



作者 | 耳东君 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/623794029
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【模型部署】技术交流群
后台回复【模型部署工程】获取基于TensorRT的分类、检测任务的部署源码!
0x1 前言:
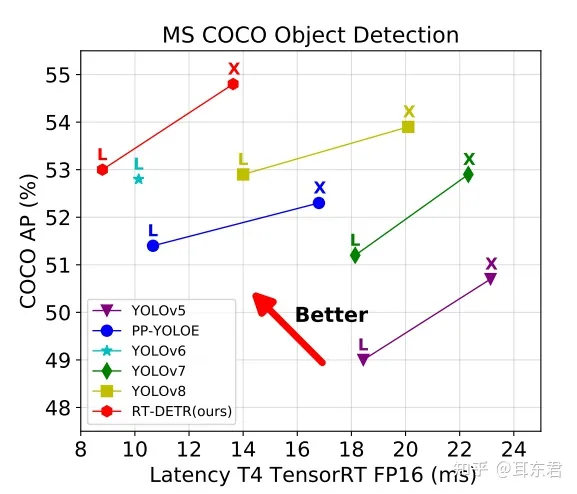
前段时间刚看过DINO Transformer,这没两天就出了RT-DETR,还是DINO的升级进化版,不仅感叹,确实很卷啊。去年,各大YOLO模型纷纷亮相,各自展现出强大的检测能力,但是时隔不久,RT-DETR模型发布了,号称其精度和速度都超越了所有的YOLO模型,那么真的是这样吗?下面从tensorrt部署推理实际进行测速。
RT-DETR论文:
arxiv.org/pdf/2304.08069.pdf
RT-DETR代码:
github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/rtdetr
RT-DETR的对比指标:
在部署前,先列出一些必要的信息:
# 1. tensorrt环境准备,请自行安装,选择版本大于或等于trt-v8.5.1
tensorrt版本选择v8.6.0.xx # 因为RT-DETR里有GridSample算子,这个在trt-v8.5.1版本之后进行了支持
# 2. 选择带有cuda的服务器,常用的带有显卡的x86服务器,或者Jetson系列的arm板子等
RTX3090 # 作者测试服务器所使用的显卡
# 3. 训练自己的rt-detr模型并导出,不熟悉paddleDetection框架的,也没关系,只需要按照官方README操作即可
# 这里给出官方的模型 https://bj.bcebos.com/v1/paddledet/models/rtdetr_r50vd_6x_coco.pdparams
# 4. 测试一下自己的paddledetection环境是否正确,运行下面的命令,不报错即可
python tools/infer.py \
-c configs/rtdetr/rtdetr_r50vd_6x_coco.yml \
-o weights=weights/rtdetr_r50vd_6x_coco.pdparams \ # 改成你自己的模型
--infer_img=scripts/dog.jpg # 改成你自己的文件
# 5. 一般而言rt-detr默认是导出前后处理的,这会使得导出的onnx会有多个输入,影响部署,所以要关闭前后处理的导出
# 5.1 修改 configs/rtdetr/_base_/rtdetr_r50vd.yml中的DETR类
DETR:
backbone: ResNet
neck: HybridEncoder
transformer: RTDETRTransformer
detr_head: DINOHead
post_process: DETRPostProcess
exclude_post_process: True # 增加该行,并将其改为True
# 6. 【可选】我在使用cuda后处理的过程中,发现onnx导出的是两个分支[box,class],这对部署并不友好。
# 而且,box.shape=[batch,300,4] class.shape=[batch,300,80],其实是可以这两个输出合并的
# 修改ppdet/modeling/architectures/detr.py的DETR类中的_forward方法
# 将return output修改为:
import paddle.nn.functional as F # 直接输出class为[0,1],这样就不需要再对score进行后处理了
return paddle.concat([bbox,F.sigmoid(bbox_num)],axis=-1) # 这样,就能保证是一个输出,且output.shape=[batch,300,84]静态onnx导出和trt转换(不推荐)
# 1. 按照paddledetection里提供的rtdetr的README.md,按照其步骤导出onnx
# 2. 导出的onnx先不要转trt engine,可以使用onnxsim对onnx模型进行简化去除一些不必要的op算子
pip install onnxsim # 安装onnxsim库,可以直接将复杂的onnx转为简单的onnx模型,且不改变其推理精度
onnxsim input_onnx_model output_onnx_model # 通过该命令得到RT-DERT的rtdetr_r50vd_6x_coco_sim.onnx
# 3. 导出静态engine模型,该模型只支持输入固定图片尺寸[1,3,640,640]
trtexec --onnx=./rtdetr_r50vd_6x_coco_sim.onnx \
--workspace=4096 \
--shapes=image:1x3x640x640 \
--saveEngine=rtdetr_r50vd_6x_coco_static_fp16.trt \
--avgRuns=100 \
--fp16动态onnx导出和trt转换(强烈推荐)
动态onnx输入的导出和静态的不同,这里给出paddledetection的导出步骤,这里给出动态batch的导出,如果你想导出动态height或者动态width,步骤同下:
# 1. 根据训练得到的rtdetr_r50vd_6x_coco.pdparams导出model.pdmodel和model.pdiparams
# 该步骤和静态onnx导出步骤一致
python tools/export_model.py \
-c configs/rtdetr/rtdetr_r50vd_6x_coco.yml \
-o weights=weights/rtdetr_r50vd_6x_coco.pdparams \
trt=True \
--output_dir=output_inference
