






特别说明:参考官方开源的DETR代码、TensorRT官方文档,如有侵权告知删,谢谢。
模型、测试图像、转换tensorrt(tensorRT-7.2.3.4)代码、测试tensorrt代码,放在github上参考链接 模型和代码。
用C++部署的同学看过来:C++部署参考。
说明:
(1)本示例提供的模型只检测行人,由于训练的时类别写成了3,因此模型输出结果只有第二类说有效的。
(2)本示例不涉及模型训练,训练自己数据可以参考网上教程。我第一次训练没有使用预训练权重,导致模型不收敛最终的AP全为0;第二次加载预训练模型(detr-r50)才收敛,加载预训练权重参考网上提供的将模型输出适配成自己的类别。
(3)解决转tensorrt 输出全为 0 的问题。
转 tensorrt 可能会遇到的问题:
(1)导出onnx后转tensorrt 加载不了,建议用onnxsim处理一下。
(2)导出的tensorrt推理输出全为0,这个问题让我费解很久,怀疑过模型输入有问题、网上查到也有遇到这个问题的但没有给出解决方案,几度曾想过放弃,念念不忘总有回响,又经过不断尝试总算是能输出正确结果。
解决tensorrt 推理输出全为0
第一步:修改onnx模型输出层Gather的参数(在网上看到的修改方法):
graph = gs.import_onnx(onnx.load("./detr_r50_person_sim.onnx"))
for node in graph.nodes:
# print(node)
if node.name == "Gather_2711":
print(node)
print(node.inputs[1])
node.inputs[1].values = np.int64(5)
print(node.inputs[1])
if node.name == "Gather_2713":
print(node)
print(node.inputs[1])
node.inputs[1].values = np.int64(5)
print(node.inputs[1])
onnx.save(gs.export_onnx(graph), 'detr_r50_person_sim_change.onnx')
按照上述修改输出结果还全是0,这下让人崩溃了,无数次想要放弃。
第二步:使用 fp32_mode 模式
在第一步基础上,转 tensorrt 不使用任何量化,代码里tensorrt 默认量化是 fp16_mode,将量化方式注释掉输出结果正常。尝试过不用第一步修改Gather,直接不用量化转tensor结果不对,因此第一步也是必要的。
def get_engine(onnx_model_name, trt_model_name):
explicit_batch = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
with trt.Builder(G_LOGGER) as builder, builder.create_network(explicit_batch) as network, trt.OnnxParser(network,
G_LOGGER) as parser:
builder.max_batch_size = batch_size
builder.max_workspace_size = 2 << 30
print('Loading ONNX file from path {}...'.format(onnx_model_name))
with open(onnx_model_name, 'rb') as model:
print('Beginning ONNX file parsing')
if not parser.parse(model.read()):
for error in range(parser.num_errors):
print(parser.get_error(error))
print('Completed parsing of ONNX file')
print('Building an engine from file {}; this may take a while...'.format(onnx_model_name))
####
# builder.int8_mode = True
# builder.int8_calibrator = calib
# builder.fp16_mode = True
####
print("num layers:", network.num_layers)
# last_layer = network.get_layer(network.num_layers - 1)
# if not last_layer.get_output(0):
# network.mark_output(network.get_layer(network.num_layers - 1).get_output(0))//有的模型需要,有的模型在转onnx的之后已经指定了,就不需要这行
network.get_input(0).shape = [batch_size, 3, imput_h, imput_w]
engine = builder.build_cuda_engine(network)
print("engine:", engine)
print("Completed creating Engine")
with open(trt_model_name, "wb") as f:
f.write(engine.serialize())
return engine
经过以上两步修改,结果总算是正常了。
onnx结果
tensorRT 结果

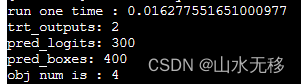
tensorRT 时耗
由于使用fp16_mode量化模型输出全为0,以下时耗测试使用的float32.
解决该问题的终极方法
请参考: 【DETR tensor去除推理过程无用辅助头+fp16部署再次加速+解决转tensorrt 输出全为0问题的新方法】
















 2297
2297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









