






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
回望传统光流估计方法
近年来,随着深度学习技术的快速发展,基于深度学习的光流估计技术已成为光流研究领域的热点与主战场。然而,当前很多刚接触光流算法研究的同学直接从深度学习方法开始,大跃进式的迈过了传统光流估计理论与方法。虽然,这并不影响他们产出高质量的研究成果,但是,对传统光流估计方法原理和理论还是有必要进行一定程度的学习。基于此,本文将主要从以下四个方面介绍传统光流估计方法:
光流的定义与应用;
传统光流估计方法的分类;
经典的变分光流估计模型;
传统光流估计方法在深度学习方法中的应用。
光流的定义与应用
当我们的眼睛在观察运动物体时,运动物体的景象会在我们眼睛的视网膜上产生一系列连续变化的图像,就像水流一样不断流过视网膜(即图像平面),故称之为光流。将其理论化,则有光流是指空间中运动物体在观测成像表面上的像素点运动瞬时速度。其不仅包含了被观察物体的运动信息,而且还包含有关景物丰富的三维结构信息。
此外,光流产生还需要3个必备的条件:
运动,这是光流形成的必要条件,没有运动就没有像素的位移;
带光学特性的部位 (例如有灰度的像素点 ) ,它能携带信息;
成像投影即从场景到图像,能被观察到。
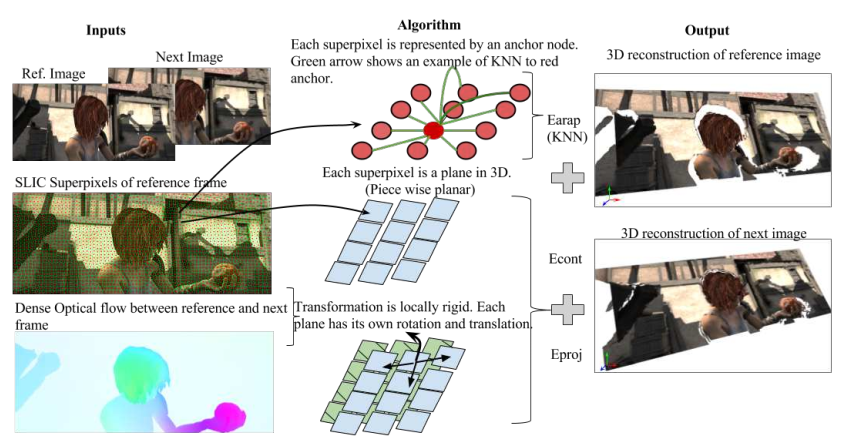
图1展示了光流在三维重建工作中的应用,从图中可以看到,通过利用光流包含的结构信息可以较好的实现场景的3D重建
因此,研究光流的目的就是从光流中恢复物体三维结构和运动,进而为更高级的视觉任务提供可靠支撑。
目前,光流估计技术已经应用于自动驾驶、无人机定位导航、影视特效以及目标跟踪等领域,几乎与人们生产生活息息相关。下方展示了光流在影视特效中的应用。
传统光流估计方法的分类
在深度学习兴起之前,实现光流估计的方法主要分为:
基于相位的方法;
基于能量的方法;
基于匹配的方法;
基于变分的方法。
下面逐一介绍。
1.基于相位的方法
Fleet和Jepson最先提出将相位信息用于光流计算的思想。他们认为相比图像亮度信息,图像的相位信息更加可靠,利用相位信息获取的光流更加鲁棒。
基于相位的光流估计方法首先利用Gabor滤波器计算图像序列的相位时间梯度,然后,过滤给定时间跨度的非线性相位时间梯度,最后,在一个位置的剩下的相位时间梯度使用递归的神经网络计算出该位置的速度。下图是Fleet和Jepson所提方法的光流估计结果。
其优点在于对图像序列的适用范围较为宽泛,而且速度估计比较精确,缺点在于具有较高的时间复杂性且对图像序列的时间混叠较为敏感。
2.基于能量的方法
该方法利用调谐滤波器的输出能量达到最大来计算光流,由于调谐滤波器是在频域中设计的,因此该方法也称为基于频率的方法 。然而,在使用该类方法的过程中,如果要获得均匀光流场的准确估计,就必须对输入的图像进行时空滤波处理,但这样会降低光流的时间和空间分辨率。并且会涉及大量的计算,因此该方法时间成本较大。
3.基于匹配的方法
基于匹配的光流计算方法又分为基于特征和区域的两种。