# 2. 修改model.pdmodel和model.pdiparams来支持动态shape的onnx导出
# paddle_infer_shape.py下载位置:https://github.com/jiangjiajun/PaddleUtils/tree/main/paddle
python scripts/paddle_infer_shape.py \
--model_dir=./output_inference/rtdetr_r50vd_6x_coco/ \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--save_dir new_model \
--input_shape_dict="{'image':[-1,3,640,640]}" # 如果宽高也想动态,将其用-1代替
# 3. 使用paddle2onnx将其转为onnx,这个和静态onnx导出方式一致
paddle2onnx --model_dir=./new_model \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 16 \
--save_file ./new_model/rtdetr_r50vd_6x_coco.onnx
# 4.对导出的onnx进行优化,类似onnxsim,但可以设置输入是动态的shape
python -m paddle2onnx.optimize --input_model ./new_model/rtdetr_r50vd_6x_coco.onnx \
--output_model ./new_model/rtdetr_r50vd_6x_coco_dynamic.onnx \
--input_shape_dict "{'image':[-1,3,640,640]}" # 如果宽高也想动态,将其用-1代替
# 5. 导出动态shape的engine模型,用于后续推理
trtexec --onnx=new_model/rtdetr_r50vd_6x_coco_dynamic.onnx \
--workspace=4098 \
--minShapes=image:1x3x640x640 \
--maxShapes=image:16x3x640x640 \
--optShapes=image:4x3x640x640 \
--saveEngine=new_model/rtdetr_r50vd_6x_coco_dynamic_fp16.trt \
--avgRuns=100 \
--fp16通过上面步骤可以得到一个能直接推理的trt文件,通过该文件我们就可以进行trt模型推理了。注意tensorrt生成engine的过程中依赖你的硬件,如果你在x86服务器上生成,要运行在arm平台上,是运行不成功的,所以,需要当前机生成engine文件且只能在当前机运行。
Ox2 TensorRT的模型推理和测速
在工业上,模型推理都是使用c++进行推理,模型的前后处理(resize/decoder/nms)等都是使用cuda进行加速,这里会测试三种版本的trt推理,分别计算其耗时,分别是:Python版,c++版、c++ cuda版(前后处理cuda加速),请按需选择部署:
在写推理之前,我们先看一下RT-DETR的前后处理,yml文件位置:configs/rtdetr/base/rtdetr_reader.yml
TestReader:
inputs_def:
image_shape: [3, 640, 640] # 这个是输入的尺寸
sample_transforms:
- Decode: {} # 这是paddledetection的类,表明输入是rgb格式
- Resize: {target_size: [640, 640], keep_ratio: False, interp: 2} # 直接resize
- NormalizeImage: {mean: [0., 0., 0.], std: [1., 1., 1.], norm_type: none}# 均值方差都为0,但需要除以255
- Permute: {} # 通道由[h,w,c]转为[c,h,w]
batch_size: 1
shuffle: false
drop_last: falsePython版本trt推理
由于,RT-DERT的推理是在太简洁了,这里直接放代码,方便直接阅读,不得不说,RT-DERT确实容易部署,对目标检测又是一突出贡献。
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2
import math
import random
random.seed(3)
CLASS_COLORS = [[random.randint(0, 255) for _ in range(3)] for _ in range(80)]
CLASS_NAMES = ('person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant',
'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog',
'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe',
'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat',
'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot',
'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell phone', 'microwave',
'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush')
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
def alloc_buf_N(engine,data):
"""Allocates all host/device in/out buffers required for an engine."""
