








导读
最近,大型语言模型(Large Language Models, LLMs)相关研究和落地取得了显著进展,为实现通用人工智能(AGI)迈出了重要步伐,并在各种语言应用中表现卓越。例如,2022 年底发布的 ChatGPT 能够基于在预训练阶段所见的模式和统计规律,来生成回答和上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、文案、翻译、代码、知识问答等任务。利用这些大型语言模型作为语言解码器,以及预训练的视觉大模型为视觉特征编码器,LMMs 同样在理解视觉和语言数据方面也展现出了显著效果。多模态大模型能够提取输入图像/视频的信息,结合大语言模型固有的世界知识,对输入的自然语言指令进行符合逻辑的推理和回答。
本项研究由中科大与字节跳动联合完成,并于2023年8月23日上传至arXiv,原文链接请点击文末阅读原文直接跳转。本研究中,作者提出了UniDoc,一个面向文字场景的统一的多模态大模型。UniDoc 专注于包含文本的图像的多模态理解任务。与现有的多模态大模型相比,UniDoc 集成了其它多模态大模型未具备的文本检测、识别、以及端到端OCR(spotting)能力。该研究指出,这些能力的学习相互促进彼此提升。论文在四个任务的多个测试基准数据集上,给出了定性和定量的结果,结果显示了 UniDoc 强大的识别和理解能力。在某些文字识别测试基准数据集上,UniDoc 几乎实现了与监督学习持平的性能。
方法
框架

如图所示,UniDoc 将文本检测、识别、spotting 以及多模态理解等任务,在多模态指令微调框架中实现了统一。具体来说,输入图像和指令(例如检测、识别、spotting或语义理解)后,UniDoc 会从图像中提取视觉和文本信息,并基于大型语言模型的知识库,结合指令内容完成回答。