基于特征的方法不断地对目标主要特征进行定位和跟踪,对目标大的运动和亮度变化具有鲁棒性。基于区域的方法先对类似的区域进行定位,然后通过相似区域的位移计算光流。他们获的光流方法均是稀疏的。
4.基于变分的方法
基于变分原理的光流估计方法是将光流估计问题归结为求解某个能量泛函的极值问题。因其在模型构建、计算精度以及性能鲁棒性等方面相比上述方法具有显著的优越性,在深度学习方法兴起之前一直是光流研究领域的主流方法。
经典的变分光流估计模型
HS模型
提到变分光流估计模型就不得不提经典的HS光流估计模型。1981年,Horn和Schunck 提出通过最小化全局能量函数来计算每个像素的位移向量。其中,该全局能量函数是基于灰度守恒假设(BCA) 的数据项和平滑项的组合。假设移动像素的灰度随时间保持恒定,则在数学上,可以表述为:
这里I表示图像序列,I(x,y,t)表示在t时刻像素点的灰度,I(x+u,y+v,t+1)表示在t+1时刻下一帧像素点灰度。为了对方程进行优化, HS 应用一阶泰勒展开来线性化方程的右半部分,则可得到近似值:
这就是众所周的光流约束方程,为了便于书写将上式可以重写为如下:
其中,X=(x,y) 是像素点坐标, w=(u,v) 是光流。
基于灰度守恒,则光流变分能量函数的数据项可以被写为:
然而,仅利用灰度守恒原理难以获得唯一解。所以,为了克服歧义,HS 提出了一个平滑约束,该约束规定流场应该平滑变化,因为相邻像素往往具有相似的运动。换句话说,一个点 (𝑥, 𝑦) 与其相邻点之间的流量变化接近于零,于是便有
依据平滑假设,则变分光流能量函数的平滑项可以被定义为:
将数据项与平滑项进行结合,则HS全局能量函数可以写作:
其中, 是权重因子,用于平衡两项。
最后,通过优化该能量函数便可以得到最终的光流w。该方程也可看做是变分光流估计中鼻祖级的能量方程,此后,所有变分光流估计方法几乎都以此能量方程为基础。
通常,对HS方程的改进方法主要有以下几个方向:
对数据项进行改善,以提高数据项的保真能力;
对平滑项进行重新设计,以控制光流扩散的程度与方向;
增加附加约束,解决特定场景下光流估计问题;
提出不同的优化与计算策略以提高复杂场景光流估计精度。
例如,由于灰度守恒对光照变化不敏感,研究人员就是用对光照变化更为鲁棒的梯度守恒策略代替灰度守恒,则数据项可以被改造为:
其中,=(/,/) 表示图像空间梯度。
由于HS方程中的平滑项是线性扩散的,容易模糊包含图像重要信息的边缘,因此,平滑项又被改造为基于各向同性的图像驱动平滑项:
再如,为了解决大位移光流估计问题,Brox等人在能量函数中的附加了匹配项,也就是LDOF光流估计模型。
其中,w=(u,v)是光流,w表示表示描述符在某些点x处匹配得到的对应向量。前两项是灰度守恒和梯度守恒假设,最后两项的附加的匹配项与描述符。
此外,通过引入由粗到细(coarse-to-fine )的金字塔优化策略也可以解决大位移光流估计不准确问题。下图中(a)表示了由粗到细的金字塔模型,(b)是原始图像,(c)是金字塔第三层,(d)是金字塔第四层,(e)是估计出的光流可视化结果

从上述的模型变化可以看出来,变分光流估计朝着越来越复杂的方向狂奔而去。
