






前言:本文主要研究了减少 Turbo 码译码时延以及存储资源的关键技术:滑动窗口算法。
Turbo 码使用的是块状编码的方式, 和
都是采用递归的方式进行计算的, k
是前向递推,
是后向递推。两者的递推方式相反,一个是从前向后递推,另一个是从后向前递推,因而,不能得到同一时刻的递推值。若使用传统的 Log-MAP 算法进行译码,需要将计算完的所有前向递推值
和分支转移度量值
存储起来,在后向递推运算完毕后,将其读取出来用于完成对数似然比的计算,具体的计算流程如图所示:
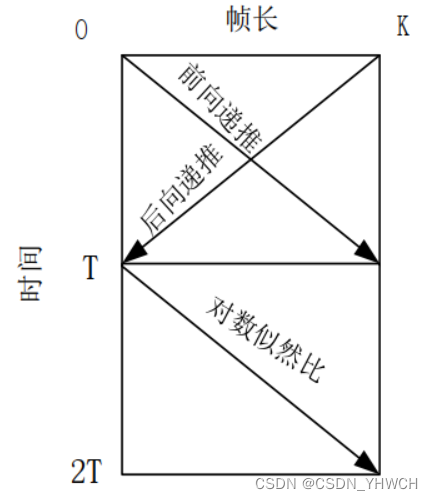
由图可以看出,计算对数似然比需要先将所有的前向状态值和后向状态值都计算完, 可以发现,两个状态值不是同时计算完成的。前向状态值未计算完成时,后向状态度量值也是无法完成计算的。 这样就会增加译码的时长,也会消耗更多的存储空间。不利于硬件的实现。
基于滑窗算法的MLMAP算法译码时序图如下:
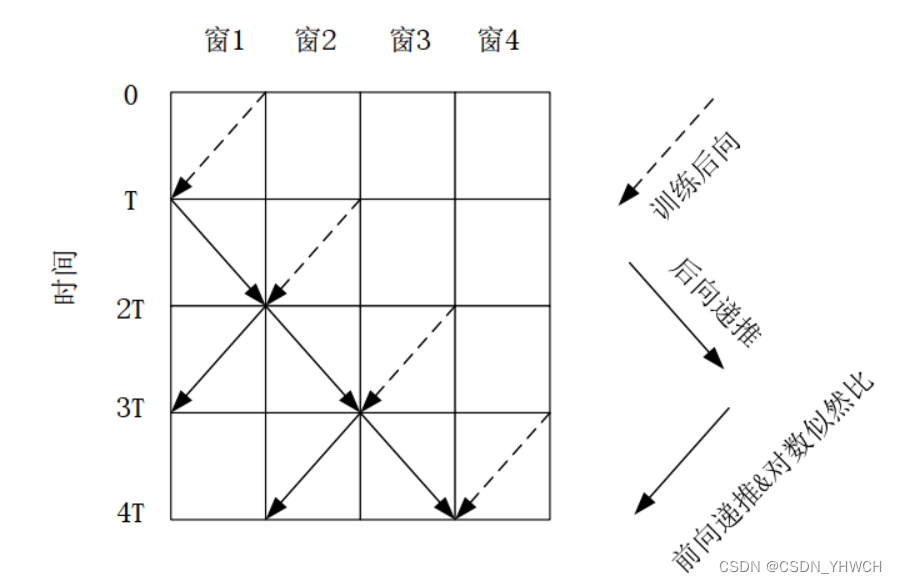
由滑动窗的译码时序图可知, 滑窗算法将一帧数据划分为一块块等长的数据帧,使每个窗口变成了独立的译码模块,当交织长度不是窗口长度的整数倍时,可以通过补零的方式将其变为等长。而滑窗算法与传统的 MAP 类算法最大的不同在于的计算,在滑窗译码算法中加入了训练后向状态度量值
,加入训练后向状态度量值的目的是为了保证每个窗口的最后一个比特值要已知, 才能进行后向递推。 在计算首个窗口时, 需先得出训练后向状态值
,得到可靠的初始信息。 但是第一个窗口运算的所有的结果值都会被丢弃。在第 2 个窗口运算时,因为上一个窗口的有效后向状态
还没有计算,所以需要将首个窗口的前向递归值以及最后一个训练后向状态的值存储起来,而
是为了给
提供可靠的初始值,所以不需要
存储的中间结果。在第三个窗口时,第一个窗口的
和前向递归
都已经计算完,可以将其读取出来计算对数似然比LLR ;所以,在滑窗算法的计算过程中,不需要存储
。因此,使用滑动 Log-MAP 译码算法,数据的接受方式变为边接收编译码,在很大程度上减少了中间参数的存储空间,也缩短了译码的时间。














 3515
3515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









