






作者 | 桓十一 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/431553418?
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【车道线检测】技术交流群
后台回复【车道线综述】获取基于检测、分割、分类、曲线拟合等近几十篇学习论文!
有个朋友准备弄车道线检测方面的项目,说是想简单了解下,不巧一直在肝项目,最近才抽出时间,就结合自己的一些项目,整理了下,学海无涯,欢迎交流。
一、概述
车道线检测,顾名思义大致任务是识别出道路两旁车道线

二、具体指标
❝
车道形状, 包括宽度、 曲率等几何参数
车辆在车道中的位置, 包括横向偏移量,车辆与道路的夹角(偏航角)
三、车道线检测主要分类
❝
实例级
非实例检测
当然对千非实例级别需要使用后处理进行聚类, 而实例级别通常是网络端到端
四、车道线检测预处理方式
❝
原图输入
俯视图输入
多视图输入
不同的预处理决定了车道线的网络构建方法,各种方法都有其对应的局限性
❝1、原图输入:常用,不需要考虑参数与转换矩阵
2、俯视图输入:会有视角损失,且融合了摄像头内外参,并不鲁棒,好处在于比较好学
3、多视图输入:研究较少,多为水论文,可用性不高
五、实现方法
基于传统方法的车道线检测
霍夫变换 Canny检测
为了防止误人子弟,在这里特别标注下,霍夫变换这种方法仅作为了解和部分操作的时候一个思路。
❝” 传统方法仅适用于特定场景下的直线或者边缘检测, 比较难鲁棒性的适用于所有场景 “
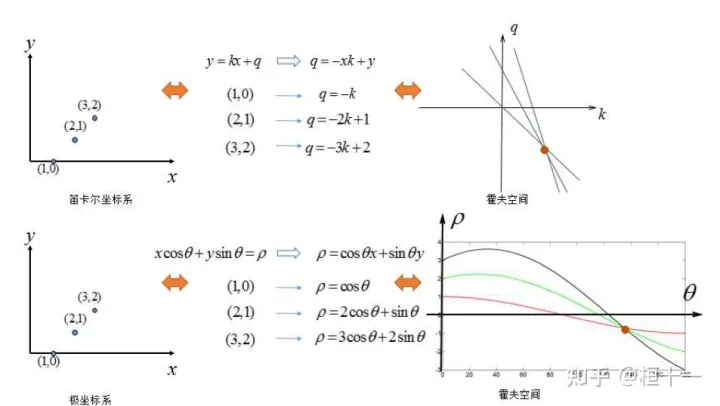
霍夫变换
总结:霍夫变换就是找相同斜率的直线, 也就是相交直线越多的点对应的斜率, 便是要找的霍夫点
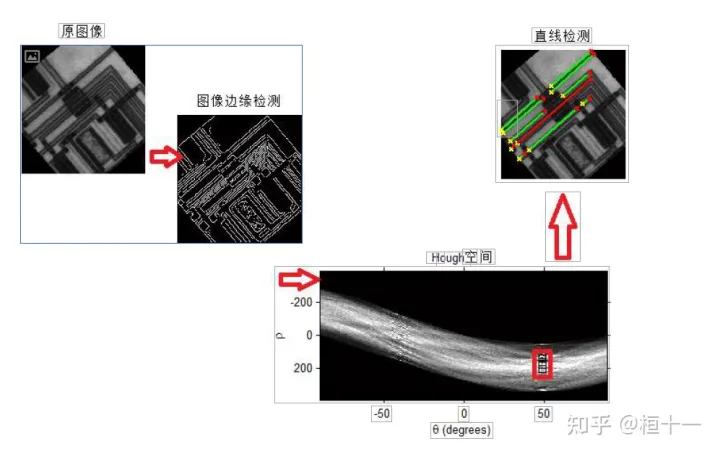
霍夫变换实例:
进行边缘检测 边缘检测后并二值化,就可以通过找非零点的坐标确定数据点 对数据点进行霍夫变换,就形成了下面那个,好像一个水管,其实是很多很多曲线组成的祸福空间 找出其中数值较大的一 些点,通常可以给定一个阈值,截取,笛卡尔坐标系对应到霍夫空间,最后得到直线检测
anchor_based 车道线检测
常见anchor_based 车道线检测如下:
❝1、UltraFastlaneDetection(名字好长,以下简称UFLD)