Classic+NL模型
在变分光流估计方法中,Classic+NL是继HS经典模型后的又一个经典模型。该方法的作者是光流研究领域的大牛 Deqing Sun所提出。他详细探索了HS各种改模型中不同改进方法对模型性能提升的具体的原因。并发现中值滤波启发式的方法可以有效提高模型光流的估计的准确性与鲁棒性。
将经典的HS模型离散化:
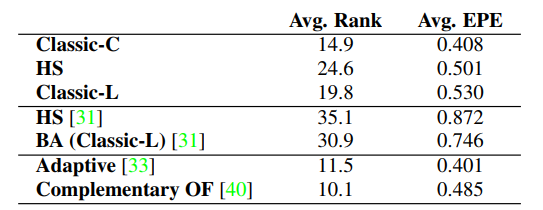
是惩罚函数,常用的有二次惩罚函数(x)=x,Charbonnier惩罚函数 (x)=(x+)以及Lorentzian惩罚函数(x)=log(1+x/2 )。作者将各个惩罚函数分别加入模型进行测试,以观察各惩罚函数的效果,如表所示。
接着,作者又探索了图像预处理技术、由粗到细策略以及GNC优化策略对模型的影响。其中,作者发现中值滤波启发式的方法对模型性能的提升具有显著作用。下图中左侧为使用中值滤波技术的光流估计结果,右图是未使用中值滤波技术的光流估计结果,可以看出在经典模型中加入中值滤波技术可以显著提升光流估计的效果。

尽管,中值滤波技术可以提升光流估计的精度,但是作者认为这种中值滤波方法还存在一定缺陷,即没有考虑像素点之间的距离、颜色以及遮挡因素的影响。为此,他设计了一种非局部加权中值滤波方法。该方法简而言之就是在HS能量函数中附加非局部约束项,其中非局部约束项如下所示:
其中,u''和v''是辅助光流,辅助优化能量函数。w是权重,根据空间距离、颜色值距离和遮挡状态定义,也就是加权中值滤波中的加权。
这里,0是遮挡变量,I(i,j)是Lab颜色空的颜色矢量,是常量均为7。下图展示了滤波窗口内加权与非加权中心像素点与邻域像素间的关系。
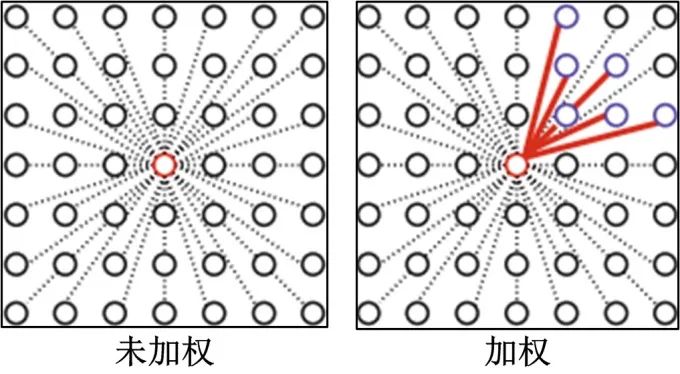
下图显示了15*15邻域空间内权重示例,其中, 明亮的值表示较高的权重。在d区域,由于步枪上的像素很少,因此未加权的中位数会过平滑。相反,加权项使用步枪上的值稳健地估计运动。

最终,Classic+NL模型可公式化为:
该图展示了使用中值滤波与非局部加权中值滤波技术光流估计效果对比,左图为中值滤波,右图为非局部加权中值滤波,可以看出Classic+NL方法具有更高的光流估计精度。

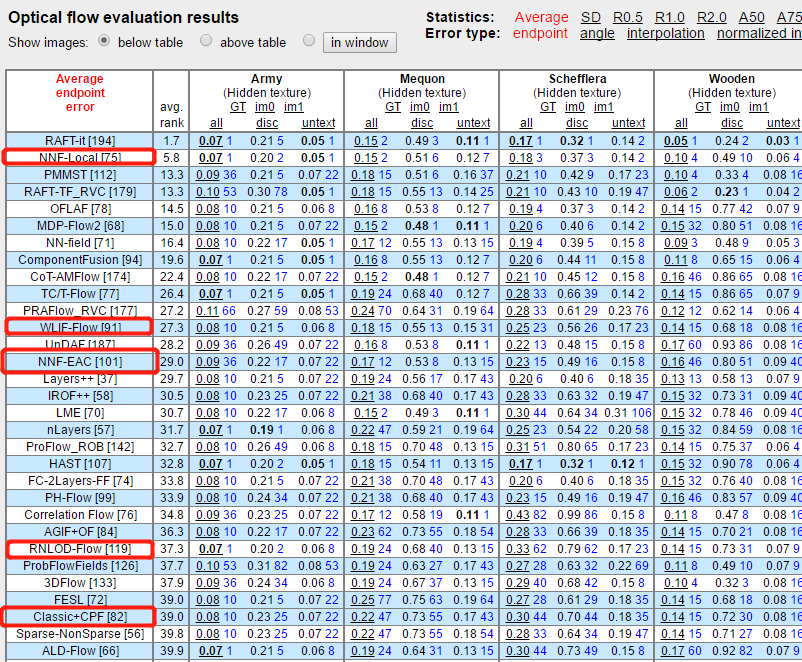
正是由于Classic+NL出色的光流估计性能,在此之后,很多方法都在此模型上进行改进。下图是Middlebury数据集排名,其中标记出的排名靠前的传统方法中均有Classic+NL的身影。
经典光流估计方法在深度学习方法中的应用
虽然,当前基于深度学习的光流估计方法在准确性与鲁棒性方面已经超越传统方法,并且达到了实时估计。但这并代我们可以完全抛弃传统方法。实际上,目前很多深度学习方法均采用了传统方法中的相关技术。
例如,SpyNet 将经典的空间金字塔方法与深度学习结合来计算光流的模型,并引入传统方法中的变形技术(warp)与纯深度学习方法FlowNet相比,它不需要处理大的运动,这些均交给空间金子塔处理,因此,SpyNet模型更小、参数更少。
