






作者 | 派派星 编辑 | CVHub
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群

Title: SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer
Paper: https://arxiv.org/pdf/2303.17605.pdf
导读
近年来,Transformer 架构在计算机视觉的各项任务中都表现出令人惊艳的性能。然而,相比 CNNs,该技术架构存在着大量的计算,尤其是对于高分辨率图像,一直无法在通用硬件上进行有效的部署。
基于此,本文介绍了一种名为 SparseViT 的技术,它可以减少基于窗口的视觉变换器 (vision Transformers, ViTs) 的计算复杂性。
SparseViT 通过重新考虑激活稀疏性来实现窗口激活修剪的实际加速。在这种方法下,通过对不同层分配不同的修剪比例,可以实现 50% 的延迟降低和 60% 的稀疏度。同时,SparseViT 还应用了进化搜索来有效地找到最优的层次稀疏配置。在单目 3D 目标检测、2D 实例分割和 2D 语义分割等任务中,SparseViT 相比密集的对应方法可以实现 1.5 倍、1.4 倍和 1.3 倍的加速,而且几乎没有精度损失。
创作背景
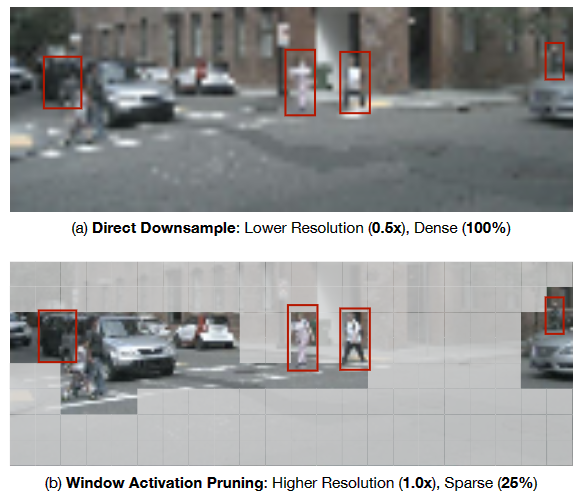
随着图像传感器的进步,高分辨率图像变得越来越容易获取,例如现在的手机可以拍摄1亿像素的照片。高分辨率图像能提供更多细节信息,使得神经网络模型能够学习到更丰富的视觉表示,从而实现更好的识别质量。但是,这也导致计算复杂度呈线性增长,使得它们在资源受限的应用程序中难以部署,例如移动视觉和自动驾驶。
对于这一问题,最简单也最常用的方法就是降低图像分辨率。 但这将使得模型丢失高分辨率传感器捕获的细节信息,尤其对于小物体检测和密集预测任务而言,这些信息的缺失将瓶颈模型的性能上限。
为此,研究人员提出了一种自然的想法,即跳过不重要区域的计算 (即激活稀疏化),以此降低计算量。 然而,激活稀疏性不能轻易转化为实际加速 CNNs 的通用硬件 (例如 GPU)。
最近,2D ViT 在不同的视觉感知任务上取得了巨大进展,例如图像分类、物体检测和语义分割。本文针对基于窗口的 ViTs 重新审视激活稀疏性,通过重新实现并在窗口级别上执行模型的 FFNs 和 LNs 等层,从而实现了大约 60% 的窗口激活稀疏性和 50% 的延迟降低。
此外,考虑到不同层对效率和准确性的影响不同,本文提出了一种非均匀的层稀疏配置,利用进化搜索探索最佳的每层稀疏率,并使用稀疏感知适应性随机地在每次迭代中修剪不同的激活。SparseViT 在单目 3D 目标检测、2D 实例分割和 2D 语义分割任务中,分别比其密集对应方法快 1.5 倍、1.4 倍和 1.3 倍,而且几乎没有精度损失。
方法

