








Title: Iterative Geometry Encoding Volume for Stereo Matching
Paper: https://arxiv.org/pdf/2303.06615.pdf
Code: https://github.com/gangweiX/IGEV
导读
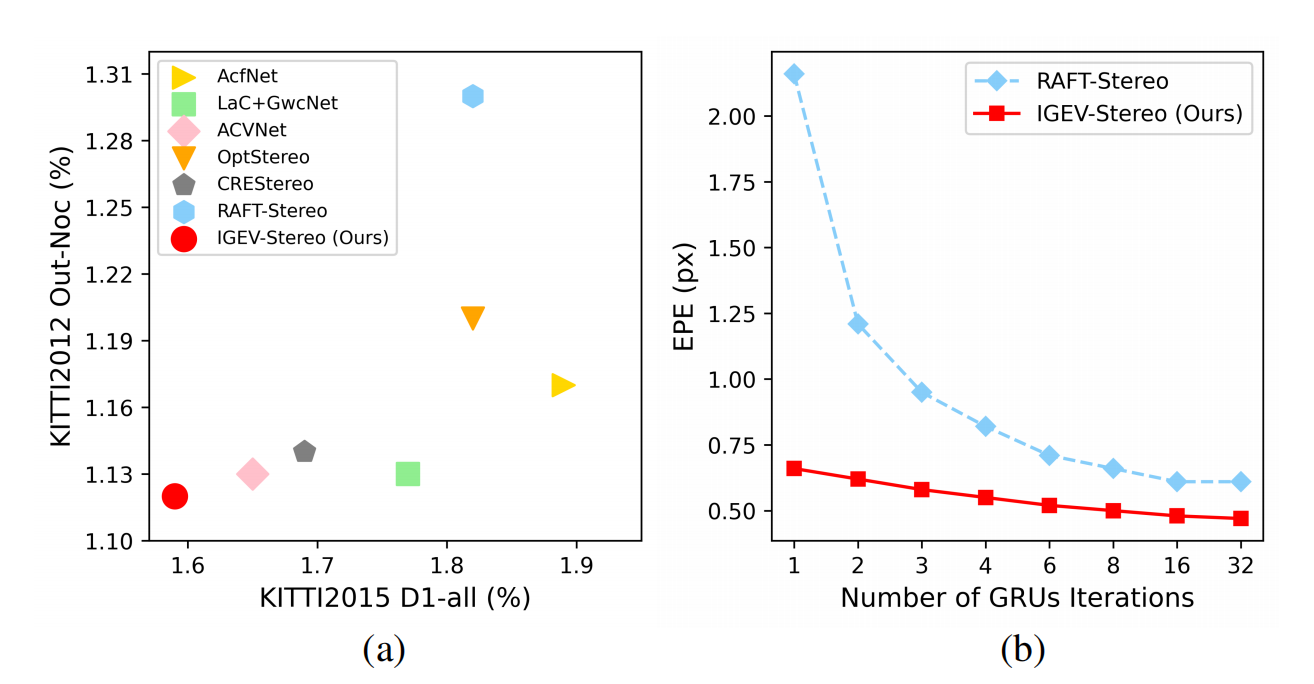
RAFT在立体匹配任务中显示出了巨大的潜力。然而,其使用的All-pairs Correlations缺乏非局部几何知识,难以处理病态区域(如遮挡、重复纹理、低纹理、高反等区域)的局部歧义。在本文中,作者提出了Iterative Geometry Encoding Volume(IGEV),一种新的立体匹配的深度网络体系结构。提出的IGEV-Stereo构建了一个Combined Geometry Encoding Volume,该Volume编码几何和上下文信息以及局部匹配细节,并迭代地对其进行索引以更新视差图。为了加快收敛速度,作者利用GEV回归出ConvGRUs迭代的准确初值。IGEV-Stereo在KITTI 2015和2012(Reflective)中在所有发布的方法中排名第一(如上图所示),是前10个方法中最快的。此外,IGEV-Stereo具有较强的跨数据集泛化性和较高的推理效率。作者还将IGEV扩展到Multi-View Stereo(MVS),即IGEV-MVS,它在DTU基准测试上实现了具有竞争力的精度。
贡献
现有的先进的双目立体匹配方法,主要分为基于代价滤波的方法以及基于迭代优化的方法(以RAFT为代表)。前者可以在cost volume中编码足够的非局部几何和上下文信息,这对于具有挑战性的区域中的视差预测至关重要。后者可以避免进行3D代价聚合所需的高计算和内存成本,但是仅基于All-pairs Correlations的方法在病态区域的能力较弱。

