






作者 | GlobalTrack 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
导读
本文提出了一个基于注意力的框架,该框架融合了来自多个帧的时空表征,以恢复被水滴遮挡的视觉信息。并提出了一个大规模的合成数据集,该数据集具有雨天复杂驾驶场景中的模拟水滴。

论文链接:https://arxiv.org/pdf/2302.05916.pdf
源码链接:https://github.com/csqiangwen/Video_Waterdrop_Removal_in_Driving_Scenes
简介
随着视觉感知器在机器人和自动驾驶的逐渐增长的应用,这些方法的鲁棒性变得越来越重要。然而现在视觉的方法在自动驾驶天气系统中,雨天性能显著下降。原因是雨点落在挡风玻璃或相机镜头上会造成不可避免的视觉障碍。因此在自动驾驶和机器人应用中,在视频中移除雨滴变得非常重要。
已有很多研究关注于去除雨线,视频雨滴的去除收到较少的关注且仍然是一个开放问题。由于雨滴和雨线存在较大的集合差异,精心设计的去除雨线的方法不能在去除雨滴的任务上取得满意的结果。另外每一个雨滴比雨线占据更大的区域,这使得更难处理。
缺乏成对的视频雨滴去除数据集限制了基于学习方法的性能。在驾驶中采集完美对齐的有雨滴和无雨滴几乎是不可能的。本文给出了一个大规模合成视频雨滴数据集,提供成对的训练数据。
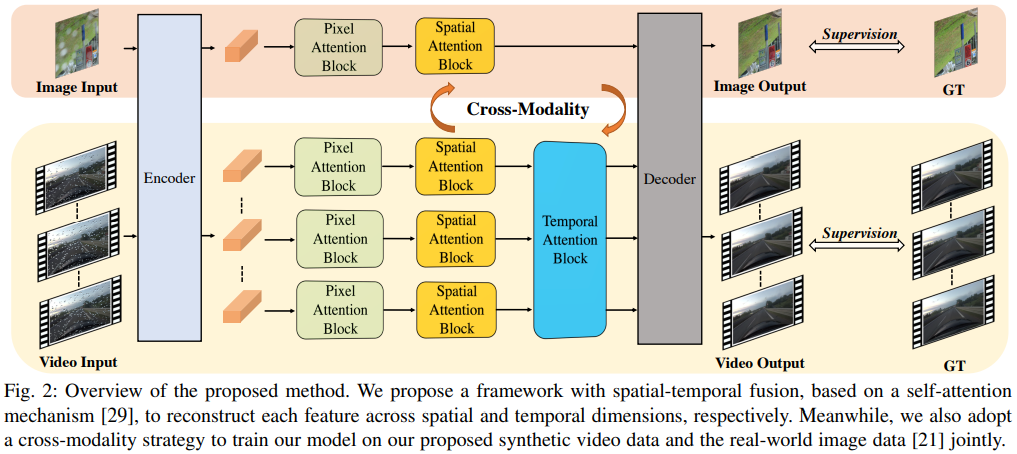
本文方法
给定一系列有雨滴的帧,目标是移除这些帧中的雨滴复原干净数据。为了完成雨滴移除,本文考虑两种模糊:部分遮挡和完全遮挡。在部分遮挡情况,仍然存在一些有意义的背景信息被雨滴覆盖。在完全遮挡情况,对于背景复原信息完全丢失。

