






作者 | 苹果姐 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/641428362
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【模型部署】技术交流群
本文只做学术分享,如有侵权,联系删文
相信除了少数自研芯片的大厂,绝大多数自动驾驶公司都会使用英伟达NVIDIA芯片,那就离不开TensorRT. TensorRT是在NVIDIA各种GPU硬件平台下运行的一个C++推理框架。我们利用Pytorch、TF或者其他框架训练好的模型,可以首先转化为onnx格式,再转化为TensorRT的格式,然后利用TensorRT推理引擎去运行我们这个模型,从而提升这个模型在英伟达GPU上运行的速度。
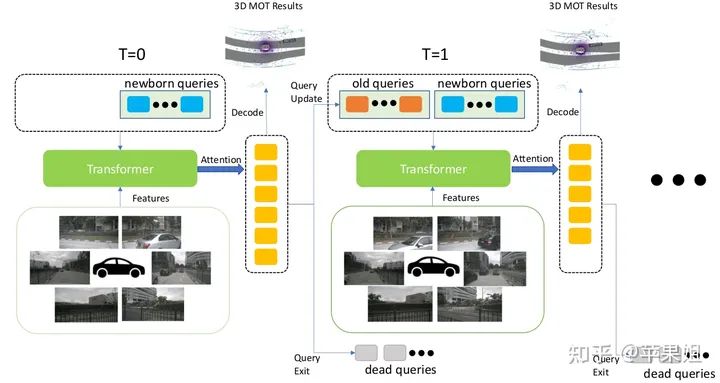
一般来说,onnx和TensorRT仅支持相对比较固定的模型(包括各级的输入输出格式固定,单分支等),最多支持最外层动态输入(导出onnx可以通过设置dynamic_axes参数确定允许动态变化的维度).但活跃在感知算法前沿的小伙伴们都会知道,目前一个重要发展趋势就是端到端(End-2-End),可能涵盖了目标检测,目标跟踪,轨迹预测,决策规划等全部自动驾驶环节,而且必定是前后帧紧密相关的时序模型.实现了目标检测和目标跟踪端到端的MUTR3D模型可以作为一个典型例子(模型介绍可参考:)
实现真正的端到端多目标跟踪(MOT) --MOTR/MUTR3D中的Label Assignment机制理论和实例详解
https://zhuanlan.zhihu.com/p/609123786
这种模型相当于将原来需要大量后处理和帧间关联的步骤全部放到了模型网络里,势必带来一系列的动态元素,如多if-else分支,子网络输入shape动态变化,和其他一些需要动态处理的操作和算子等.这种情况下还能成功转换为TensorRT格式并实现精度对齐,甚至fp16的精度对齐吗?
因为整个过程涉及多个细节,情况各不一样,纵观全网的参考资料,甚至google搜索,也很难找到即插即用的方案,只能通过不断拆分和实验来逐个解决.通过博主一个多月的艰苦探索实践(之前对TensorRT的经验不多,没有摸清它的脾气),动了不少脑筋,也踩了不少坑,最后终于成功转换并实现fp32/fp16精度对齐,且时延相比单纯的目标检测增加非常小。想在此做一个简单的整理,并为大家提供参考(没错,一直写综述,终于写实践了!)
1.数据格式问题
首先是MUTR3D的数据格式比较特殊,都是采用实例形式,这是因为每个query绑定的信息比较多,都打包成实例更容易一对一的存取.但对于部署而言,输入输出只能是tensor,所以首先要对实例数据进行拆解,变成多个tensor变量.并且由于当前帧的query和其他变量是在模型中生成,所以只要输入前序帧保留的query和其他变量即可,在模型中对二者进行拼接.