为了结合这两种方法的互补优势,论文提出了一种新的立体匹配范式——迭代几何编码体 (Iterative Geometry Encoding Volume, IGEV-Stereo)(如上图所示),其结合了更全面和精炼的几何和上下文信息,论文的主要贡献如下:
-
为了解决病态区域引起的模糊性问题。论文使用一个极轻量级的3D正则化网络对cost volume进行聚合和正则化,得到一个几何编码体(GEV)(结果如上图c所示),与RAFT-Stereo的All-pairs Correlations(结果如上图b所示)相比,GEV在聚合后编码了更多的场景几何和上下文信息。
-
为了解决边界和微小细节处出现过度平滑的情况。论文将GEV和RAFT中的All-pairs Correlations相结合,形成了组合几何编码体 (Combined Geometry Encoding Volume, CGEV),并输入到 ConvGRU-based update operator 中进行迭代视差图优化(结果如上图d所示)。
方法
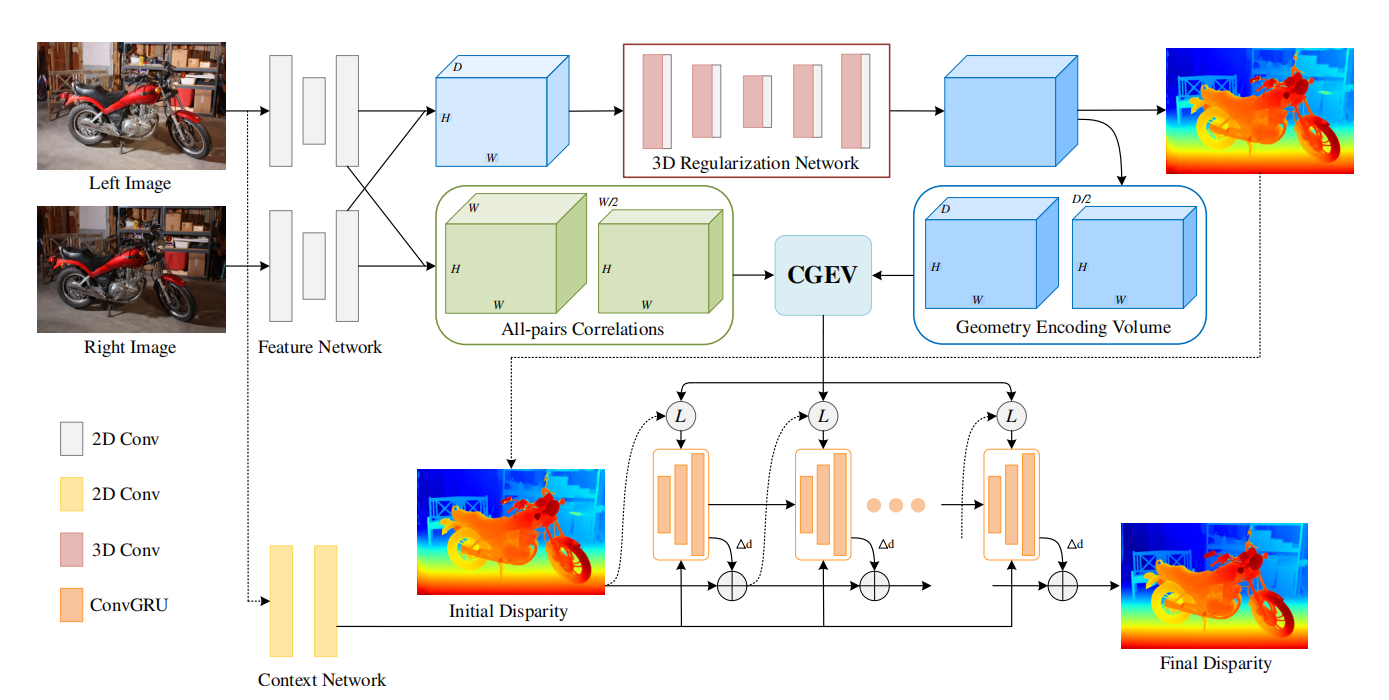
IGEV-Stereo它由一个多尺度feature extractor,一个Combined Geometry Encoding Volume,一个基于ConvGRU的Update Operator,以及一个Spatial Upsampling模块组成。
Feature Extractor
特征提取器包括两部分:
- 特征网络,提取多尺度特征用于cost volume构建和指导代价聚合