2、LaneATT
UltraFastlaneDetection-2020年
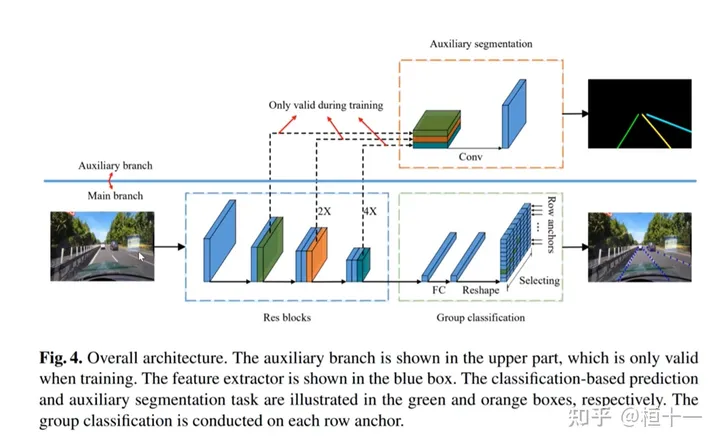
输入:原图
->featrue map
->FC
->reshape(原图大小)
->res(车道线n类)

UFLD通过对图片的垂直切片(相当于垂直anchor)判断该处anchor是否为车道线
假设我们要检测一条车道线的图像大小为 HxW,对于分割问题,我们需要处理 HxW 个分类问题。
由于我们的方案是行向选择,假设我们在 h 个行上做选择,我们只需要处理 h 个行上的分类问题,只不过每行上的分类问题是 W 维的。
因此这样就把原来 HxW 个分类问题简化为了只需要 h 个分类问题,而且由于在哪些行上进行定位是可以人为设定的,因此 h 的大小可以按需设置,但一般 h 都是远小于图像高度 H 的。
这样,我们就把分类数目从 HxW 直接缩减到了 h,并且 h 远小于 H,更不用说 h 远小于 HxW 了。
LaneATT(理论合理,这个我还没在大规模数据集测过,但是看理论来说应该是可以用的)
LaneATT是PolylaneNet方法之后的一大力作。
论文地址
https://arxiv.org/pdf/2010.12035.pdf
Github地址
https://github.com/lucastabelini/LaneATT
基于anchor的深度车道线检测模型,类似于其他通用的深度目标检测器,该模型将anchors用于特征池化步骤。由于车道线遵循规则的模式并高度相关,因此我们假设在某些情况下,全局信息对于推断其位置可能至关重要,尤其是在诸如遮挡,缺少车道标记等情况下。因此,我们提出了一种新颖的基于anchor的注意力机制,该机制聚集了全局信息。
1.在大型和复杂的数据集上,本文提出的车道检测方法比现有的最新实时方法更准确;2.具有比大多数其他模型更快的训练和推理时间的模型(达到250 FPS的速度,并且比以前精度最高的方法的MAC少近一个数量级);3.一种新颖的基于anchor的车道检测注意机制,该机制在与检测到的物体相关的其他领域可能很有用。
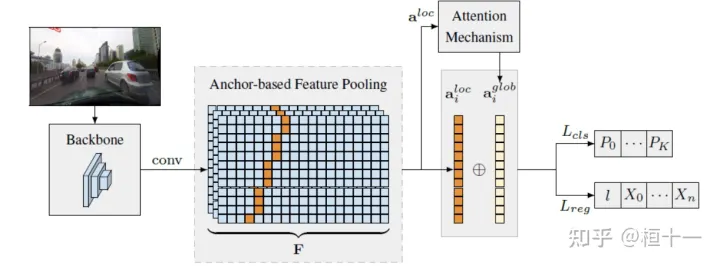
Lane的anchor表征方式与Line-CNN的方式一致。如上图所示,首先将特征图均分为一定大小的网格。然后,一条lane由起始点s和结束点e,以及方向a组成。也就是一条lane由起始点按照一定方向到结束点的所有2d坐标组成。