2.padding解决输入动态shape的问题
对于输入的前序帧query和其他变量,有一个重要问题是shape是不确定的,这是因为MUTR3D仅保留前序帧中曾经检出过目标的query.这个问题还是比较容易解决的,最简单的办法就是padding,即padding到一个固定大小,对于query可以用全0做padding,数量具体多少合适,可以根据自己的数据做实验确定,太少容易漏掉目标,太多比较浪费空间.虽然onnx的dynamic_axes参数可以实现动态输入,但因为涉及到后续transformer计算的size,应该是有问题的,我没有尝试,读者可以试验一下.
3.padding对于主transformer中self-attention模块的影响
如果没有使用特殊算子的话,经过padding以后就可以成功转换onnx和tensorrt了.实际上肯定是有的,但不在本篇的讨论范围,例如MUTR3D中在帧间移动reference points时用到求伪逆矩阵的torch.linalg.inv算子就不支持.如果遇到算子不支持的情况只能先尝试替换,不行就只能在模型外使用,老司机的话还可以自己写算子.但因为这一步可以放在模型的预处理和后处理,我还是选择把这一步拿到模型外了,自己写算子难度较大.
但是成功转换了就万事大吉了吗,答案一定是NO,会发现精度差距很大.因为模型的模块很多,我们先说第一个原因.我们知道在transformer的self-attention阶段,会做多个query之间的信息交互.而原模型的前序帧只保留了曾经检测出目标的query(模型中称为active query),应该只有这些query与当前帧的query进行交互.而现在因为padding了很多无效query,如果所有query一起交互,势必会影响结果.
解决这个问题受了DN-DETR[1]的启发,那就是使用attention_mask,在nn.MultiheadAttention中对应'attn_mask'参数,作用就是屏蔽掉不需要进行信息交互的query,最初是因为在NLP中每个句子长度不一致而设置的,正好符合我现在的需求,只是需要注意True代表需要屏蔽的query,False代表有效query.
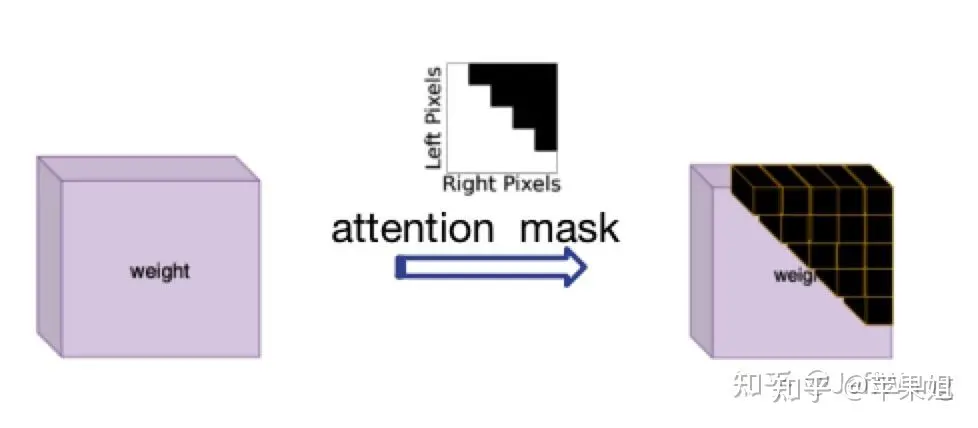
因为计算attention_mask逻辑稍微有点复杂,很多操作转换TensorRT可能出现新问题,所以也应该在模型外计算好之后作为一个输入变量输入模型,再传递给transformer.以下是示例代码:
data['attn_masks'] = attn_masks_init.clone().to(device)
data['attn_masks'][active_prev_num:max_num, :] = True
data['attn_masks'][:, active_prev_num:max_num] = True[1]DN-DETR: Accelerate DETR Training by Introducing Query DeNoising
4.padding对于QIM的影响
QIM是MUTR3D中对transformer输出的query进行的后处理模块,主要分三步,第一步是筛选active query,即在当前帧中检测出目标的query,依据是obj_idxs是否>=0(在训练阶段还包括随机drop query,和随机加入fp query,推理阶段不涉及),第二步是update query,即针对第一步中筛选的query做一个更新,包括query 输出值的self-attention,ffn,和与query输入值的shortcut连接,第三步是将更新的query与重新生成的初始query拼接,作为下一帧的输入.可见第二步中仍然存在我们在第3点中提到的问题,即self-attention不做全部query之间的交互,而是只进行active query之间的信息交互.所以在这里又要使用attention mask.