- 上下文网络,提取多尺度上下文特征用于ConvGRUs隐藏状态初始化和更新
Feature Network
论文使用在ImageNet上预训练的MobileNet V2将输入图降采样到1/32,然后通过上采样得到多尺度特征:
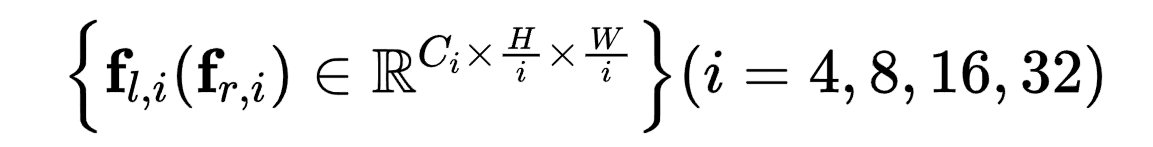
其中 f l , 4 f_{l,4} fl,4 和 f r , 4 f_{r,4} fr,4 用于构建cost volume
Context Network
同RAFT-Stereo一样,上下文网络由一系列残差块和下采样层组成,在输入128个通道图像分辨率的1/4、1/8和1/1/16处产生多尺度上下文特征。多尺度上下文特征用于初始化基于ConvGRU的更新操作符的隐藏状态,并在每次迭代时插入到ConvGRU中。
Combined Geometry Encoding Volume
拿到 f l , 4 f_{l,4} fl,4和 f r , 4 f_{r,4} fr,4,沿着通道维度将特征 f l , 4 ( f r , 4 ) f_{l,4}(f_{r,4}) fl,4(fr,4)划分为 N g ( N g = 8 ) N_g(N_g=8) Ng(Ng=8)组,并逐组计算correlation maps,构建一个4维的group-wise correlation volume:
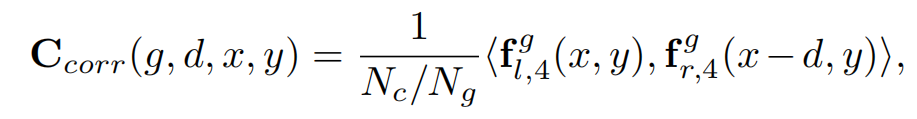
仅基于特征相关性的cost volume C c o r r C_{corr} Ccorr缺乏捕获全局几何结构的能力。(按照传统的立体匹配算法,此时需进行代价聚合)。为了解决这个问题,论文进一步使用轻量级的三维正则化网络 R R R进一步处理 C c o r r C_{corr} Ccorr,得到geometry encoding volume C G C_G CG:
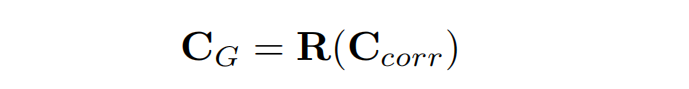
三维正则化网络 R R R 基于一个轻量级的3D UNet,它由三个下采样块和三个上采样块组成。首先论文遵循CoEx的方法,它用从参考图像(左图)的特征图计算的权重来激活cost volume的channels,以进行代价聚合,得到的guided cost volume表示为:
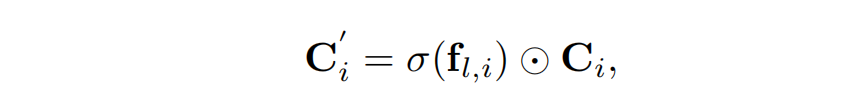
σ \sigma σ是sigmoid激活函数, ⊙ \odot ⊙是哈达玛积(Hadamard Product)。三维正则化网络 R R R 插入到guided cost volume的激活操作中,可以有效地推断和传播场景全局几何信息,从而得到geometry encoding volume C G C_G CG。同时,论文还计算了相应的左右特征之间的all-pairs correlations(APC),以得到局部特征相关性。
为了增大感受野,论文使用kernel size大小为2、stride为2的1D average pooling来池化视差维度,形成一个两层的 C G C_G CG特征金字塔和all-pairs correlation C A C_A CA特征金字塔。然后将 C G C_G CG和 C A C_A CA结合起来,形成一个组合的combined geometry encoding volume。
ConvGRU-based Update Operator
给ConvGRU-based Update Operator提供了一个更好的初始视差能够使得迭代视差优化更快地收敛。