基于分割的车道线检测
车道线分割的难点
❝1、很难处理遮挡 比较难处理局部与全局特征
2、比较难进行实例区分
3、远处效果不好
采用分割方式的优点
❝1、非常适用于用来做定位
2、所检测车道线是绝对准确的, 不会出现由千脑补造成的误差
3、比较通用(所有线状的车道线都能可以被检测)
LaneNet + H-Net 车道线检测
2018年一篇使用分割做车道线的经典论文(最新的我就没尝试过了,这个当时是20年时候弄的,精度还行,当然,类似那种雨雪天气,路面噪声特别多的时候,一样是顶不住)
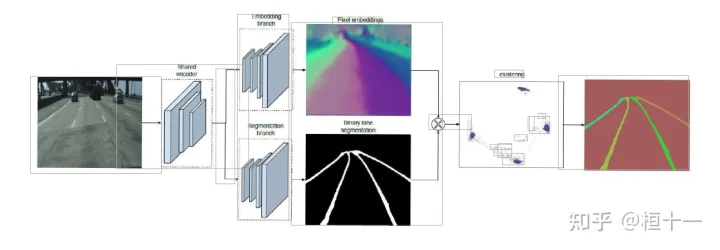
整体架构
Lanenet包含了使用分割做车道线检测的整体架构
lane net实际上将实例分割转换成了语义分割和聚类,如示意图所示:
下面的分支(这个图是我截的,有点不清楚,注释那里写着 Segmentation branch ),顾名思义是语义分割的部分,用于 分割 车道线 和 背景;
上面的分支 (Embedding branch)用于 像素的矢量化,把每个 像素 用一个高维向量表示(类似于 word embedding),使得 像素 可以通过 聚类 把 不同车道线分开(示意为图里面那些五彩斑斓的区域);
损失函数
lane net语义分割损失函数为softmax-crossentropy、
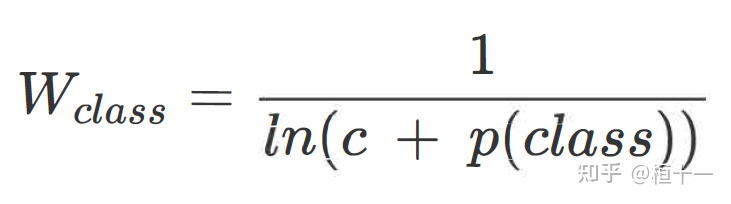
(引入基于样本占比的权重,和样本成反比,数量越多,占比越小,来解决样本不均衡)
embedding的loss设计
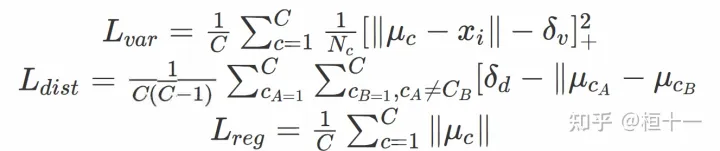
其中, C是车道线数量, Ne是属同—条车道线的像素点数量, μc是车道线的均值向
量, xi 是像素向量(pixel embedding), [x]+=max(O,x) 。注意这里先执行加法操作, 再执行平方操作
后处理:聚类
注意,聚类可以看做是个后处理,上 一步embedding_branch已经为聚类提供好的特征向量了,利用这些特征向量我们可以利用任意聚类算法来完成实例分割的目标。为了方便聚类,论文中设定od>6ov。在进行聚类时,首先使用mean shift聚类(均值偏移),使得簇中心沿着密度上升的方向移动,防止将离群点选入相同的簇中;之后对像素向量进行划分:以簇中心为圆心,以2ov为半径,选取圆中所有的像素归为同一车道线。