数据
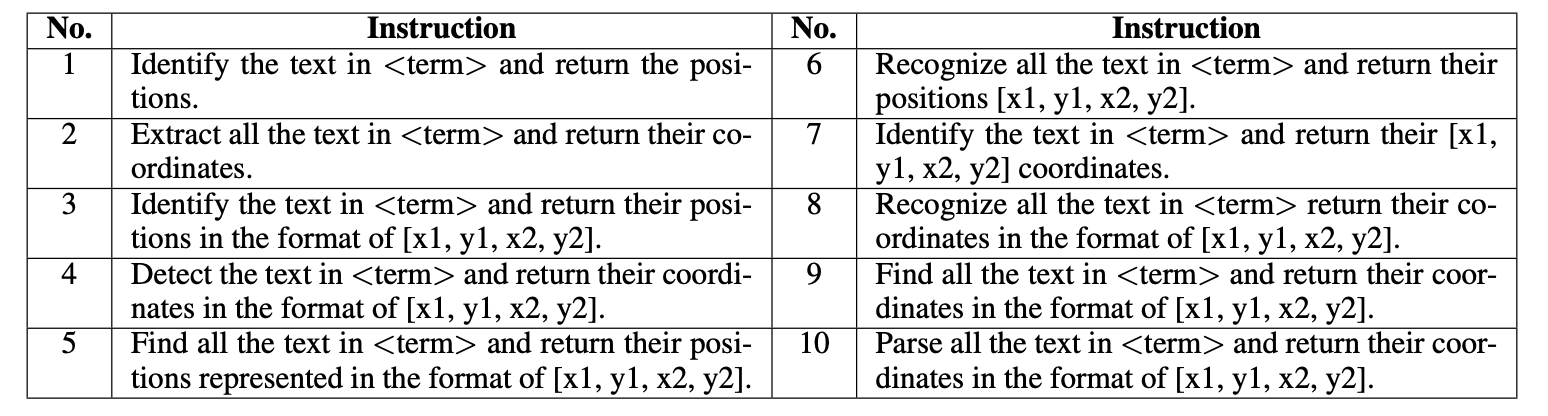
团队收集了大量的PPT图像,并从中提取所有文本实例及其边界框(bbox)。基于这些数据,构建了适用于多任务微调的数据集。考虑到 PPT 中的文字具有多种大小、字体、颜色和风格,并且其视觉元素丰富多样,因此这些 ppt 图像非常适合用作多模态文本图像任务的训练数据。以端到端 OCR 任务(spotting)为例,它的输入指令如下表所示。其中的 “term” 代表 “image”、“photo” 等随机图像名词,以丰富指令的多样性。
实验
文字检测,识别和端到端 OCR
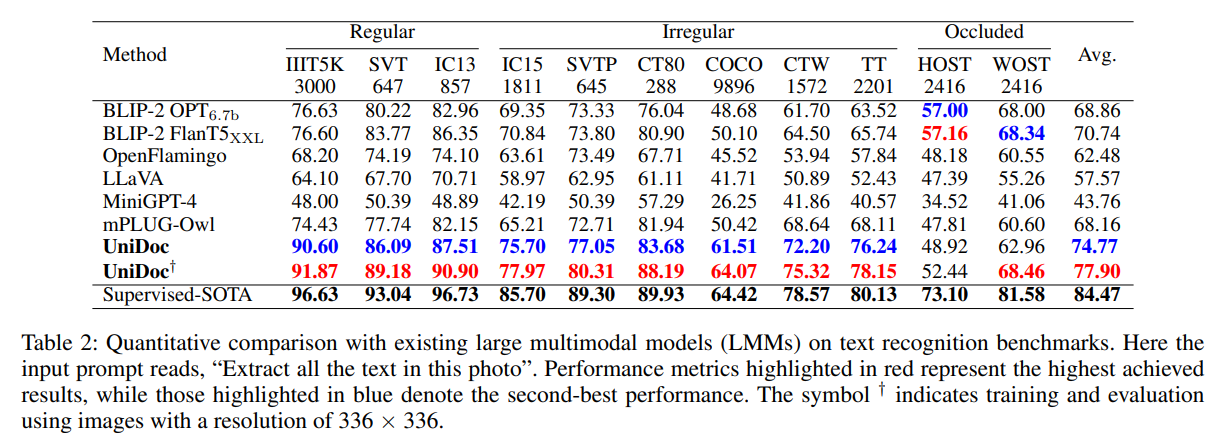
在多个文字识别基准数据集上,UniDoc 展现出了优秀的性能。表格中每一列为一个识别基准数据集。研究团队给出了两个输入图像尺度上的定量结果。值得注意的是,UniDoc 并没有利用这些数据集的训练集进行单独训练。此外,在某些数据集上(例如COCO),UniDoc 的识别准确率已经几乎与监督学习(单独利用该数据集的训练集进行训练)的准确率持平。

如上图所示,其中第一行多个样例来自 WordArt 数据集,而第二行四个样例则源自 TotalText 数据集。尽管这些文本图像展现了各种字体和不规则的文本分布(不曾出现在 ppt 数据中),但 UniDoc 仍能准确识别。

上图为来自 Host 数据集的样例。结果显示,在部分文字被遮挡或缺失的情况下,UniDoc 仍能准确识别。


上图显示了 UniDoc 在 TotalText 数据集上的文本检测效果。
多模态问答
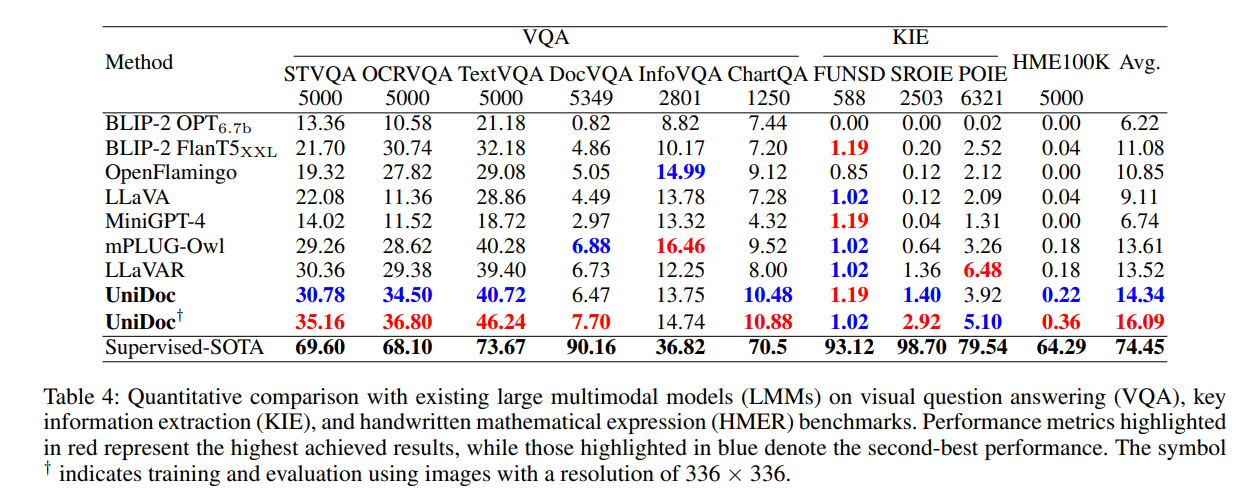
在多个多模态问答标准数据集上,UniDoc 都展现出卓越的性能。研究团队给出了两个输入图像尺度上的定量结果。