回顾 Swin Transformer
Swin Transformer 使用多头自注意力 (MHSA) 提取非重叠图像窗口内的局部特征。该模型的设计遵循标准方法,包括层归一化 (LN)、MHSA 和应用于每个窗口的前馈层 (FFN)。
原始的 Swin Transformer 实现在窗口级别 (window level) 应用在 MHSA,而 FFN 和 LN 应用于整个特征映射。这种操作不匹配需要在每个 MHSA 之前和之后进行额外的结构化处理,使得窗口修剪更加复杂,因为稀疏掩码必须从窗口级别映射到特征映射。
为了简化这个过程,本文修改了 FFN 和 LN 的执行方式,使其也是以窗口为单位。这意味着所有操作都将在窗口级别进行,使得稀疏掩码的映射非常容易。
窗口激活修剪
本文将每个窗口的重要性定义为其 L2 激活大小,不同于其他基于学习的措施,这种方法引入的计算开销较小,在实践中效果也比较好。
窗口激活修剪过程如图2所示。给定激活稀疏比例,首先收集具有最高重要性得分的窗口,然后仅对这些选定的窗口应用 MHSA、FFN 和 LN,最后将输出散回 (scatter outputs back)。为了缓解粗粒度窗口修剪导致的信息损失,我们简单地复制未选中窗口的特征。这种方法不会带来额外的计算,但在保留信息方面非常有效,这对于像目标检测和语义分割这样的密集预测任务非常关键。
与传统的权重修剪不同,重要性得分是与输入相关的,需要在推断期间计算,这可能会增加延迟。为了减少这种开销,我们在每个阶段仅计算一次窗口重要性得分,并在该阶段的所有块中重复使用,摊销开销。这还确保了阶段内窗口排序保持一致。我们使用切片简化了收集操作,这不需要任何特征复制。
混合稀疏配置搜索
为了更好地平衡模型的精度和效率,研究人员提出了在模型不同层之间应用不同的剪枝率来实现混合稀疏性。然而,手动探索每个层的稀疏性可能会很耗时且容易出错。
为了解决这个问题,研究人员提出了一种工作流程来高效地搜索最佳混合稀疏性剪枝率配置。他们设计了搜索空间,采用了稀疏感知的适应方法和基于资源限制的搜索算法来找到最佳的混合稀疏性配置。最终,通过这种方法,他们得到了一种既能保证精度,又能获得更高效率的神经网络模型。
搜索空间
对于每个 Swin 块,本文允许从 {0%,10%,...,80%} 中选择稀疏度比率。每个 Swin 块包含两个 MHSAs,一个有偏移窗口,另一个没有,它们将被赋予相同的稀疏度比率。
值得注意的是,每个阶段内的稀疏度比率是非递减的,这样可以确保剪枝后的窗口不会再次参与计算。
稀疏感知自适应
为了找到最优的混合稀疏配置,需要评估不同稀疏设置下模型的准确性。直接评估带有稀疏性的原始模型的准确性可能会产生不可靠的结果。
