






作者 | 金天 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/429029810
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【领域综述】获取自动驾驶全栈近80篇综述论文!
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
这篇文章一定要写一下,因为实在是太牛逼了,它就像是一个很强的选手,在众多的竞争者中脱颖而出,满足了你的所有幻想。那么它是哪篇论文呢?不是一篇去年的paper,而是刚刚出炉的K-Net。
论文链接:https://arxiv.org/pdf/2106.14855.pdf
代码链接:https://github.com/ZwwWayne/K-Net/
这篇文章为什么牛逼呢?总结一下几个理由:
你可以将其看作为SOLOV2(或者PanopticFCN)和DETR的合体,很多先进技术的聚合体;
集合了众多先进实例分割算法的优点,换句话说,速度更快,精度更高,就这一点,不比谁强?
统一了实例分割和全景分割,这一点我等一下会具体讲,有些方法的统一实际上是一种假的统一,方式其实并不对,没有统一的方式表达。
最后,OpenSource。
废话不多说了,直接上图:
可以看看这篇文章对于小物体的分割效果:

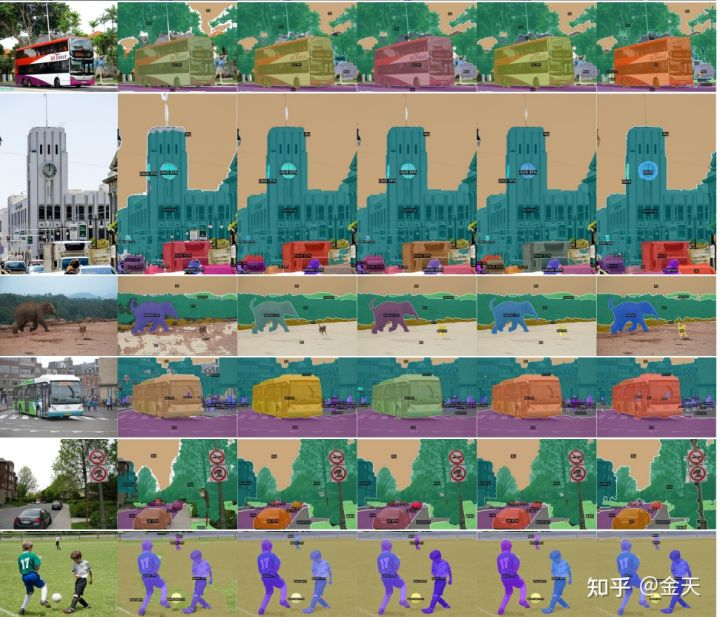
这个效果,只有一个表情包能表达我内心的震惊:

雀食牛逼。
那么问题来了,精度怎么样?
我们来挑选几个,大家比较熟悉的强有力竞争对手:
MaskRCNN
SOLOv2
CondInst
更有甚至,我们要把现在排行榜第一的老大也拉出来PK一下,battle battle:
CascaedMaskRCNN
好家伙,这可是一个大装置,一般人不敢用。我们来看看K-Net的表现:

简单来说就是,即使是在N-kernels =100的时候,它的精度也超过了MaskRCNN,请注意,这里的超过不是跟SOLOv2一样,APs很低,而是AP大中小都超过了,并且AP也更高,更重要的是,速度快了不少,17FPS vs 21.2 FPS,在V100上的速度。
当然对于SOLOV2和CondInst,更是全面超越。还有大装置的这个CascadeMaskRCNN,也可以在增加Num-kernerls配置的情况下超越。总体来说就是,速度更快,精度更高了。
1K-Net的结构
来看看Knet的结构,在说结构之前,大家可以思考几个问题:
为什么它可以通过kernels来直接预测mask;
它是如何将instance mask和semantic mask融合到一个统一的框架下的;
跟DETR有毛关系;
为什么不需要solov2里面的那种分网格的方式来获取位置信息,它又是如何获取的;
它可能会有什么缺点?
一图表示K-Net整个结构如下:

基本上还是PanpticFCN那一套,只不过这里面引入了一个新东西:动态kernel以及kernel的更新。这一点是再其他任何一个基于kernel预测mask的方法中都不存在的。这里有张图可以直接看到,加入kernel update之后对于效果的影响:
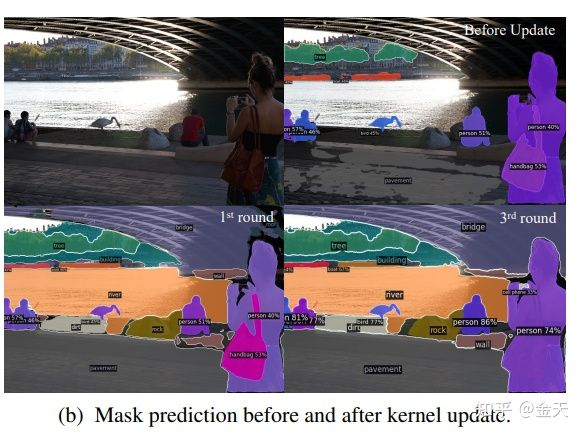
所以这个地方是一个比较大的创新点。然后其实我比较关心的是它训练的方式,为什么可以说是Box-Free, NMS-Free呢?由于引入了一个双向匹配的训练方式,这一点直接借鉴与DETR,只不过它使用的对象不是box,而是直接就是mask,这种匹配方式就可以让你再训练的时候,一个Kernel就是负责预测一个instance,不会出现重复的kernel,(这个地方其实我也没有太搞清楚,是否跟DETR一样,需要一个pixel wise的后处理才能得到最后的结果),这样就可以直接从kernel,来生成某个一个instance的mask,非常简单,不需要任何涉及到box的后处理。
2消融实验
K-Net当中也引入一些新的概念,比如 动态更新的kernel 头部设计,kernel的数目设置,以及位置信息的影响,再论文中也做了比较详细的消融实验:

可以看到,Kernel Iterator这个组件应该是整个performance的核心,没有它,就崩掉了。这里也给其他基于kernel方法提供了一个很好的思路,作者是怎么想到做这么个东西去解决直接kernel预测带来的问题的,值得思考 其次就是kernel说的数目得到设定,这一个参数和detr里面的num_queries比较像。这也从侧面反映出,我一开头说的,它更像是用动态的卷积来实现了类似于transformer当中的key和query的思想。结果显示,非常的高效。从某种意义上来说,二者有相似之处。不过这是不是也意味着,假如我们在transformer中也引入一个动态更新的思路,是不是也可以进一步增强transformer的performance?值得思考。
3结论
最后结论如下:
本文探讨了可以在分割期间学习分离实例的实例内核。因此,以前辅助实例分割的额外组件可以被实例内核取代,包括边界框、嵌入生成和手工制作的后处理,如 NMS、内核融合和像素分组。这种尝试首次允许通过统一框架处理不同的图像分割任务。该框架被称为 K-Net,首先通过学习的静态内核将图像划分为不同的组,然后通过从分区组组装的特征迭代地细化这些内核及其对图像的分区。K-Net 在全景和语义分割基准上获得了新的最先进的单模型性能,并在最近的实例分割框架中以最快的推理速度超越了完善的 Cascade Mask R-CNN。我们希望 K-Net 和分析为未来统一图像分割框架的研究铺平道路。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
















 1978
1978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