虽然QIM模块是可选的,但实验表明对模型精度的提升是有帮助的.如果要使用QIM的话,这个attention mask必须在模型里计算,因为模型外部无法得知当前帧的检测结果.由于tensorRT的语法限制,很多操作要么会转换不成功,要么不会得到想要的结果,经过多次实验,结论是直接用索引切片赋值(类似于第3点的示例代码)操作一般不支持,最好用矩阵计算的方式,但涉及计算必须将attention mask的bool类型转为float类型,最后attention mask需要转回bool类型才能使用.以下是实例代码:
obj_mask = (obj_idxs >= 0).float()
attn_mask = torch.matmul(obj_mask.unsqueeze(-1), obj_mask.unsqueeze(0)).bool()
attn_mask = ~attn_mask5.padding对于输出结果的影响
进行完以上四点,我们基本可以保证模型转换tensorRT的逻辑没有问题,但输出结果经过多次验证后某些帧仍然存在问题一度让我很不解.但一帧帧从数据上分析,就会发现竟然在某些帧padding的query虽然没有参与transformer计算,却可以得到一个较高的score,进而得到错误的结果.这种情况在数据量大的情况下确实是可能的,因为padding的query只是初始值是0,reference points也是[0,0],与其他随机初始化的query进行了同样的操作.但由于毕竟是padding的query,我们并不打算使用他们的结果,所以必须要进行过滤.
如何过滤padding query的结果呢?padding query的标志只有他们的索引位置,其他信息都没有特异性.而索引信息其实记录在第3点使用的attention mask 里,也就是从模型外部传入的attention mask.这个mask 是二维的,我们使用其中一维即可(任意一行或任意一列),可以对padding的track_score直接置为0.记得仍然要注意第4步的注意事项,即尽量用矩阵计算代替索引切片赋值,且计算必须转换为float类型.代码示例:
mask = (~attention_mask[-1]).float()
track_scores = track_scores * mask6.如何动态更新track_id
除了模型主体,其实还有非常关键的一步,就是动态更新track_id,这也是模型能做到端到端的一个重要因素.但在原模型中更新track_id的方式是一个相对复杂的循环判断, 即高于score thresh且是新目标的,赋一个新的obj_idx, 低于filter score thresh且是老目标的,对应的disappear time + 1,如果disappear time超过miss_tolerance, 对应的obj idx置为-1,即丢弃这个目标.
我们知道tensorRT是不支持if-else多分支语句的(好吧,我一开始并不知道),这是个头疼的问题.如果将更新track_id也放到模型外部,不仅影响了模型端到端的架构,而且也会导致无法使用QIM,因为QIM筛选query的依据是更新后的track_id.所以绞尽脑汁也要把更新track_id放到模型里面去.
再次发挥聪明才智(快用完了),if-else语句也不是不能代替的,比如使用mask并行操作.例如将条件转换为mask(例如tensor[mask] = 0).这里面值得庆幸的是虽然第4,第5点提到tensorRT不支持索引切片赋值操作,但是却支持bool索引赋值,猜测可能因为切片操作隐性改变了tensor的shape吧.但经过多次实验,也不是所有情况下的bool索引赋值都支持的,出现了以下几种头疼的情况:
a.赋值的值必须是一个,不能是多个,比如我更新新出现的目标时,并不是统一赋值为某一个id,而是需要为每一个目标赋值连续递增的id.这个想到的办法是先统一赋值为一个比较大的不可能出现的数值,比如1000,避免与之前的id重复,然后在后处理中将1000替换为唯一且连续递增的数值.(我真是个大聪明)
b.如果要做递增操作(+=1),只能使用简单mask,即不能涉及复杂逻辑计算,比如对disappear_time的更新,本来需要同时判断obj_idx >=0 且 track_scores < 0.35,但由于这两个变量都与前面的计算图相关,对他们进行与操作可能涉及了比较复杂的逻辑操作,怎么尝试都不成功(尝试了赋值操作代替递增却是成功的,无语).最后的解决办法是省掉obj_idx >=0 这个条件.虽然看似不合理,但分析了一下即使将obj_idx=-1的非目标的disappear_time递增,因为后续这些目标并不会被选入,所以对整体逻辑影响不大.