“ 重复该步骤, 直到将所有的车道线像素分配给对应的车道。”
mean-shift聚类
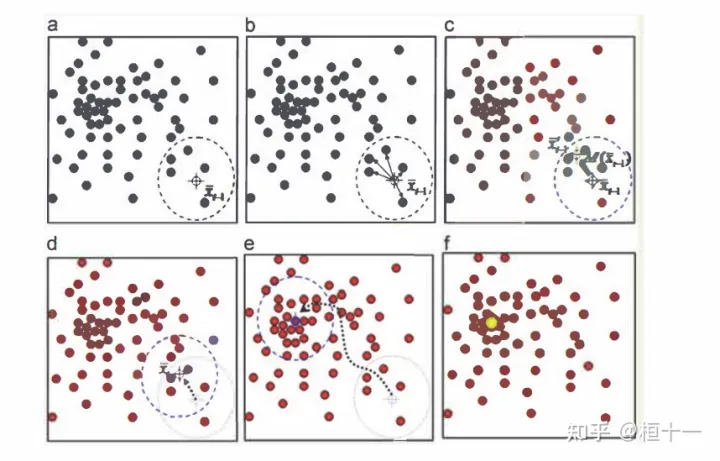
mean-shift聚类算法:O半径为r, 不断地以圆中密度最大的位置作为圆心, 寻找到聚类的中心点
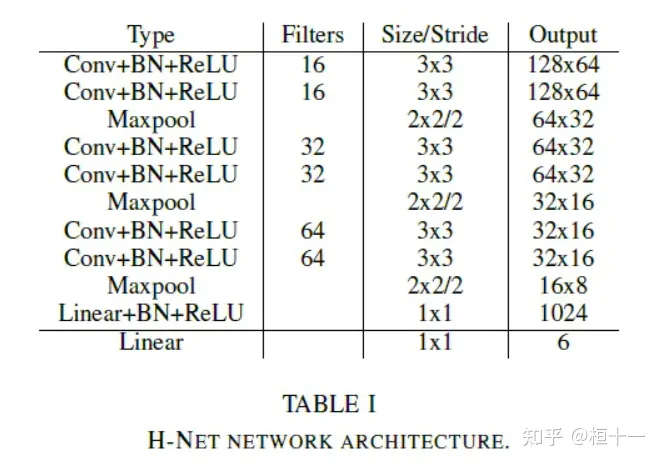
Hne t对车道线进行拟合
如下图所示,对于同一张输入图片,LaneNet输出实例分割的结果,为每个车道线像素分配一个车道线ID,H-Net输出一个转换矩阵H,使用转换矩阵H对车道线像素进行修正,并对修正的结果拟合出一个三阶的多项式作为预测得到的车道线。
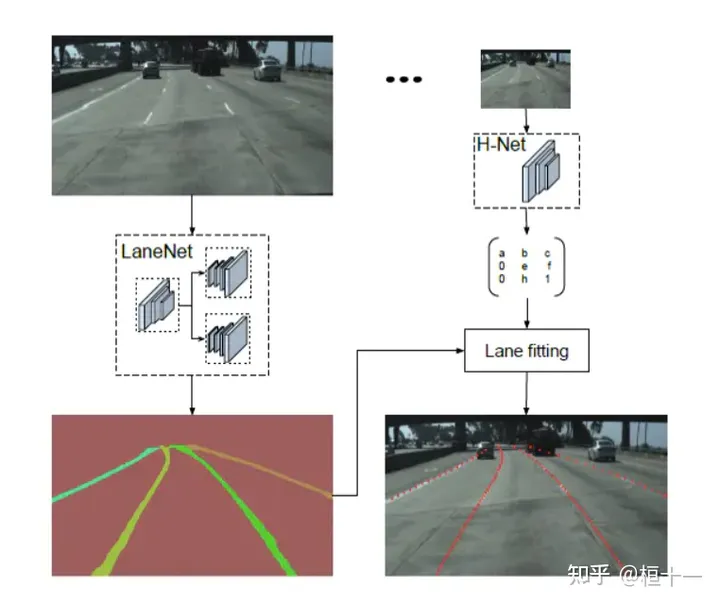
H-net解决的问题
传统是通过图像内参实现,内参不会考虑不同路面的清况,具体来说就是,传统的做法是将图片投影到鸟瞰图中(这部分一般用应变性矩阵投射,opencv里面有),然后使用2阶或者3阶多项式进行拟合。在这种方法中,转换矩阵H只被计算一次,所有的图片使用的是相同的转换矩阵,这会导致地平面(山地,丘陵)变化下的误差。但是H-net是一个可以进行参数更新的卷积网络,可以根据图片来更新转换矩阵H
(一)视频课程来了!
自动驾驶之心为大家汇集了毫米波雷达视觉融合、高精地图、BEV感知、传感器标定、传感器部署、自动驾驶协同感知、语义分割、自动驾驶仿真、L4感知、决策规划、轨迹预测等多个方向学习视频,欢迎大家自取(扫码进入学习)

(扫码学习最新视频)
视频官网:www.zdjszx.com
(二)国内首个自动驾驶学习社区
近1000人的交流社区,和20+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、Occpuancy、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

(三)【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称















 6235
6235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