因此,本文提出了一种称为稀疏感知自适应 (sparsity-aware adaptation) 方法,该方法通过在每次迭代中随机采样层级激活稀疏性并相应地更新模型,以使原始模型适应带有稀疏性的情况。这样可以在不进行全面重新训练的情况下更准确地评估不同混合稀疏配置的性能。作者还指出,这种方法与 NAS 中的超网络训练不同,因为作者只是随机采样激活,而不是改变参数数量。
基于资源限制的搜索方法
先通过稀疏感知适应来准确评估模型的性能后,然后在指定的资源限制内搜索最佳的稀疏配置。
本文考虑了两种资源限制:与硬件无关的理论计算成本以及与硬件相关的测量延迟。为了进行稀疏搜索,采用了进化算法。首先,使用拒绝抽样,即重复抽样直到满足要求,从搜索空间中随机抽取 n 个网络来初始化种群,以确保每个候选者都符合指定的资源约束条件。
在每一代中,评估种群中的所有个体,并选择具有最高准确性的前 个候选者。然后通过 个突变和 个交叉生成下一代种群,使用拒绝抽样来满足硬资源限制。重复这个过程,从最后一个代中的种群中得到最佳配置。
基于最优稀疏性进行微调
针对搜索过程中得到的一系列固定稀疏度配置,使用微调算法进一步优化模型性能,直至收敛。
实验
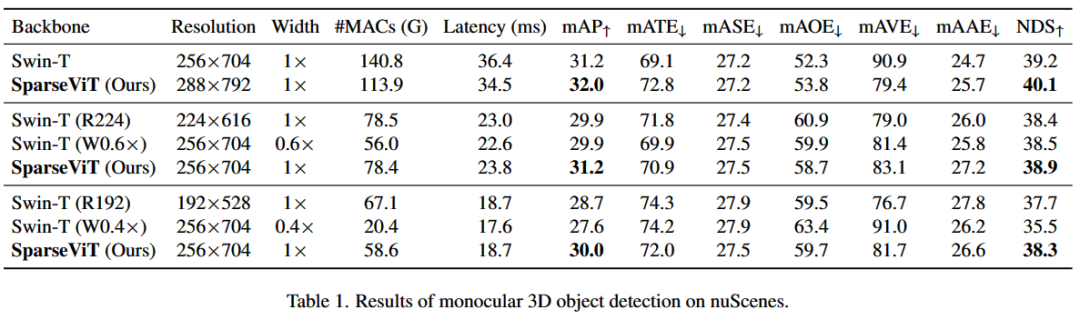
SparseViT 实现了与 Swin-T 相同的精度,#MAC 低 1.8 倍,推理延迟快 1.5 倍。
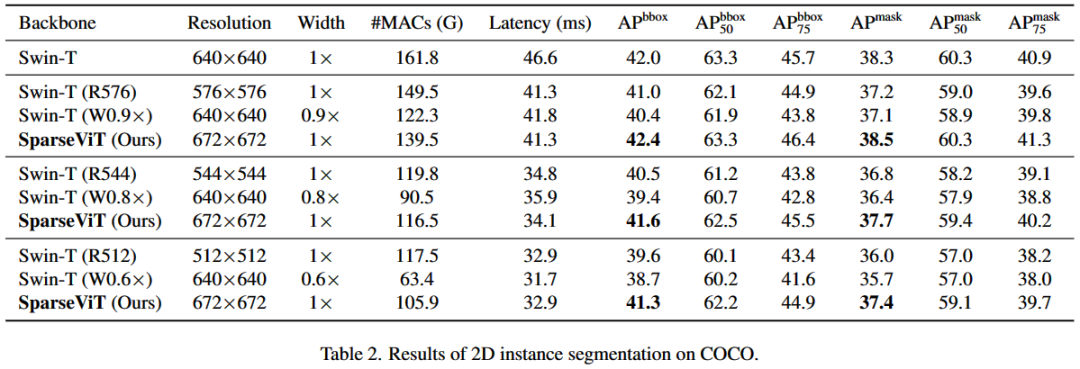
在 512×512 到 640×640 的各种输入分辨率下,SparseViT 的计算量始终优于 baseline。可以发现,从 672×672 的高分辨率开始修剪激活比直接缩小输入分辨率更有效。

parseViT 提供了比 baseline 更好的精度-效率 trade-off。

在第一行,SparseViT 自动学习了物体的轮廓,如第三和第四张图所示,其中分别勾勒出计算机和运动员的轮廓。此外,在第二行,与前景对象对应的窗口没有被修剪掉。尽管是一个小物体,但最后一张图中的行人在整个执行过程中都得到了保留,这说明了 SparseViT 的有效性。
总结
本文重新探讨了激活稀疏性在基于窗口的 ViTs 上的应用,并提出了一种新的方法来利用它。本文引入了稀疏感知自适应,并采用进化搜索来有效地找到最佳的逐层稀疏配置。结果表明,SparseViT 在单目 3D 目标检测、2D 实例分割和 2D 语义分割中实现了 1.5 倍、1.4 倍和 1.3 倍的测量加速,同时几乎不损失精度。希望本文能够激发未来研究探索使用激活剪枝来实现更高效、同时保留高分辨率信息的方法。
视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 848
848











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