在对特征中每个像素重新加权后,需要细化部分遮挡区域的像素,并用有意义的值填充完全遮挡区域。本文考虑使用图像修复技术处理。本文考虑使用子注意力机制细化和填充水滴退化的区域。与之前基于CNN方法不同,这些方法仅限于利用局部信息,本文利用自注意力机制在整个空间维度上通过融合全局信息恢复背景信息。本文提出一个空间注意力块细化像素注意力块中重加权特征。
尽管空间注意力块能恢复大部分区域特征,一些区域仍然质量较差,但可以通过邻近帧特征恢复。本文提出一个时间注意力块(Temporal Attention Block),用于充分利用来自附近帧的有效信息。时间注意力模块通过在时间维度上融合全局信息同时细化多个特征。
像素注意力块
给定一系列由雨滴的帧,传入编码器获得一系列特征,,且满足。编码后,每一个特征传入像素注意力模块获得对应像素级置信度图:
为了获得每个特征的像素级置信图,本文采用了与SENet相似的模块,但丢弃全局平均池化层,并用卷积层代替全连接层。
由于每个水滴在每个特征通道的空间维度上只占据一个狭窄的区域,这特点鼓励通过像素置信度图而不是普通权重重新加权每个像素。
空间时间混合
空间注意力模块
在重新加权后,需要细化部分遮挡的像素,并在完全遮挡处填充有意义的像素值。为了解决这个问题,本文利用一个子注意力机制通过将补丁与预测的注意力图融合重建每个特征。
,,分别表示查询,键和值的特征嵌入,包含核大小为的二维卷积。对于查询,键核值分别抽取块,每个块大小为。为了计算注意力图,将查询和键特征的每个补丁重塑为一维向量。对于查询和键的相似度为:
注意力图定义为:
对于每一个查询块的输出是对值块的加权融合:
时间注意力模块
在时间注意力块中,从多个输入帧特征中提取查询、键和值的多尺度补丁。对于雨滴移除任务,大的补丁给对于语义级别重建是有益的,而小的补丁鼓励纹理级别的重建。为了计算成本与复原性能的平衡,将每一个特征划分为两个大小为的部分,并抽取不同尺寸的块和。在注意力模块融合补丁后,将融合的补丁重塑为特征以接收时间上精炼的特征。
训练策略
跨模态训练策略
尽管仅在合成数据集上训练的本文模型能很好的推广到真实驾驶场景上,但在合成视频数据和真实世界图像数据联合训练可以提高推广性能。
帧序列的损失函数
掩码损失:像素注意力模块中,为了鼓励网络尽可能精确地预测像素注意力图,将预测地像素注意力图传入掩码解码器接收对于每个帧地水滴掩码。
重建损失:对于最后地干净帧重建,添加在网络输出与GT间的逐像素损失:
时间损失:为了保证网络输出的时间一致性,这里使用条件视频判别器计算网络输出的时间损失:
判别器损失函数:
整个损失函数可以描述为:
实验中加权系数设置为
合成视频数据集生成
之前只有三个图像雨滴合成的方法,且不能直接用于生成视频任务。本文的合成方法主要考虑:
对于驾驶视频,每个水滴在一系列帧中保持在相同的位置。随着风或汽车的剧烈运动,每个水滴都会有微小的移动。
随着水滴蒸发,一些完全遮挡区域在一系列帧后变成部分遮挡。
本文基于Learning from synthetic photorealistic raindrop for single image raindrop removal方法合成新的视频雨滴数据集。对于一系列干净的帧,在第一帧生成150-400个水滴。对于下一帧,每个水滴沿着随机方向偏移。同时线性放大模糊和大小,使水滴在帧上逐渐模糊,该过程可以模拟水滴的蒸发。在合成过程中,我们将每个序列的长度设置为5,移位值为1像素,模糊内核大小为3-20像素。
为了收集干净的视频数据做数据合成,本文选择巴汗51个有多场景和天气的DR(eye)VE数据集。场景包括早上,晚上,晚上,晴朗,多云,乡村,市区和高速公路。
实验
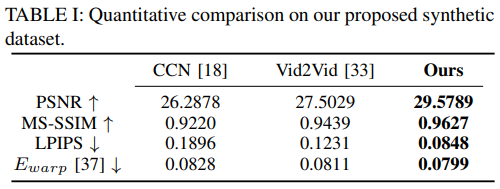
这里评估在本文合成数据集的测试事部分评估不同的视频去雨滴方法。比较的模型CCN和Vid2Vid,在本文数据集上用相同的多模态训练策略重训练。表1给出了相关实验结果。比较指标是PSNR和MS-SSIM。可以看出本文方法在合成数据集上表现出更强的性能
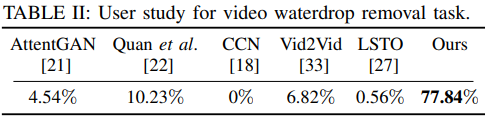
这里也给出了不同方法在真实驾驶场景下的用户研究(User Study)。每个用户给了雨滴降质的驾驶场景帧与5个比较方法和本文方法得到的结果。用户选择更好视觉质量的结果。表2给出了相关实验结果。有77.84%用户更喜欢本文方法的结果。这表明本文方法显著超越其他方法。
部分帧的可视化结果:


国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称

















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









