






点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
写在前面&笔者的个人理解
目前,自动驾驶技术已经愈发的成熟,很多车企都已经在自家的车辆产品上配备了自动驾驶算法,使车辆具备了感知、决策、自主行驶的能力,下图是一个标准的自动驾驶算法流程图。

通过上面展示出来的标准自动驾驶流程图可以清晰的看出,整个自动驾驶流程包括五个子模块:
场景传感器:采用不同的数据传感器对当前的周围场景进行信息的采集工作,对于自动驾驶车辆来说,常见的数据采集传感器可以包括:相机(Camera),激光雷达(Lidar),毫米波雷达(Radar),超声波传感器(Ultrasonics)等等。
感知和定位:在获得了来自场景传感器采集到各种数据信息之后,会将采集到的相关信息送入到不同的感知和模型当中输出对当前环境的感知和定位结果,这里会涉及到的相关感知算法可以包括:车道线检测感知算法(Lane Detection),目标检测感知算法(Object Detection),语义分割感知算法(Semantic Segmentation),定位和建图算法(SLAM),高精地图算法(HD Maps)等等。
周围环境建模:在得到上一步各种感知模型的预测结果后,目前主流的做法是将各类感知算法输出的预测结果以车辆自身(Ego)为坐标系进行融合,从而构建一个周围环境感知行为的BEV空间预测地图,从而方便下游的规划和控制任务。
规划:在得到上一步输出的当前周围环境的BEV感知结果地图后,自动驾驶车辆上配备的路径规划算法会根据当前的交通规则以及车辆自身位姿设计相关的行驶路径,并根据行驶路径输出一套完整的相关驾驶行为决策。
控制:控制模块也就是整个自动驾驶流程的最后一步,此时的车辆会根据规划模块输出的一整套完成的驾驶行为决策进行判断,从而采取如转向(Steer),汽车加速(Accelerate),汽车减速(Brake)等相关的行为,实现对车辆的控制。
以上就是大致介绍了一下整个自动驾驶流程包括的所有内容,基本说明了一辆自动驾驶汽车从收集数据开始到最终完成驾驶行为的全过程。相信大家也可以看出,如果一辆自动驾驶汽车想要做出准确的决策,周围环境信息数据的采集和感知和定位算法模型的预测结果扮演了整个驾驶流程中至关重要的角色。
那么你接下来,我们先重点介绍一下自动驾驶流程图的第一步:周围环境信息数据的采集模块:
相机传感器是目前自动驾驶中最常用的数据采集传感器之一,因其可以采集到具有丰富语义信息的图像数据,且价格低廉而被广泛采用。一般而言,相机传感器包括:针孔相机或者鱼眼相机。鱼眼相机在一些短范围内的感知具有广泛的应用前景,然而无论是哪种类型的相机传感器,在面对现实世界的驾驶场景当中,都面临着一些非常严峻的问题,相关问题列举如下:
相机传感器在光线较暗的情况下表现较差:因为相机这类图像传感器主要是利用光线照射到物体上进行成像,但是在这种有限的光照条件下,严重的阻碍了成像结果中物体语义表示的质量,从而影响模型最终输出的感知结果,直接影响了后续的规控等任务 。