论文使用soft argmin从geometry encoding volume C G C_G CG中回归出一个初始化视差 d 0 d_0 d0:
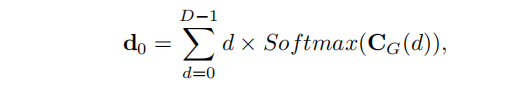
其中 d d d 是1/4分辨率的视差index。从初始化的输入视差 d 0 d_0 d0开始,论文使用三级ConvGRUs来迭代地更新视差。使用多尺度context features初始化三级ConvGRUs的隐状态(hidden state)。
对于每次迭代,论文使用当前的视差 d k d_k dk,通过线性插值对combined geometry encoding volume进行索引,生成一组几何特征 G f G_f Gf。 G f G_f Gf计算表示为:
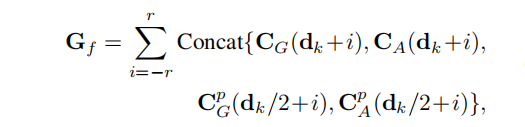
其中, r r r为索引半径, p p p表示池化操作。**这些几何特征和当前的视差预测 d k d_k dk通过两个编码器层,然后与 d k d_k dk连接形成 x k x_k xk。**然后使用ConvGRUs更新隐藏状态 h k − 1 h_{k−1} hk−1
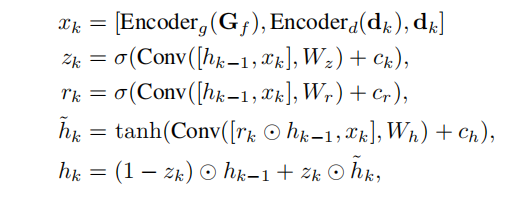
其中, c k c_k ck、 c r c_r cr、 c h c_h ch是由上下文网络生成的上下文特征。基于隐藏状态 h k h_k hk,论文通过两个卷积层得到视差残差 △ d k △d_k △dk,然后更新当前的视差:
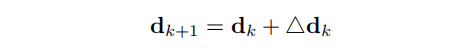
Spatial Upsampling