综上,最后的动态更新track_id示例代码如下,在后处理环节要记得替换obj_idx为1000的数值.:
def update_trackid(self, track_scores, disappear_time, obj_idxs):
disappear_time[track_scores >= 0.4] = 0
obj_idxs[(obj_idxs == -1) & (track_scores >= 0.4)] = 1000
disappear_time[track_scores < 0.35] += 1
obj_idxs[disappear_time > 5] = -1至此模型部分的处理就全部结束了,是不是比较崩溃,但是没办法,部署端到端模型肯定比一般模型要复杂很多.模型最后会输出固定shape的结果,还需要在后处理阶段根据obj_idx是否>0判断需要保留到下一帧的query,再根据track_scores是否>filter score thresh判断当前最终的输出结果.总体来看,需要在模型外进行的操作只有三步:帧间移动reference_points,对输入query进行padding,对输出结果进行过滤和转换格式,基本上实现了端到端的目标检测+目标跟踪.
还要说明的是以上6点存在操作的顺序,我这里是按照问题分类来写的,实际上遇到的顺序可能是1->2->3->5->6->4,因为第5,6点是使用QIM的前提,第5和第6也存在依赖关系.还有一个问题是我没有使用memory bank,即时序融合的模块,因为经过实验这个模块提升不是很大,而且对于端到端跟踪机制来说,已经天然地使用了时序融合(毕竟直接将前序帧query带到下一帧),所以时序融合更加显得不是非常必要.
好了,现在我们可以进行tensorRT的推理结果和pytorch的推理结果的对比,会发现fp32精度下可以实现精度对齐,撒花!!!!!但如果需要转fp16(可以大幅降低部署时延),第一次推理会发现结果完全变成none(再次崩溃).导致fp16结果为none一般都是因为出现数据溢出,即数值大小超限(fp16最大支持范围是-65504~+65504),如果你的代码用了一些自己特殊的操作,或者你的数据天然数值较大,例如内外参,pose等数据很可能超限,一般通过缩放等方式解决.这里说一下和我以上6点相关的一个原因:
7.使用attention_mask导致的fp16结果为none的问题
这个问题非常隐蔽,因为问题隐藏在torch.nn.MultiheadAttention源码中,具体在torch.nn.functional.py文件中,有以下几句:
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=q.dtype)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask可以看到,这一步操作是对attn_mask中值为True的元素用float("-inf")填充,这也是attention mask的原理所在,也就是值为1的位置会被替换成负无穷,这样在后续的softmax操作中,这个位置的输入会被加上负无穷,输出的结果就可以忽略不记,不会对其他位置的输出产生影响.大家也能看出来了,这个float("-inf")是fp32精度,肯定超过fp16支持的范围了,所以导致结果为none.我在这里把它替换为fp16支持的下限,即-65504,转fp16就正常了,虽然说一般不要修改源码,但这个确实没办法.不要问我怎么知道这么隐蔽的问题的,因为不是我一个人想到的.但如果使用attention_mask之前仔细研究了原理,想到也不难.
OK,以上就是我踩坑端到端模型部署的全部经验,说全网唯一肯定不是标题党.因为接触tensorRT也不久,肯定有描述不准确的地方,或者说并需要这么复杂的操作,欢迎大家在留言区跟我探讨.
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
















 2473
2473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









