






作者 | 隆啊隆 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/567496850
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【2D检测综述】获取鱼眼检测、实时检测、通用2D检测等近5年内所有综述!
来分享一下我们ICLR 2022的文章DAB-DETR, 我们将在这里介绍文章的主要内容,以及我们对于目标检测问题的思考。
论文链接: https://arxiv.org/abs/2201.12329
论文代码:https://github.com/IDEA-Research/DAB-DETR
另外我们提供了官方的基于Transformer检测工具包detrex ,这一工具包包含了DETR, Deformable DETR, Conditional DETR, DAB-DETR, DN-DETR, 以及在COCO获得了63.3AP的DINO,并将进一步支持更多的DETR类模型:
https://github.com/IDEA-Research/detrex
TL;DR
DAB-DETR提出了一种新的建模DETR中query的方式,使用4维的anchor box,这一建模方式不仅使得DETR query有了可解释性,同时作为位置先验可以加速模型收敛,以及利用box的尺度信息调制注意力图。
这一建模方式也将DETR类模型和传统的two-stage模型如Faster RCNN联系了起来。decoder中cross-attention的作用类似于ROI pooling或者ROI align,我们称之为soft-ROI pooling。
模型性能:
| 模型 | mAP(原始 repo) | mAP(基于detrex) |
|---|---|---|
| DETR-R50 (500 epoch) | 42.0 | - |
| DAB-DETR-R50 (50 epoch) | 42.2 | 43.3 |
| Deformable-DETR-R50 (50 epoch) | 46.9 | - |
| DAB-Deformable-DETR-R50 (50 epoch) | 48.7 | 48.9 |
我们的formulation可以使用在原始DETR或者Deformable DETR上,都能相比于原始模型带来很大的增益。另外,基于我们新的算法库detrex 的模型带来了更好的结果。
文章内容简述
动机和分析
DETR作为首个使用Transformer做目标检测的模型,非常具有创新性。他将目标检测建模成集合预测的任务,即输入一组(如100个)learnable的query,然后输入对应数量(如100个)的物体预测结果。在训练过程中,使用二分图匹配预测和标签进行训练,而测试时不需要后处理(如nms)即可产生所有结果。
尽管很简单、优雅,但是DETR存在两个问题,一是query含义并不清楚,不可解释,二是模型收敛慢。本来这应该是两个独立问题,不过后来我们发现,DETR收敛慢很大程度上来自于query含义的不明。
DETR中的query
在原始的DETR文章中的object query画的比较简单,可能会让人觉得query就是一组向量:
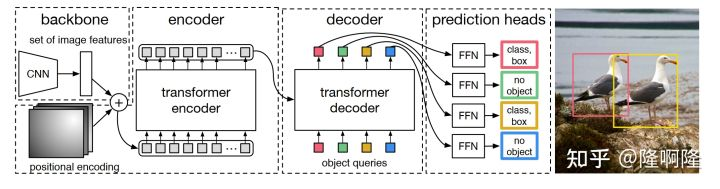
