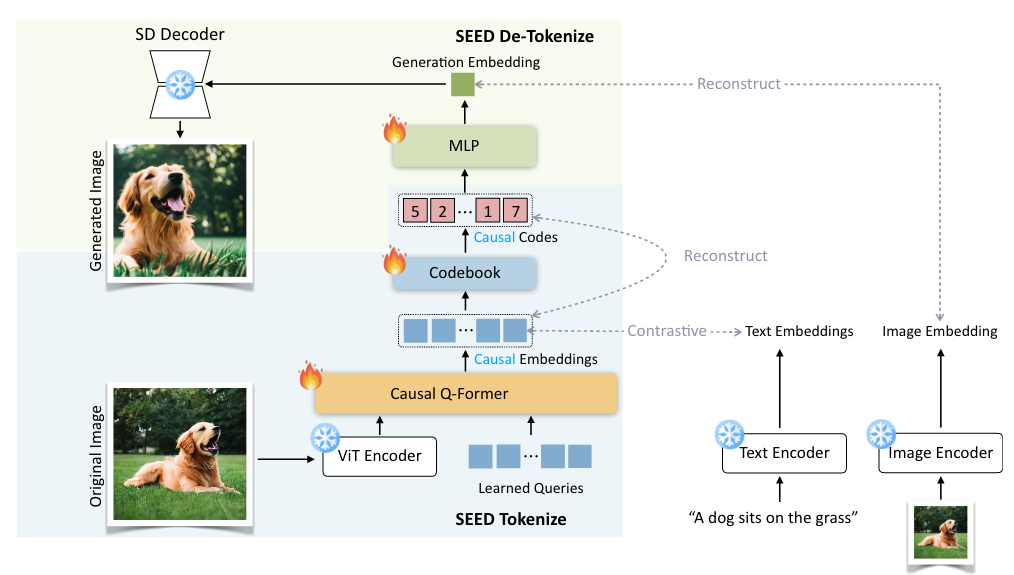
SEED Tokenizer
3 图(Graph)的Tokenization
由于分子图天然存在一个“词汇”,也就是固定的原子种类和化学键种类,有一些工作成功将分子图进行Tokenization以进行各种任务。Mole-BERT使用VQ-VAE的方式构建一个原子的词汇表,其中不同原子对应的vocabulary个数是不同的,用于解决atom vocabulary稀疏和不平衡的问题。模型训练方式与DALL·E类似,先训练VQ-VAE Tokenizer,再用masked modeling的目标训练GNN。
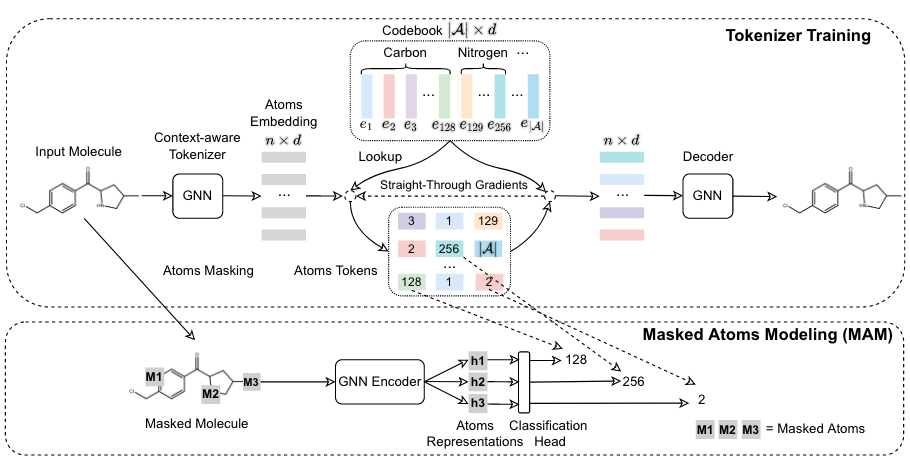
Mole-BERT
除了VQ-VAE的方式,GraphsGPT[6]将原子和化学键作为Token,将分子图序列化,通过自回归生成的方式训练了一个纯Graph Transformer进行各种任务,包括性质预测和可控生成。
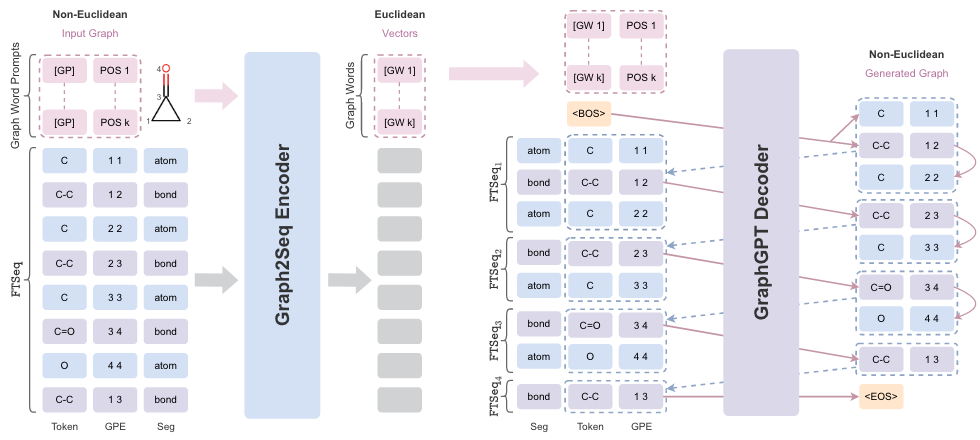
GraphsGPT
对于广义的图数据,Tokenization并不清晰。Graph Transformer和Graph-LLM领域都有一些将graph进行tokenization的工作。通常来讲,我们可以直接将节点特征作为token的embedding,特征可以来自于原始特征、GNN聚合、文本编码特征如SentenceBERT embedding。Graph Transformer大多使用节点原始特征,以NAGphormer[7]为代表的部分模型使用了按跳(hop)聚合的方式,即每一跳有一个token。近期也有部分工作[8]尝试引入VQ-VAE式的Tokenizer。
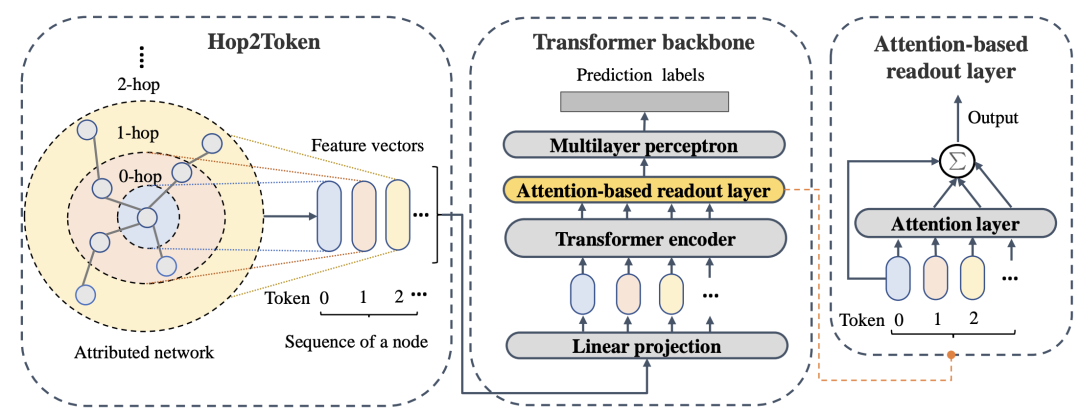
NAGphormer
为了让LLM能够在图数据上进行开放式的问答任务,利用LLM强大的推理能力,一些工作尝试将Graph Token作为指令的一部分,输入LLM进行推理任务。Graph Token即投影后的节点特征,是对齐到LLM空间后到图数据的表示。代表性工作有LLaGA[9],GraphGPT[10],GraphTranslator[11],TEA-GLM[12]等等。上述工作借鉴于LLaVA和BLIP式的pipeline。近期也有工作[13]使用VQ-VAE架构作为Tokenizer。该工作初步发现了VQ-VAE在graph上的优势,实现了图结构的跨数据集和跨域迁移性。
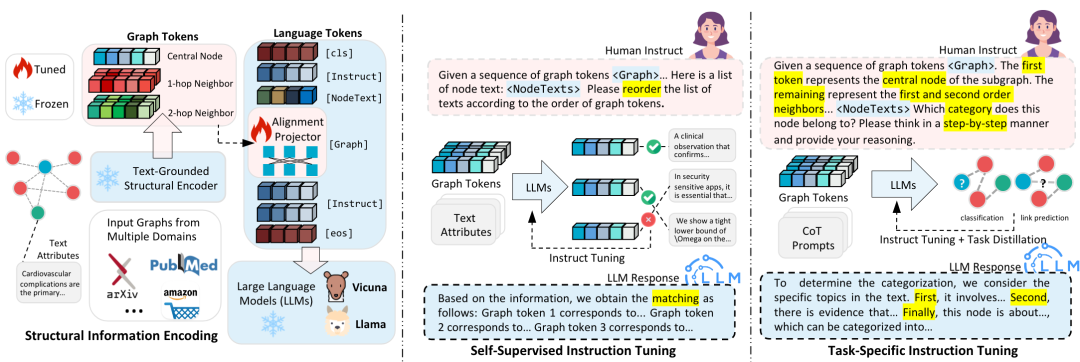