论文利用了在1/4分辨率下预测的视差 d k d_k dk,通过加权组合来生成完整分辨率的视差图
Loss Function
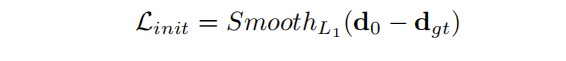
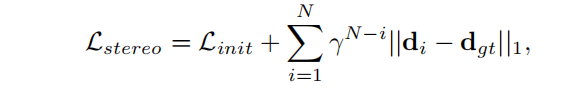
实验
消融实验
Effectiveness of CGEV
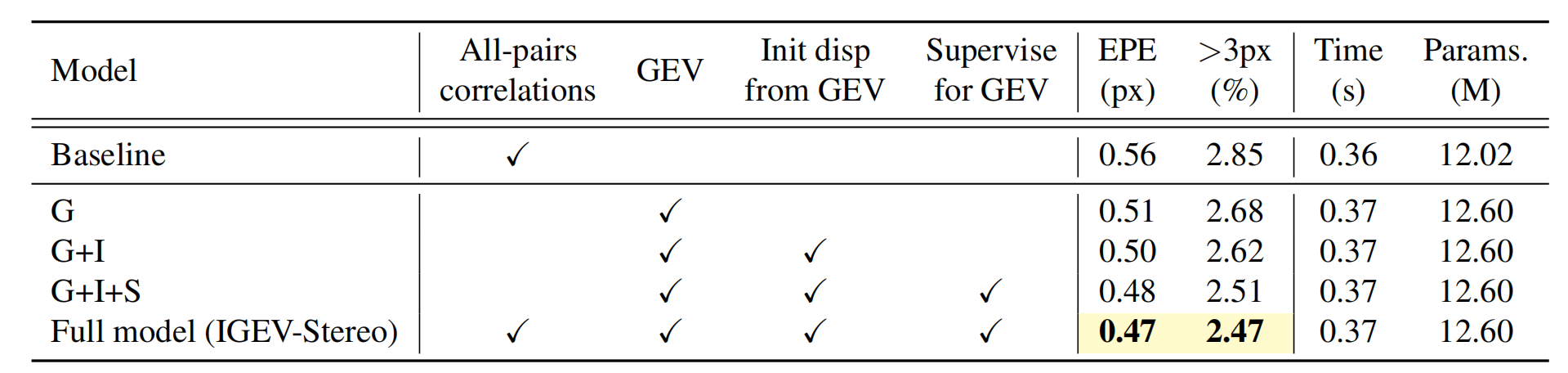
如表1所示,论文所提出的 geometry encoding volume(GEV)可以显著提高预测精度,因为GEV可以提供非局部信息和场景先验知识。为了补充局部相关性,论文结合了GEV和all-pairs correlations,形成了一个combined
geometry encoding volume(CGEV),表示为IGEV-Stereo,性能最好。
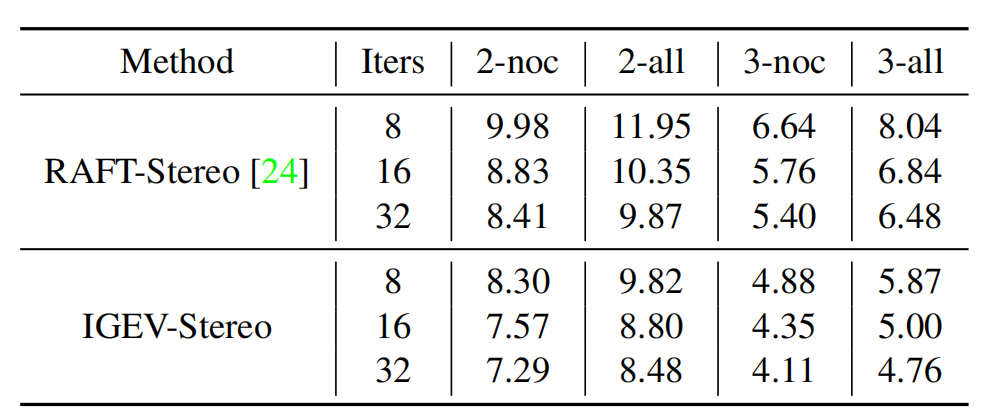
Number of Iterations
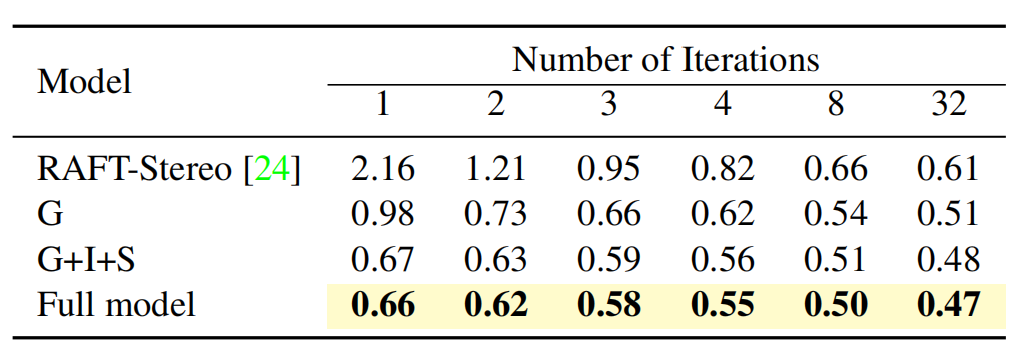
如表2所示,IGEV-Stereo即使经过很少的迭代,也已经达到了最先进的性能,使用户能够根据他们的需要来权衡时间效率和性能。
Configuration Exploration
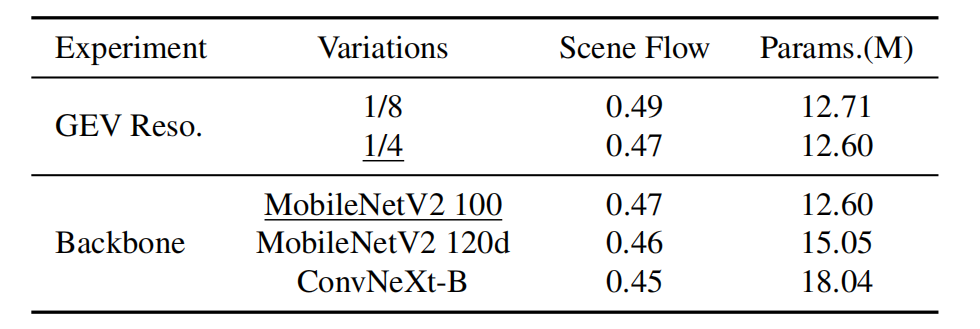
如表3所示,即使构建一个1/8分辨率的GEV,只需要额外的5ms,论文的方法仍然在Scene Flow上实现了最先进的性能。当使用具有更多参数的backbone时,即MobileNetV2 120d和ConvNeXt-B,性能可以得到提高。
Comparisons with State-of-the-art