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
data_type = []
for binding in engine:
if engine.binding_is_input(binding):
size = data.shape[0]*data.shape[1]*data.shape[2]*data.shape[3]
dtype = trt.nptype(engine.get_binding_dtype(binding))
data_type.append(dtype)
# Allocate memory on the host
host_mem = cuda.pagelocked_empty(size, dtype)
# Allocate memory on the device
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
size = trt.volume(engine.get_binding_shape(binding)[1:]) * engine.max_batch_size
host_mem = cuda.pagelocked_empty(size, data_type[0])
device_mem = cuda.mem_alloc(host_mem.nbytes)
bindings.append(int(device_mem))
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
def do_inference_v2(context, inputs, bindings, outputs, stream, data):
"""
Inputs and outputs are expected to be lists of HostDeviceMem objects.
"""
for inp in inputs:
cuda.memcpy_htod_async(inp.device, inp.host, stream)
context.set_binding_shape(0, data.shape)
# Run inference.
context.execute_async(batch_size=1, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
for out in outputs:
cuda.memcpy_dtoh_async(out.host, out.device, stream)
# Writes the contents of the system buffers back to disk to ensure data synchronization.
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
trt_logger = trt.Logger(trt.Logger.INFO)
def load_engine(engine_path):
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def bbox_cxcywh_to_xyxy(x):
bbox = np.zeros_like(x)
bbox[...,:2] = x[...,:2] - 0.5 * x[...,2:]
bbox[...,2:] = x[...,:2] + 0.5 * x[...,2:]
return bbox
if __name__ == '__main__':
class_num = 80
keep_boxes = 300
conf_thres = 0.45
# 图片的预处理
image = cv2.imread("scripts/dog.jpg")
image_h, image_w = image.shape[:2]
ratio_h = 640 / image_h
ratio_w = 640 / image_w
img = cv2.resize(image, (0, 0), fx=ratio_w, fy=ratio_h, interpolation=2)
img = img[:, :, ::-1] / 255.0
img = img.transpose(2, 0, 1)
img = np.ascontiguousarray(img[np.newaxis], dtype=np.float32)
engine = load_engine("new_model/rtdetr_r50vd_6x_coco_dynamic_fp16.trt")