如上述示例所展示,UniDoc 不仅能够有效地从图像中提取视觉和文本信息,还能结合其丰富的预训练知识进行合理的回答。比如上图阿甘正传电影海报的例子,它能够从电影海报中的文字知道这是电影《阿甘正传》。进一步地,它能够基于预训练大语言模型的世界知识(电影《阿甘正传》的信息)回答出电影内容。

对于不含文本的图像,UniDoc亦可准确地进行问题回答。
消融实验

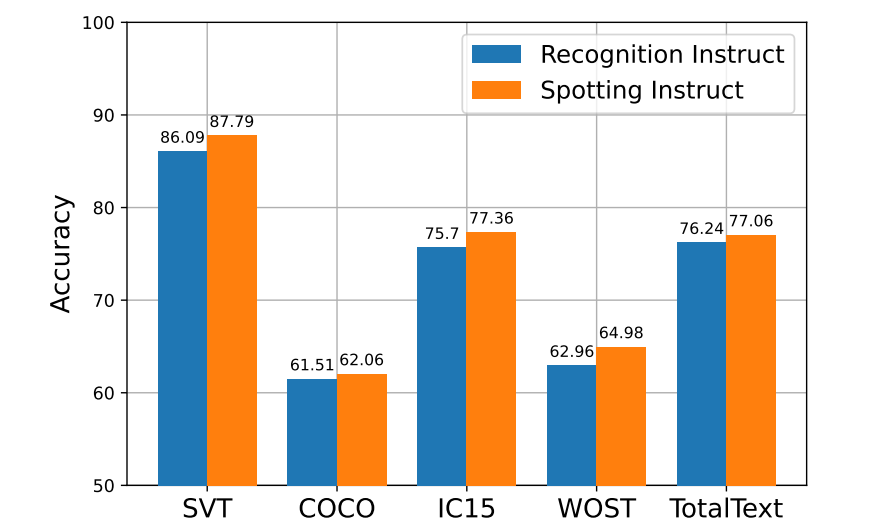
论文中提供了一个有趣的实验:输入同一张图像(左),使用spotting指令(右)可以避免使用识别指令(中)时出现的识别遗漏。论文分析,这是因为检测引入了先验信息(某个区域可能有文本)。如下表,作者在多个测试基准数据集上进行实验,spotting指令一致均好于识别指令。
总结
本文引入了一项新工作 UniDoc,这是一种通用的大型多模态模型,用于同时进行文本检测、识别、识别和理解。通过提出的统一多模态指令调整,UniDoc 有效地利用了基于文本的任务之间的有益交互,不仅解决了现有大型多模态模型的缺点,而且还增强了其原有的功能。此外,为了实现 UniDoc,研究团队贡献了一个遵循数据集的大规模多模式指令。实验表明,UniDoc 在多个基准测试中设置了最先进的分数。然而,目前 UniDoc 无法提取细粒度的视觉特征进行检测和识别,并且输入图像的分辨率仍然是一个限制,这将会一个不错的改进点。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