相机会暴露在外部自然场景当中:目前的自动驾驶车辆中,普遍都是采用环视相机的采集方式,同时这类环视相机通常都是安装在自动驾驶车辆的外部,这就会导致环视相机会暴露在沙子,泥土,污垢,灰尘,雨雪或者杂草等环境中,对相机造成影响,从而间接的影响到相机的成像结果,或者外参矩阵,间接的影响后续的感知定位、规划、控制等任务中。
强烈太阳光的干扰:在某些自动驾驶场景当中,可能会存在着天气特别晴朗的情况,这就会导致太阳光线过于充足,太阳的眩光会导致相机传感器的镜头表面被过度的曝光,严重影响了相机传感器采集到的图像质量,阻碍了下游基于视觉的障碍物感知算法的预测效果, 进而直接影响到后续的规划、控制模块的决策结果。
通过上述提到的诸多现实问题可以看出,虽然相机传感器不仅价格低廉,而且可以为后续的障碍物感知算法提供丰富的目标语义信息,但是其受环境的影响是非常巨大的,这就表明我们需要在自动驾驶车辆上配备额外传感器的原因。我们发现超声波传感器具有低功耗,对物体的颜色、材料不敏感,还可以比相机传感器更好的抵抗环境中的强烈光线,同时可以进行比较准确的短距离目标检测,对自动驾驶的障碍物感知是具有很要的数据采集价值。
考虑到以上传感器因素,同时为了更好的匹配下游的规控任务,我们在本文中设计了一种端到端的基于CNN卷积神经网络的多模态感知算法,利用鱼眼相机传感器和超声波传感器作为输入,实现在BEV空间的障碍物感知任务。
论文链接:https://browse.arxiv.org/pdf/2402.00637.pdf;
网络模型的整体架构细节梳理
下图是我们提出的算法模型的整体框架图,在介绍本文提出的基于CNN卷积神经网络的多模态感知算法各个子部分的细节之前,我们先整体概括一下整个算法的运行流程。
首先是采用预处理步骤,将超声波传感器采集到的原始回波数据的幅度信息转换为卷积神经网络可以进行处理的2D图像形式的数据。
其次采用CNN卷积神经网络对每个模态传感器采集到的数据完成特征提取过程,并且将提取到的多个模态的特征进行融合,构建出最终的模态无关特征。
然后是将上一步得到的模态无关特征完成空间上的转换过程得到BEV空间下的特征。
最后是将BEV空间特征喂入到语义分割任务的解码器当中,得到像素级别的障碍物预测结果。
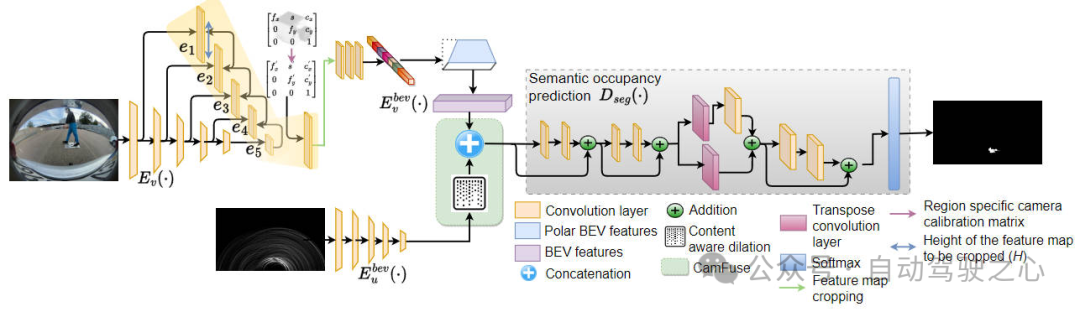
单一模态特征提取编码器
由于我们采用了鱼眼相机传感器以及超声波传感器,所以采用在网络中我们采用了两个独立的单模态特征提取编码器ResNeXt-50来完成各自模态特征的采集任务,在图上我们分别用和来进行表示区分,分别用于提取透视图的图像特征以及超声波的光谱特征。通过对特征图的可视化结果我们发现,对于一些障碍物类型,BEV空间中的障碍物的占用率不足以从超声波传感器中获得足够强的响应,下图展示了不同障碍物类型对应的超声波传感器采集到的数据响应。