GraphGPT
尽管在图数据上进行自然语言式的开放问答任务比较重要,从而我们需要考虑Graph Tokenization的问题,但笔者认为以下问题仍然有待解答:
-
什么任务适合Tokenization+LLM的pipeline?传统的节点分类等任务是否真的需要?
-
什么数据适合Tokenization?为了实现Tokenization的可迁移性,需要怎样的训练数据集和领域、以及训练方法?
-
Graph Token究竟包含什么信息,或者说,需要包含什么信息?结构?特征?还是二者都有
-
LLM是否有能力decode出Graph Token包含的信息?为什么能decode出?
-
考虑到CV等模态和Graph的差异性,Graph LLM的Tokenization以及Training Pipeline该如何设计与改进?
那么,如何系统的去学习大模型LLM?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

篇幅有限,部分资料如下:
👉LLM大模型学习指南+路线汇总👈
💥大模型入门要点,扫盲必看!

💥既然要系统的学习大模型,那么学习路线是必不可少的,这份路线能帮助你快速梳理知识,形成自己的体系。
路线图很大就不一一展示了 (文末领取)

👉大模型入门实战训练👈
💥光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉国内企业大模型落地应用案例👈
💥两本《中国大模型落地应用案例集》 收录了近两年151个优秀的大模型落地应用案例,这些案例覆盖了金融、医疗、教育、交通、制造等众多领域,无论是对于大模型技术的研究者,还是对于希望了解大模型技术在实际业务中如何应用的业内人士,都具有很高的参考价值。 (文末领取)

👉GitHub海量高星开源项目👈
💥收集整理了海量的开源项目,地址、代码、文档等等全都下载共享给大家一起学习!

👉LLM大模型学习视频👈
💥观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 (文末领取)

👉640份大模型行业报告(持续更新)👈
💥包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

👉获取方式:
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓

















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