然而实际上object query应该有两部分组成,我们称之为content query和positional query(这里感谢conditional detr,这两个名字由他们提出。)我们这里画出来了encoder和decoder中的attention的组成部分。
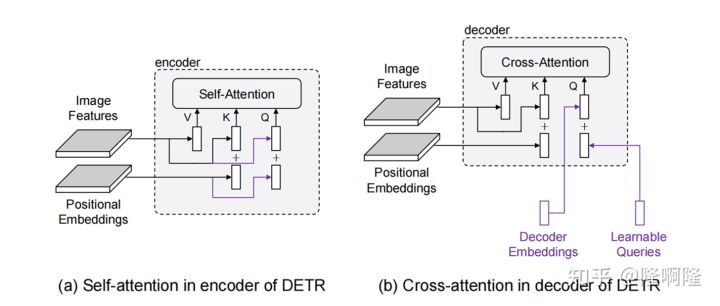
可以看到,encoder和decoder里attention和query和key都是由两部分组成的,比如encoder里的query分别来自于图像特征(包含语义信息)和位置编码(包含位置信息),因此这两部分分别称为content query(对应图像特征)和positional query(对应位置编码)。key和query完全相同。value只有图像特征这一语义部分。
再看decoder,decoder的key和value与encoder的组成完全相同,但是query则不同。query的语义部分来自于decoder embeddings,对应上层的输入,是由图像特征组合来的。而位置部分则来自于learnable queries,这是与我们看DETR的框架图后的第一反应不同的。因此decoder的learnable query实际指代的是位置信息。
Cross-attention的作用与soft-ROI pooling
接下来我们想来说明一下cross-attention在做什么,以及与传统的Faster RCNN之间的关系。
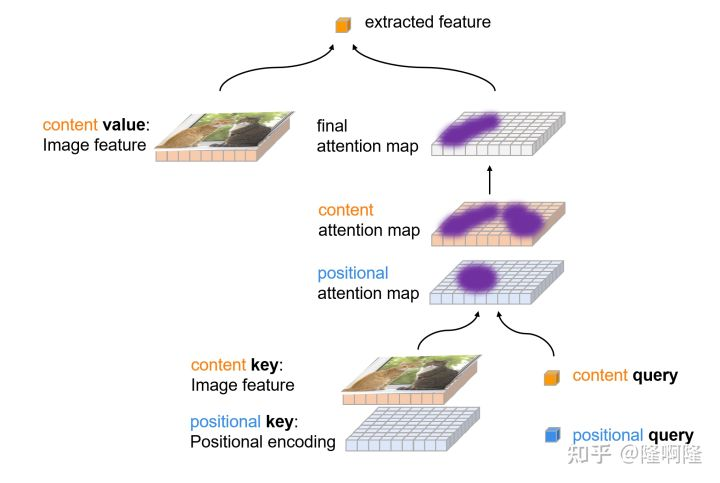
我们看到,在attention模块中,query和key计算相似度,同时考虑了content信息和positional 信息,计算出一个注意力图,然后使用这个注意力图从原始图片特征中提取特征。
这个步骤非常类似于传统两阶段检测器中的ROI pooling(或者ROI align)。但是由于注意力图是有query和key共同决定的,并不局限于物体框内信息,我们称之为Soft ROI pooling。
将query建模成anchor box
learnable query 不够好
既然了解了attention及decoder的作用,下面我们看原始的detr中query问题在哪。
我们发现,原始的learnable query学习到的特征并不够好,即不能提供soft roi pooling中所需的roi信息。

如图,训练前后的learnable query产生的位置注意力图仍然存在多模式、退化解等现象,并不能为soft roi pooling提供roi的信息。
那么很自然的,我们意识到,要为cross attention提供更好的位置先验,提供更好的roi region。很自然的,传统两阶段检测器中的anchor box可以引入到模型中作为位置先验。
引入anchor box作为query提供位置先验
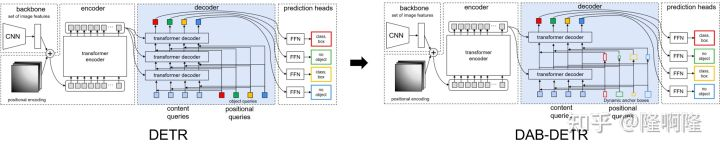
将anchor box引入之后的好处有:
query有了可解释性。
为模型提供了位置先验,加速收敛。
anchor box中的位置信息可以用来调制注意力图。
anchor box可以层与层进行更新。
anchor box直接提供了roi区域用来做soft roi pooling,因而这一描述也更加的自然。
模型改进简述