如表4所示,在Scene Flow上,IGEV-Stereo实现了新的SOTA EPE 0.47。
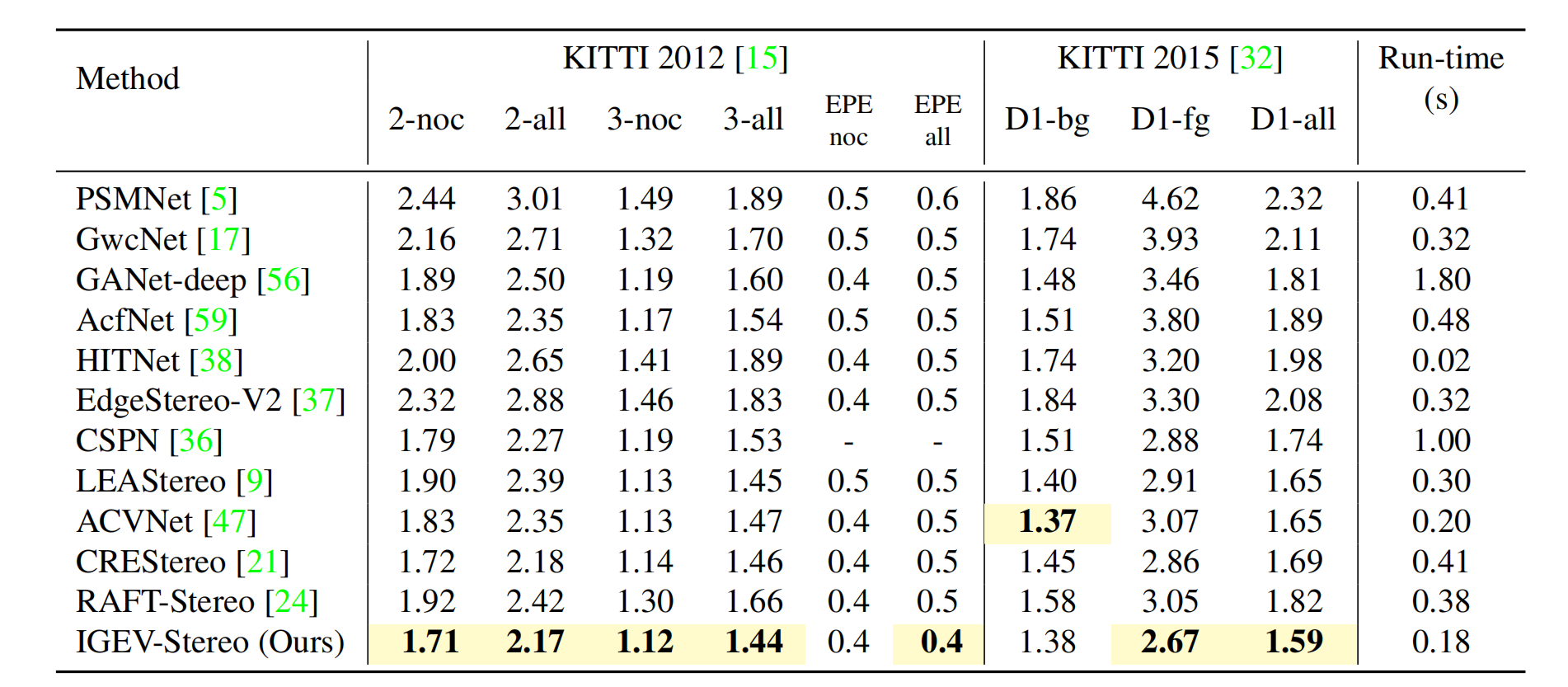
如表5所示,IGEV-Stereo在KITTI 2012和2015上的几乎所有指标都获得了最好的性能。在撰写本文时,IGEV-Stereo在KITTI 2015上实现SOTA。与其他基于迭代的方法如CREStereo和RAFT-Stereo相比,IGEV-Stereo不仅性能优于他们,而且还快了2×。
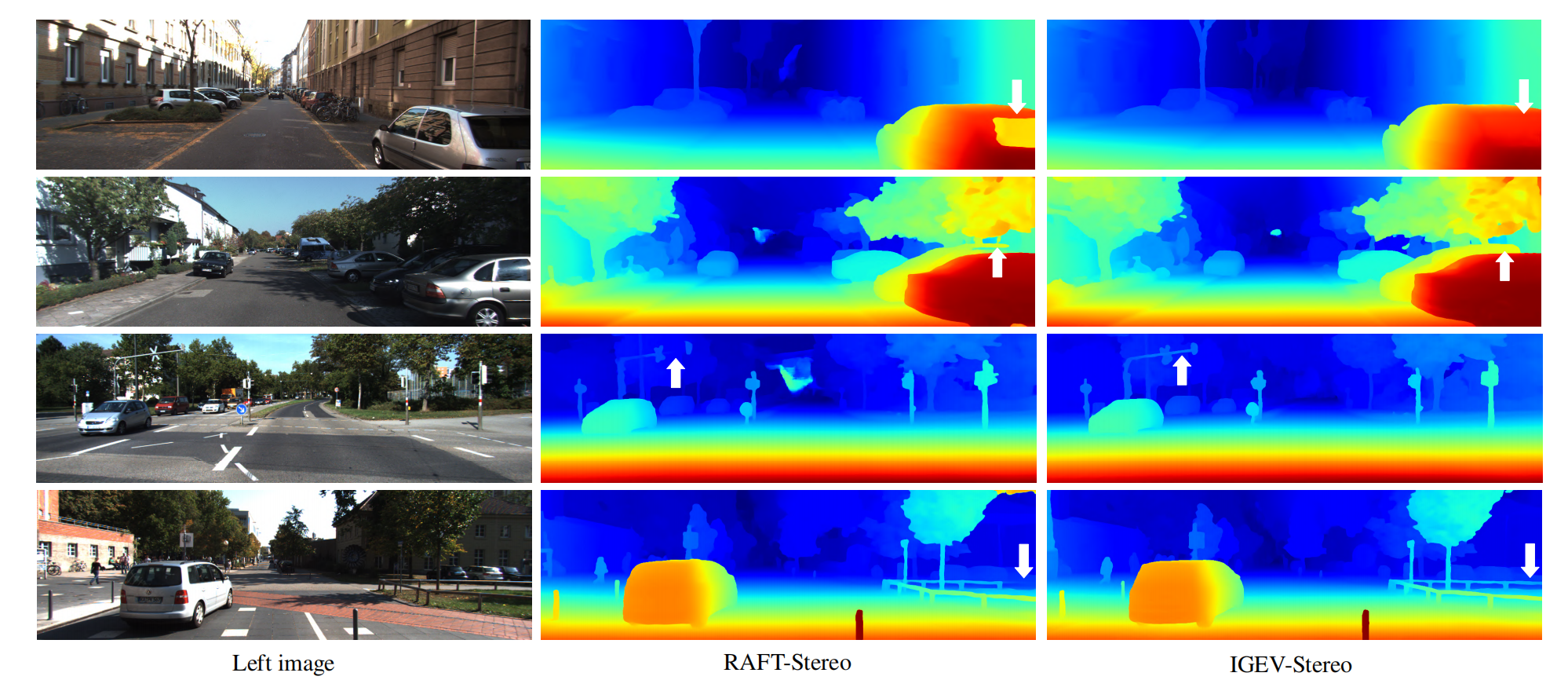
如上图所示,IGEV-Stereo在高反、无纹理和细节的区域中表现得非常好。
如表6所示,IGEV-Stereo在KITTI 2012的反射区域排行榜上排名第一,其表现远远优于RAFT-Stereo,IGEV-Stereo只使用8次迭代就比使用32次迭代的RAFT-Stereo性能更好
Zero-shot Generalization
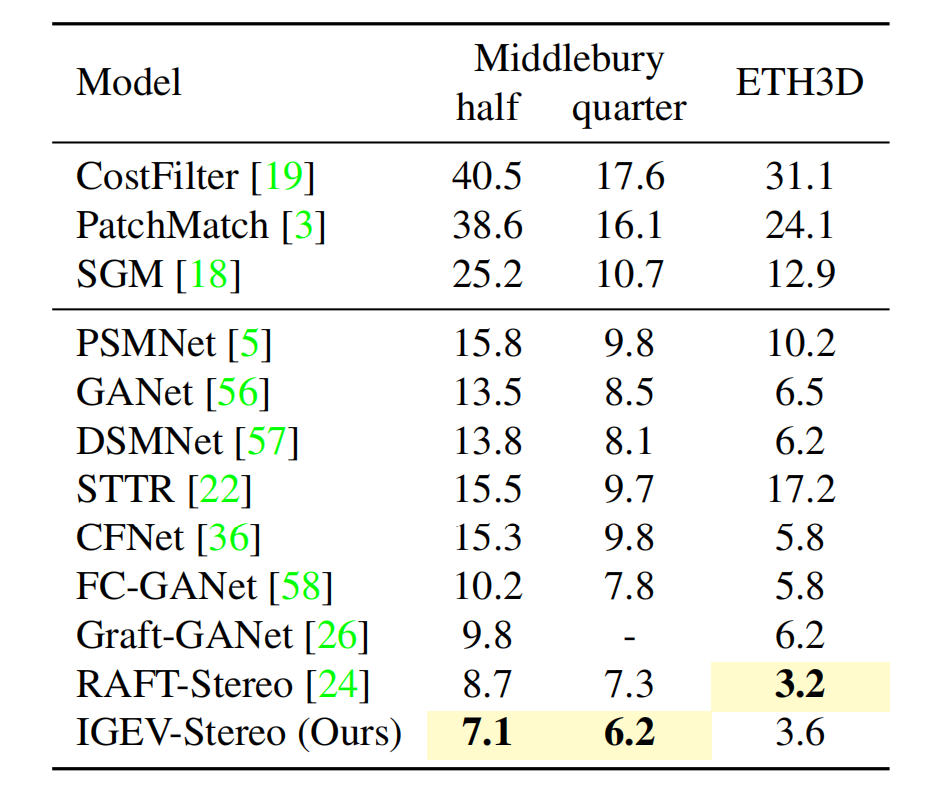
论文评估了IGEV-Stereo从合成数据集到看不见的真实场景的泛化性能。论文在合成的Scene Flow数据集上训练IGEV-Stereo,并直接在真实的Middlebury 2014和ETH3D训练集上进行测试。如表7所示,IGEV-Stereo在相同的zero-shot设置下实现了最先进的性能。

如上图所示,与RAFT-Stereo的视觉比较,IGEV-Stereo对无纹理和细节的区域更鲁棒。
Extension to MVS
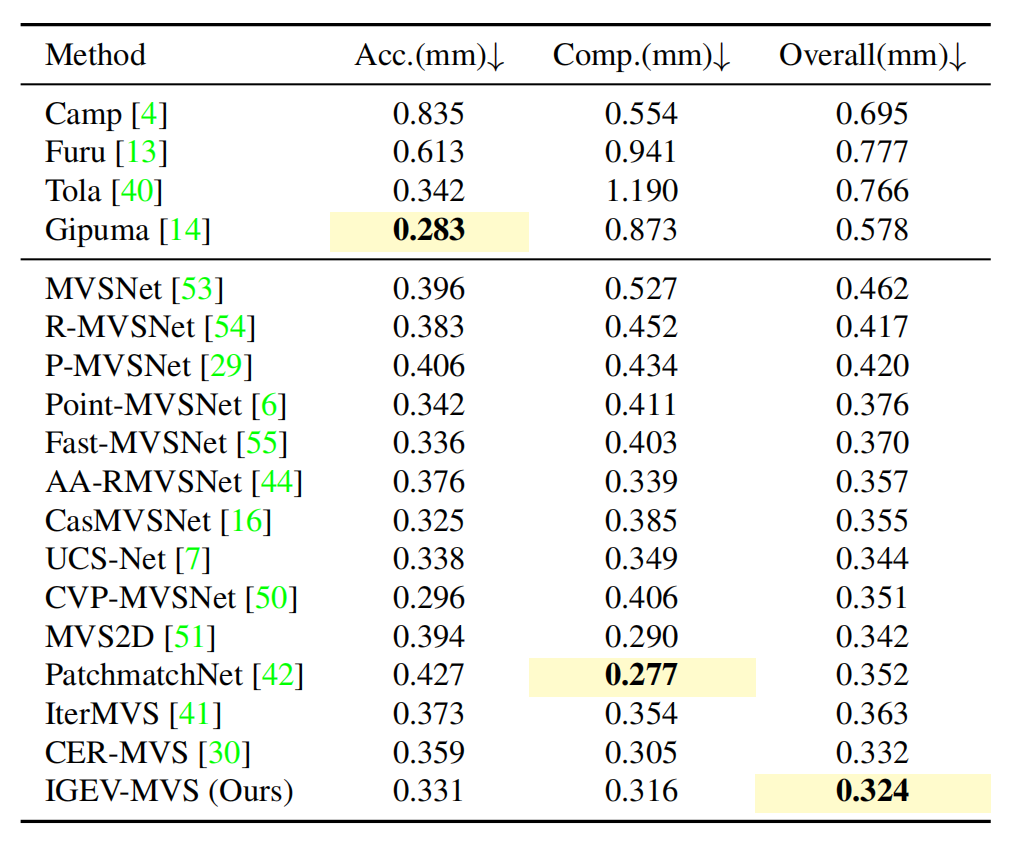

