







 本文介绍了ICLR2022的DAB DETR,它通过引入可学习的锚框改进了DETR系列模型,以适应不同尺寸的物体检测。模型结构包括空间注意力热图、详细结构、模型详解,特别是宽高调制的cross-attention模块。此外,还讨论了设置温度系数的重要性,并提供了代码讲解,涉及decoder及其layer的实现。
本文介绍了ICLR2022的DAB DETR,它通过引入可学习的锚框改进了DETR系列模型,以适应不同尺寸的物体检测。模型结构包括空间注意力热图、详细结构、模型详解,特别是宽高调制的cross-attention模块。此外,还讨论了设置温度系数的重要性,并提供了代码讲解,涉及decoder及其layer的实现。
DETR系列文章之–DAB DETR
文章目录
前言
介绍ICLR2022发表论文DAB-DETR论文基本思想即代码实现。DETR-Conditional DETR-DAB DETR
代码地址
论文地址
CSDN解读
一、模型结构
DAB-DETR认为原始DETR系列论文中:可学习的query仅仅给模型预测bbox提供了参考点(中心点)信息,没有提供box的宽和高信息。考虑引入可学习的锚框来使得模型能够自适应不同尺寸的物体。
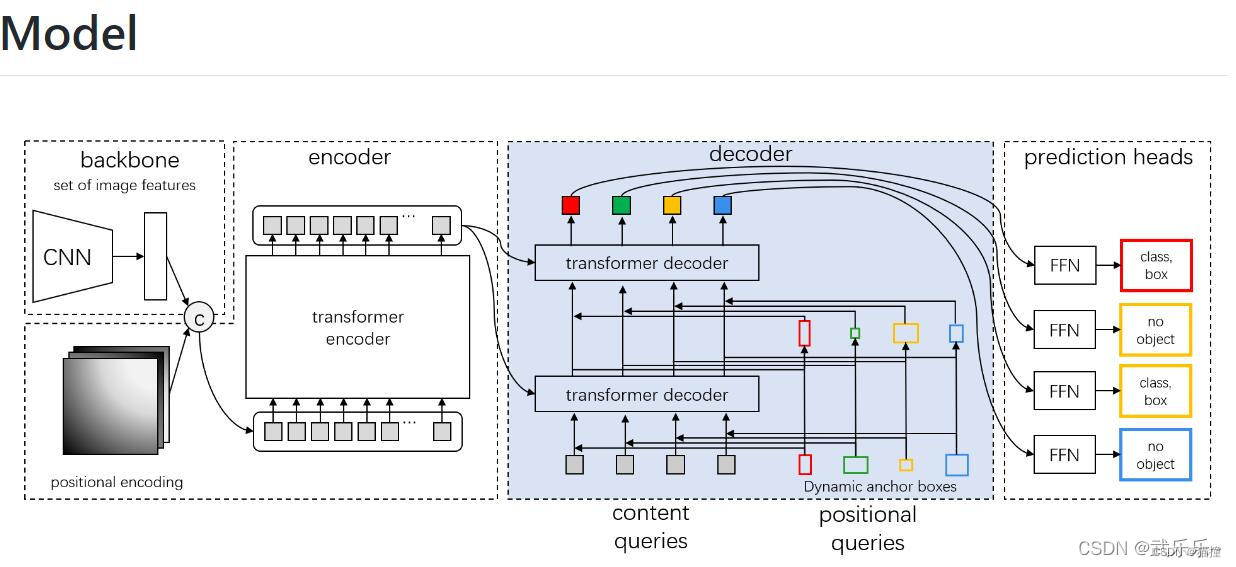
object query中content query和key计算相似度完成特征提取,pos query用于限制提取区域的范围及大小
1.1 空间注意力热图可视化
可视化三个模型的空间注意力热图pk*pq,热图参考添加链接描述,DAB-DETR能够很好覆盖不同尺寸的物体。

1.2 详细结构
DAB-DETR直接预设N个可学习的anchor,类似SpareRCNN。然后经过宽高调制cross-attention模块,预测每个anchor box四个元素偏移量,更新anchor.