像以往的基于视觉的BEV感知算法范式类似,我们这里也是对输入的鱼眼相机图像进行了多尺度的特征提取用于检测当前数据集中不同尺度大小的障碍物目标。由上图所示,图中的每个模块都是代表一个特征金字塔结构,用于输出多尺度的上下文语义特征。具体而言,每个特征金字塔模块都是采用一组残差块来完成多尺度特征的提取和微调过程的,同时对较低分辨率的特征图,我们采用上采样操作完成不同尺度特征图间的语义融合过程。在此之后,我们同样是利用相机的外参矩阵完成2D图像坐标系向3D的BEV空间坐标系的转换过程。
BEV空间坐标系的映射过程
因为我们要完成鱼眼相机的2D图像特征向3D的BEV空间特征的变换,我们采用了Kannala-Brandt相机模型来实现这一变换过程。相比于基于图像中心半径的距离来表示径向畸变不同,Kannala-Brandt算法模型将相机畸变看作为通过透镜的光入射角函数,如下图的公式(1)所示。
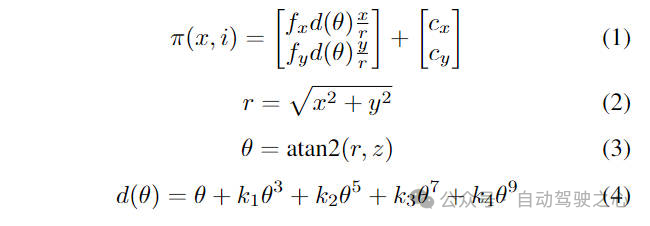
其中,公式中的以及分别代表鱼眼相机的焦距,代表图像点和主点之间的距离。代表主轴和入射光线之间的夹角,和表示沿着和轴的主点。代表多项式方程中第阶的鱼眼失真系数,是点到相机的距离。
由于在BEV投影过程中,需要将2D的图像特征投影到3D的BEV空间中,这就需要确保世界坐标空间中特定的网格区域的表示是非常准确的。因此,我们考虑将每个来自特征金字塔的特征图进行裁剪,从而保证2D图像特征对应于现实世界空间中定义的最大边界的精确上下边界。因此为了更好的从特征图中裁剪出相应区域,我们从公式(2,3,4)中确定失真系数。通过使用具有相应焦距、失真参数、主点和世界坐标空间高度和深度的公式(1),我们可以获得表示现实世界空间坐标系的图像空间坐标(u, v),从而就可以确定变换过程中每个网格的最小和最大深度,从而完成特征金字塔不同尺度特征的裁剪过程,最后利用相机的外参矩阵实现将图像特征变换为BEV空间特征。
基于内容感知的膨胀和多模态特征融合
由于本文是多模态的感知算法,需要同时利用图像和超声波的光谱特征,这就会遇到多模态算法中无法避开的一个问题:由于不同传感器采集到的数据代表了不同形式的环境表示。鱼眼相机通过图像像素的方式来捕获当前环境中丰富的语义信息,但是会丢失掉目标的深度以及几何结构信息。超声波传感器通过接收发射信号打到物体后发射回来的回波信号来感知周围的环境。这种不同传感器采集到的数据模态上的差异增加了特征融合过程中的难度。除此之外,在前文也有提到,相机传感器通常会暴露在自动驾驶车辆的外部,这就会造成周围环境会使得传感器发生潜在的错位风险,导致不同传感器采集到的同一个目标可能会在BEV空间中落到不同的网格单元中,从而直接造成融合后的多模态特征出现歧义性的问题,影响最终的感知算法预测结果。
所以,综合考虑到上面提到的多模态特征表示存在的差异,以及还可能出现的传感器错位之间的风险,我们提出了基于内容感知的膨胀和多模态特征融合模块。该模块中的膨胀卷积可以根据卷积核所在特征图的不同位置自适应的调整膨胀率的大小,相应的自适应膨胀卷积的计算公式如下:

其中和分别代表膨胀卷积中的膨胀率大小以及卷积核可学习的权重参数。代表输入的特征图。同时我们根据特征图的相关位置,采用如下的计算公式来自适应的调整膨胀率的大小。

以上就是我们提出的基于内容的膨胀卷积,通过该卷积用于调整超声波BEV空间特征。随后,将膨胀后的BEV空间特征与鱼眼相机完成空间转换后的BEV空间特征合并起来,从而实现多模态特征信息的融合,从而实现更准确的障碍物感知任务。
语义占用预测头
在获得了多模态的BEV空间特征后,我们制定了一个双阶段的多尺度语义占用网格预测解码器来得到最终的网格地图占用预测。解码器的具体网络结构如图九所示,该结构有两个顺序级联的残差块组成。第一个残差块用于避免在相同的分辨率内损害目标的空间特征。第二个残差块通过利用上下文特征来学习不同障碍物类型的先验几何形状信息。将多模态的BEV空间特征在多组级联的卷积网络中作用后得到最终的分割结果。
实验结果和评价指标
评价指标
由于我们设计的障碍物感知算法需要涉及到二值分割来区分前景和背景区域的目标,所以我们采用了一下的相关指标来评价我们设计模型的好坏。
召回率指标:该指标可以很好的反映出系统对于障碍物的感知能力,同时该指标也广泛应用于2D、3D检测任务当中,这里就不过多介绍了。
欧几里得距离指标:该指标可以帮助我们评估预测障碍和地面真实障碍在空间位置方面的一致性程度。预测障碍物与实际障碍物之间的距离是关键信息,以确保系统准确地感知障碍物的位置。
绝对距离误差:该指标可以准确的反映出障碍物感知网络模型将障碍物相对于自车作为参考的接近程度。通过了解这种相对距离有助于对象回避、刹车或者在转向的过程中做出实施决策。
归一化距离指标:该指标可以更好的评价模型预测出来的障碍物与自车之间的距离性能好坏。
实验结果(定量指标)
首先,我们比较了提出的多模态障碍物感知算法模型在室内和室外两种环境空间以及不同传感器下的检测性能,具体定量的数据指标如下图所示:

通过实验结果可以看出,在室内场景来看,由于采用了超声波传感器采集到的数据,障碍物感知算法模型在距离指标上有着非常出色的预测优势,同时在召回率方面也要大幅度的超过单模态(纯相机)的算法算法版本。对于室外场景而言,所提出的算法模型得益于多模态数据互补的优势,各个指标均都要大幅度领先于单模态视觉的感知算法版本。
接下来是针对当前的两种不同版本的算法模型在各个不同障碍物类别上的感知结果性能汇总,不同类别具体定量的实验数据汇总在下表当中
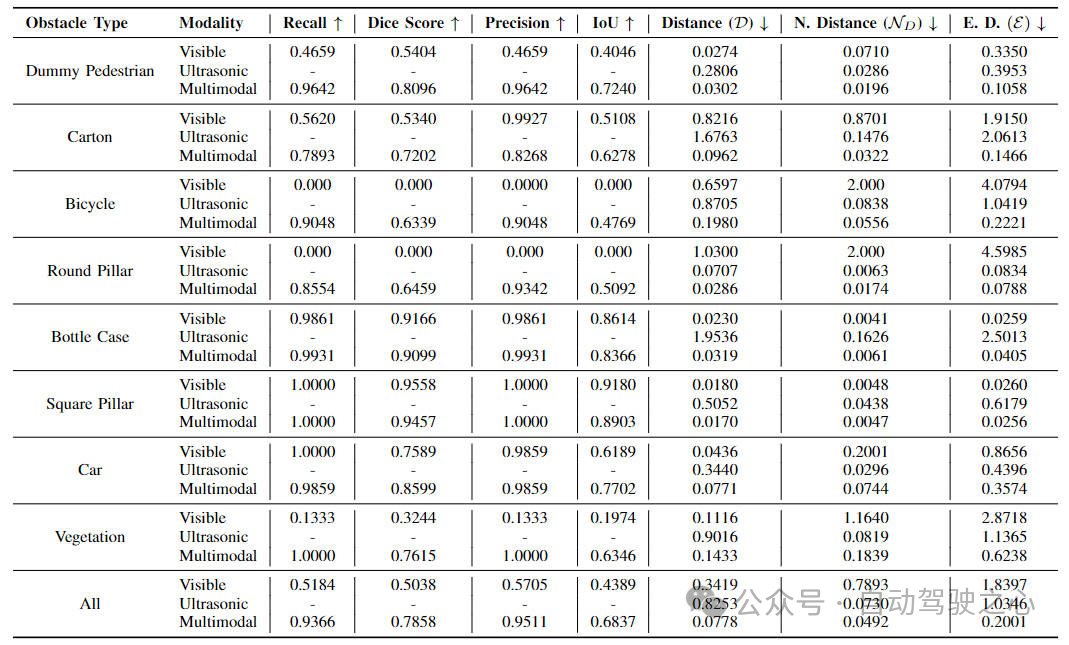
通过上表可以看出,对于绝大多数的障碍物目标,当前提出的多模态算法模型在召回率、精度、交并比、距离、归一化距离、欧氏距离等各个指标上均要明显的高于单模态纯图像的算法版本。由此说明,通过多种模态的数据进行信息互补,不仅提高算法模型对于障碍物的检测识别性能,同时还可以更加精确的定位障碍物的的具体位置。
为了进一步的展示我们提出的多模态感知算法模型在距离上的感知优势,我们对不同距离段的感知性能指标进行了统计,具体统计结果如下表所示。
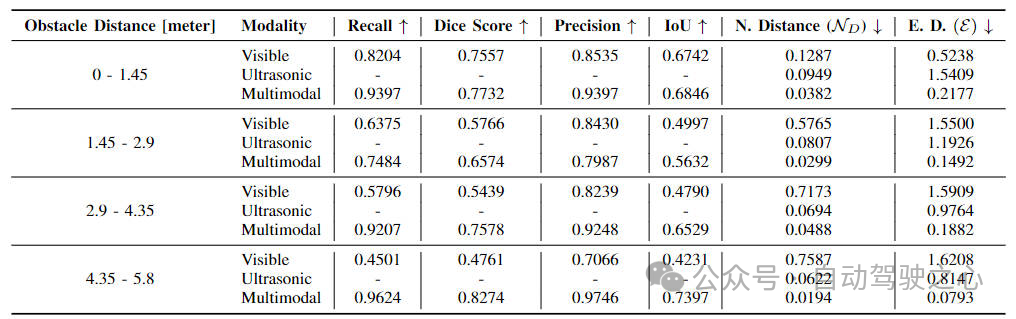
我们将模型5.8米的感知范围分成了四个不同的距离段,通过实验数据可以看出,随着距离的变远,仅仅使用单模态纯视觉的算法版本其召回率,距离性能均是不断下降的,因为随着距离的变远,图像中的目标变得越来越小,模型对于目标的特征提取变得更加困难。但是随着超声波传感器采集的信息加入,可以明显的看出,随着距离的变远,模型的精度并没有明显的降低,实现了不同传感器信息的互补优势。
实验结果(定性指标)
下面是我们多模态算法模型感知结果的可视化效果,如下图所示。

结论
本文首次提出了利用鱼眼相机传感器以及超声波传感器进行BEV空间的障碍物感知算法,通过定量指标(召回率、精度、欧氏距离以及归一化距离等指标)可以证明我们提出算法的优越性,同时上文可视化的感知结果也可以说明我们算法出色的感知性能。
参考
[1] Fisheye Camera and Ultrasonic Sensor Fusion For Near-Field Obstacle Perception in Bird’s-Eye-View
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近2700人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦语义分割、车道线检测、目标跟踪、2D/3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、在线地图、点云处理、端到端自动驾驶、SLAM与高精地图、深度估计、轨迹预测、NeRF、Gaussian Splatting、规划控制、模型部署落地、cuda加速、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
















 2435
2435











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