LiteFlowNet为了解决光流场在动边界出现的模糊与伪影问题,其借鉴传统方法中的各向异性图像驱动、图像和光流驱动的正则化概念。在级联流推断之后,允许流场通过特征驱动局部卷积层在每个金字塔级别进一步正则化, 有效的保护光流边缘。
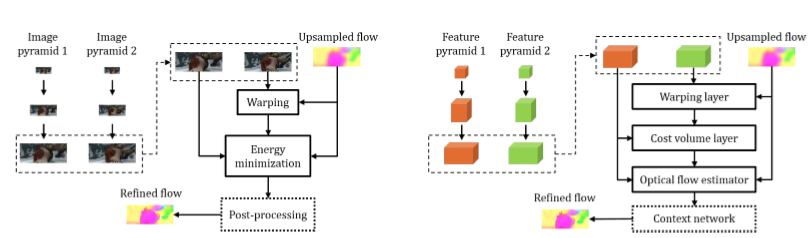
PWC-Net网络的设计更是遵循了传统方法中三个简单而成熟的原则:金字塔处理、变形(warping) 操作和代价计算 (cost volume),不仅获取了高精度的估计效果,而且实现了模型尺寸与计算精度之间的平衡。下图展示了传统金字塔处理与PWC-Net方法的异同:
可能有人说了,有没有直接将变分方程与深度学习结合的方法?答案当然是有的,不过这些方法一般应用于无监督光流估计模型。因为,无监督学习没有真实值作为收敛对比的条件,因此需要自己设计损失函数以实现模型的训练收敛,而这些损失函数一般往往都借鉴于变分方程。例如Jsaon J等人发表的”Back to Basics: Unsupervised Learning of Optical Flow via Brightness Constancy and Motion Smoothness"无监督光流估计方法。题目中就很直白的说了他们使用了灰度守恒和平滑正则,所以他们网络模型的损失函数为:
且:
是不是很熟悉??是不是跟Classic+NL前半部分很像?
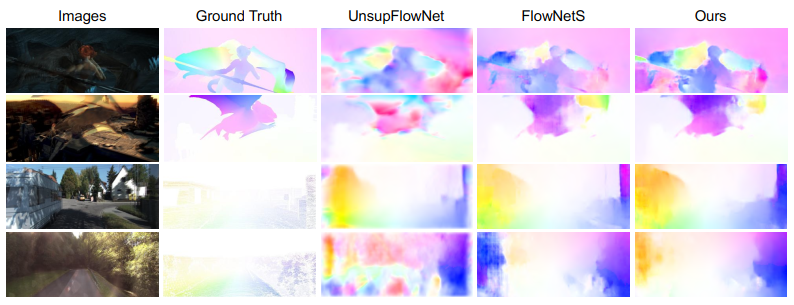
同样的,后续的无监督的方法也在该损失函数上进行改进,例如UnFlow在该损失函数上引入了遮挡感知,上海交大的Zhe Ren等人在损失函数的数据项引入了梯度守恒;Rico Jonschkowski等人设计了一种边缘感知的一阶和二阶平滑项等等。虽然,上述方法可以实现无监督学习模式的光流估计,但是其精度与鲁棒性相比于监督方法还差很多,但整体准确性在逐步提高。下图展示了无监督学习光流估计与监督学习方法的对比。最近,武汉大学的涂志刚教授在IEEE TIP发表了题为“Unsupervised Learning of Optical Flow With CNN-Based Non-Local Filtering ”的无监督光流估计方法,该方法首次将非局部滤波的思想引入无监督光流估计。

此外,传统方法还在半监督光流模型中得到采用,如在“GuidedOpticalFlowLearning”论文中,作者用变分方法计算出得光流来引导深度学习模型训练,从而减少模型对标签数据的依赖。
总结一下,尽管,深度学习光流估计方法在计算精度、泛化性以及时效性方面,已经全面超越传统方法。但这并不代表我们需要全盘放弃对传统方法的研究与思考,实际上,通过对传统方法的研究与理解可以指导我们在深度学习光流估计领域创新。
往期回顾
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、多传感器融合、SLAM、光流估计、轨迹预测、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