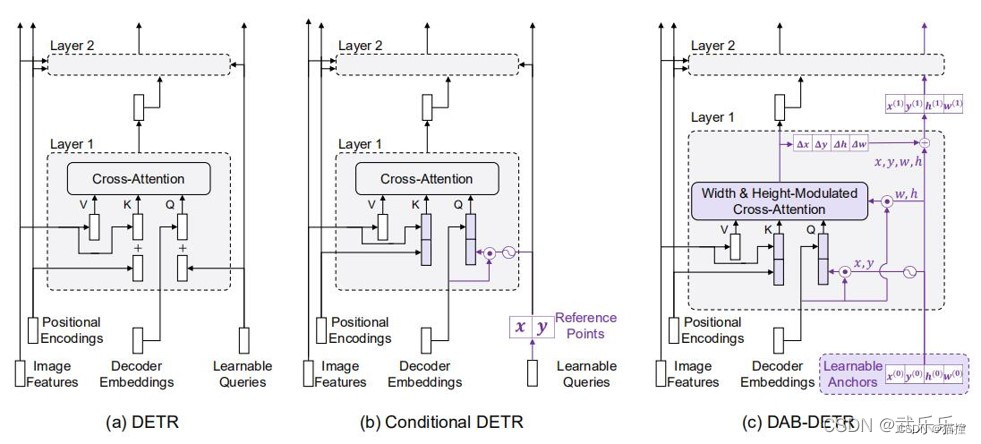
1.3 模型详解
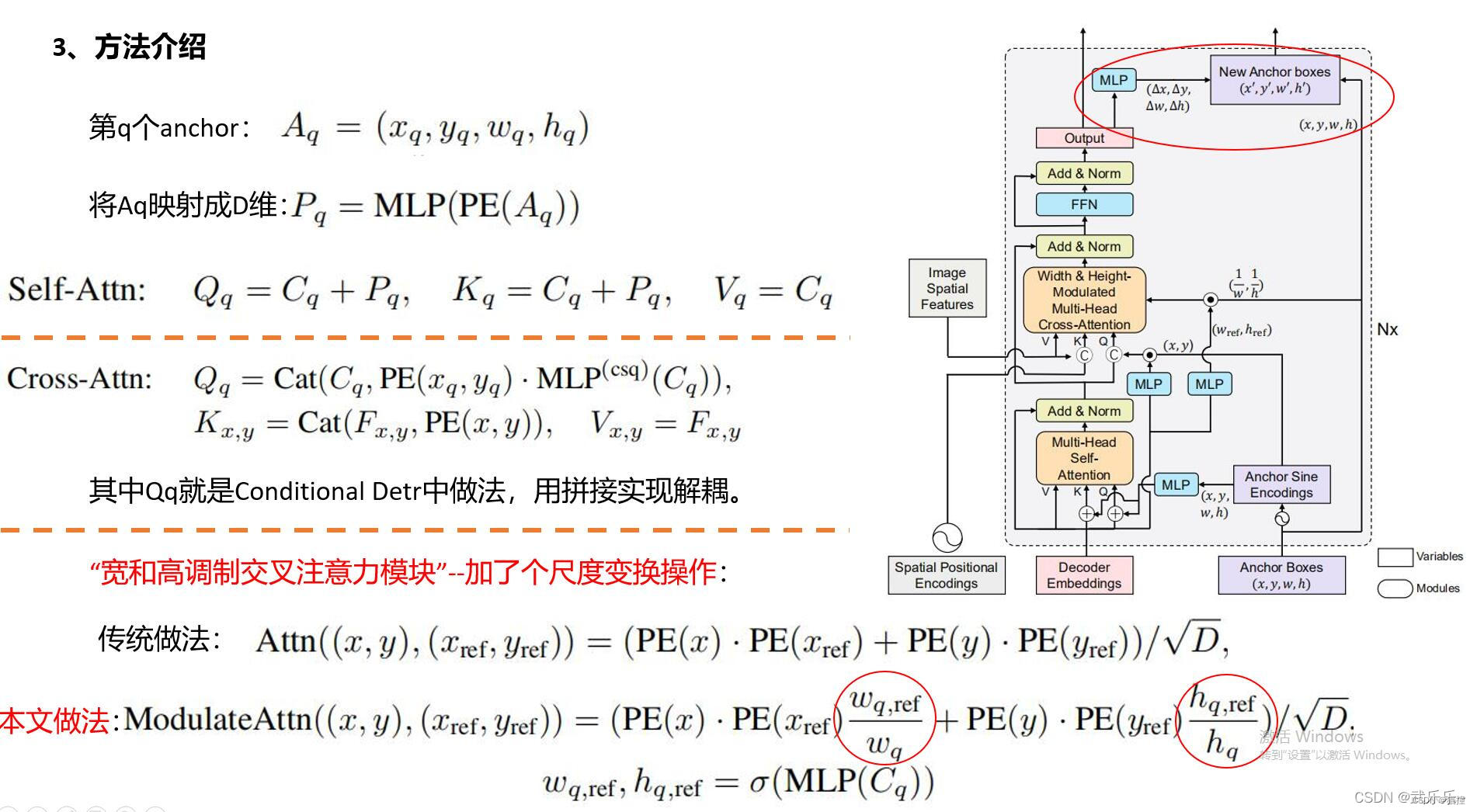
首次设定N个可学习的4维anchors,然后通过PE和MLP映射成pq.