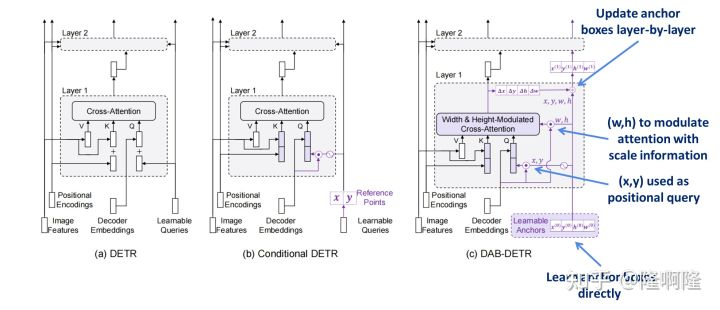
我们将我们的模型和DETR&Conditional DETR的对比列了出来。我们核心改进有:
直接学习anchor box作为query
使用正余弦编码后的x,y作为positional query
使用w,h调制注意力图
层与层更新anchor box
DAB-Deformable-DETR
我们的建模方式也是通用的,我们将anchor box的建模方式用到deformble DETR里,依然能带来性能的提升。
DETR类模型对比
我们在文章里做了很多对比,包括将DAB-DETR和之前的DETR系列做对比:
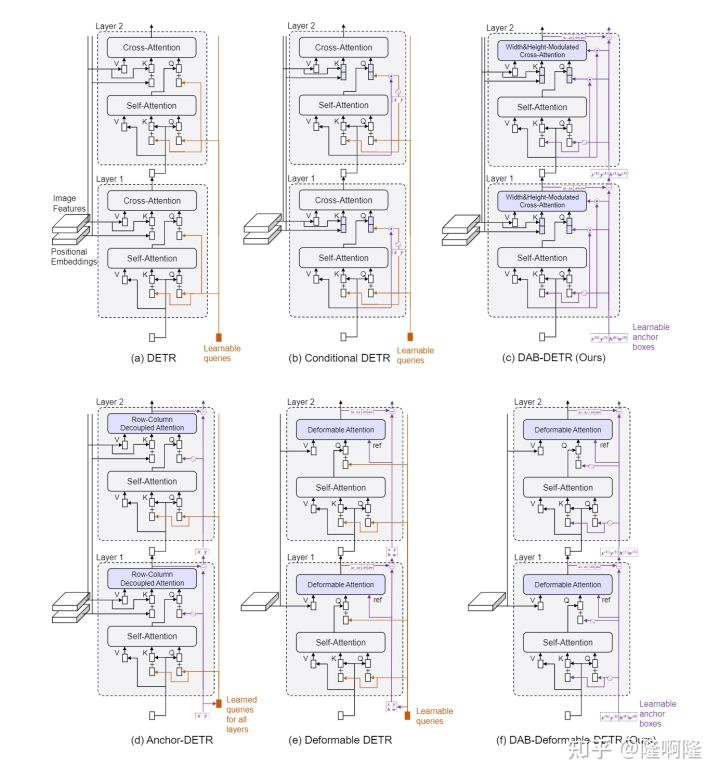
DAB-DETR & Faster RCNN
这里其实更想和大家分享关于DETR和传统检测器进行对比。从我们的讨论中我们看到,DETR中的encoder起到了特征增强的作用,类似于一个non-local的模块。
而更令人着迷的decoder则起到了类似于two-stage模型中ROI head的作用,通过Soft ROI pooling的方式不断从特征图中采集特征,进行box的回归。而多个decoder layer又起到了类似于cascade RCNN,类似于级联的ROI head的效果。
那么现在来看除了结构上(Transformer和卷积)以外,DAB-DETR和Faster RCNN还有哪些区别:
一是box产生的方式。Faster RCNN来自于RPN,而DAB-DETR来自于learnable的anchor box(从这个意义上 DAB-DETR更像是Sparse RCNN)。那如果我们也将DAB-DETR的anchor box来自一个RPN或者encoder输出(Deformble DETR 已经做了),我们也可以构造一个two stage的DAB-DETR,也会有更好的性能。
二是标签分配的方式。DETR类模型的匹配是匈牙利匹配,one-to-one,同时考虑content和position,在layer之后;而Faster RCNN是one-to-many(一个gt可能对应多个anchor),只考虑position,在layer之前。那么最理想的匹配方式是什么?有没有更好的匹配方案?也是一个值得研究的问题。这里推荐peize大佬的一篇文章What Makes for End-to-End Object Detection?-ReadPaper论文阅读平台很有启发意义。
综上,DETR结构也可以看做是一种two stage模型,只是用了不同的模型结构(Transformer)和标签分配方式(匈牙利匹配)。
那么从研究的角度出发,之前在two stage models领域的很多研究,或许都可以搬到DETR/DAB-DETR这么一个框架下来,欢迎大家能和我们一起探索这一领域。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、多传感器融合、SLAM、光流估计、轨迹预测、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!


















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