context = engine.create_execution_context()
inputs_alloc_buf, outputs_alloc_buf, bindings_alloc_buf, stream_alloc_buf = alloc_buf_N(engine,img)
inputs_alloc_buf[0].host = img.reshape(-1)
net_output = do_inference_v2(context, inputs_alloc_buf, bindings_alloc_buf, outputs_alloc_buf,stream_alloc_buf, img)
net_output = net_output[0].reshape(keep_boxes,-1)
boxes = net_output[:,:4]
scores = net_output[:,4:]
# 模型后处理
boxes = bbox_cxcywh_to_xyxy(boxes)
_max = scores.max(-1)
_mask = _max > conf_thres
boxes, scores = boxes[_mask], scores[_mask]
boxes = boxes * np.array([640, 640, 640, 640], dtype=np.float32)
labels = scores.argmax(-1)
scores = scores.max(-1)
for box, score, label in zip(boxes, scores, labels):
x1, y1, x2, y2 = box
x1 = math.floor(min(max(1, x1 / ratio_w), image_w - 1))
y1 = math.floor(min(max(1, y1 / ratio_h), image_h - 1))
x2 = math.ceil(min(max(1, x2 / ratio_w), image_w - 1))
y2 = math.ceil(min(max(1, y2 / ratio_h), image_h - 1))
cv2.rectangle(image, (x1, y1), (x2, y2), CLASS_COLORS[label], 2)
cv2.putText(image, f'{CLASS_NAMES[label]} : {score:.2f}',
(x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6,
(0, 0, 255), 1)
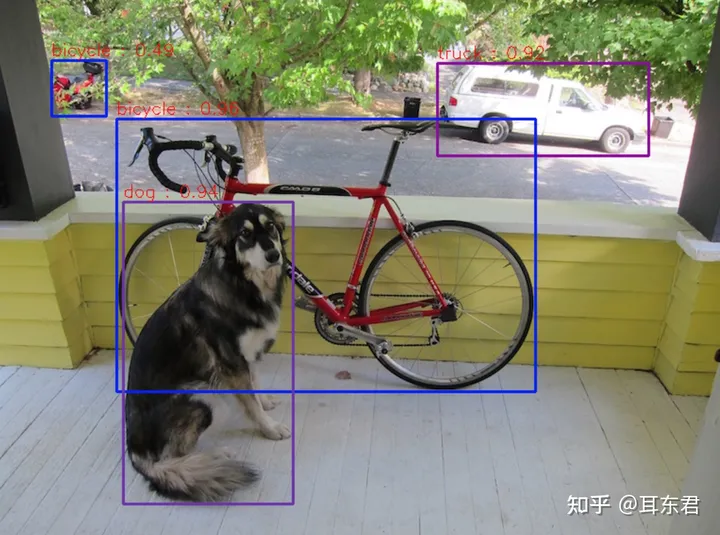
cv2.imwrite("res.png",image)检测效果图如下:
C++版本trt推理
由于c++版本需要写一些cuda代码,代码较多,这里直接给出我写的tensorrt推理项目,里面支持yolo系列的cpp/cuda版推理,后续考虑支持openvino、mnn、ncnn等backend的c++&cuda推理。RT-DETR的推理代码已经发布,可以直接使用,欢迎start。
github.com/AiQuantPro/AiInfer.git
cuda版的RT-DETR的tensorrt推理代码位于:application/rtdetr_det_app目录下,直接运行即可。
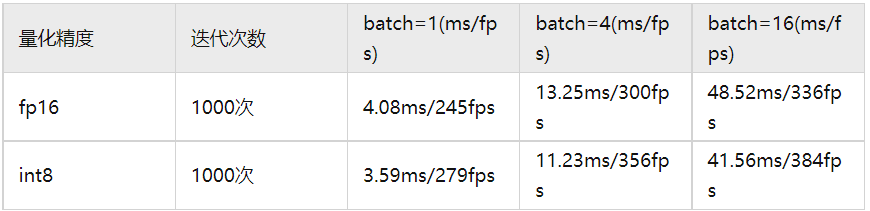
推理测速:本次测试模型是RT-DETR-R50模型,测试显卡类型是RTX-3090,前后处理都是使用cuda加速。经过测试发现,batch越大fps越高,所以建议使用多batch输入。batch>1的ms是指推理batch张的耗时。
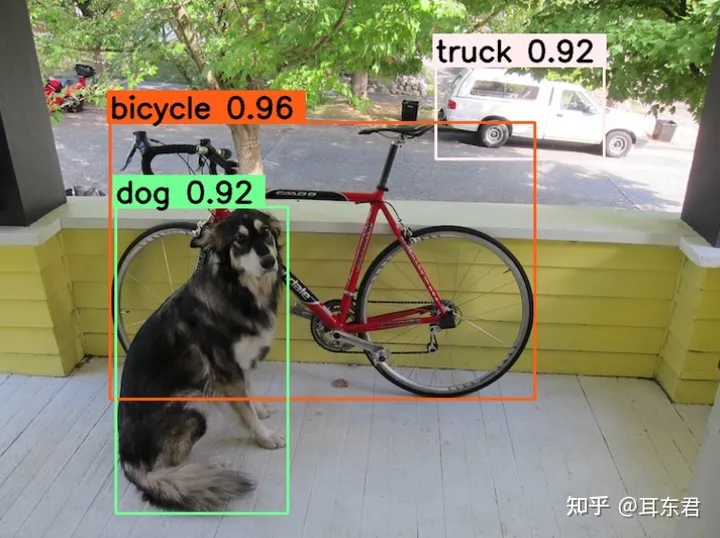
检测效果图如下(cuda版):
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码免费学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、Occupancy、多传感器融合、大模型、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)


















 2240
2240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