1)self-attn:常规自注意力,cq+pq
2)cross-attn:参考点(x,y)和Conditional DETR一样, Qq=cq拼接pq;
3)宽和高调制cross-attn模块,在计算pk和pq的权重相似度时引入(1/w,1/h)的尺度变换操作
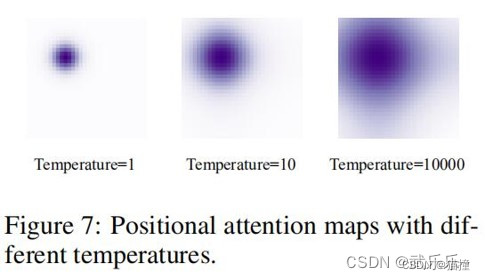
1.4 设置温度系数
Detr中给特征图每个位置生成位置Pk完全使用的是Transformer中温度系数,而Transformer针对的是单词的嵌入向量设计的,而特征图中像素值大多分布在[0,1]之间,因此,贸然采用10000不合适,所以,本文采用了20。算是个trick吧,能涨一个点左右。
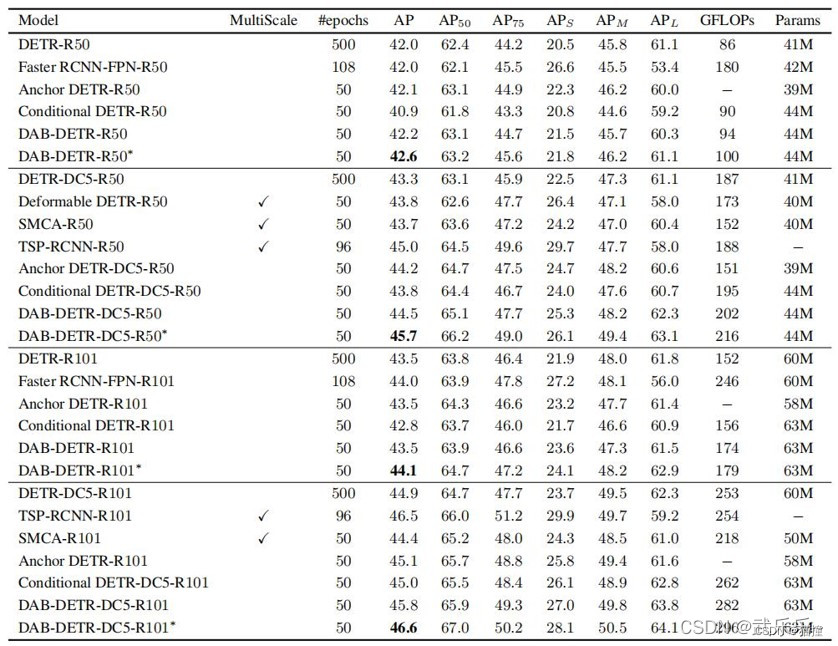
1.5 实验
比较四个不同的backbone: DETR-R50/R101; FPN-R50/R101;
二、代码讲解
2.1 decoder
整体decoder的forward函数部分:
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
refpoints_unsigmoid: Optional[Tensor] = None, # num_queries, bs, 4
):
# 第一层tgt初始化全0,output即输入的Cq!
output = tgt
# 保存中间结果
intermediate = []
reference_points = refpoints_unsigmoid.sigmoid() # [300,batch,4]
ref_points = [reference_points]
# import ipdb; ipdb.set_trace()
for layer_id, layer in enumerate(self.layers):
# 取出anchor的中心Aq
obj_center = reference_points[..., :self.query_dim] # [num_queries, batch_size, 2]
# 执行Pq = MLP(PE(obj_center)),将中心点转成256维度的嵌入向量
query_sine_embed = gen_sineembed_for_position(obj_center)
query_pos = self. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6579
6579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