论文将IGEV扩展到multi-view stereo(MVS),即IGEV-MVS,在室内多视角立体数据集DTU benchmark进行评估。如表8所示,IGEV-MVS获得了最好的总体分,这是完整性和准确性的平均值。
总结
本文提出了Iterative Geometry Encoding Volume(IGEV),这是一种用于立体匹配和多视角立体视觉也的深度网络架构。IGEV构建一个combined geometry encoding volume编码几何和上下文信息以及局部匹配细节,并迭代地对其进行索引以更新视差图。IGEV-Stereo在KITTI 2015 leaderboard中排名第一,并实现了最先进的跨数据集泛化能力。拓展的IGEV-MVS在DTUbenchmark上也取得了具有竞争力的性能。
论文使用一个轻量级的3D CNN来过滤cost volume并获得GEV。然而,当处理显示出较大视差范围的高分辨率图像时,使用3D CNN来处理由此产生的大尺寸 cost volume仍然会导致较高的计算和内存成本。未来的工作包括设计一个更轻量级的正则化网络。此外,论文还将探索利用cascaded cost volumes,使本文的方法适用于高分辨率图像。
如果您也对人工智能和计算机视觉全栈领域感兴趣,强烈推荐您关注有料、有趣、有爱的公众号『CVHub』,每日为大家带来精品原创、多领域、有深度的前沿科技论文解读及工业成熟解决方案!欢迎添加小编微信号: cv_huber,备注"CSDN",加入 CVHub 官方学术&技术交流群,一起探讨更多有趣的话题!



















 2093
2093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











