






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | 自动驾驶Daily
编辑 | 自动驾驶之心
原标题:Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
论文链接:https://arxiv.org/pdf/2405.17398
代码链接:github.com/OpenDriveLab/Vista
作者单位:香港科技大学 上海人工智能实验室OpenDriveLab University of Tübingen Tübingen AI Center 香港大学

论文思路:
世界模型可以预见不同动作的结果,这对于自动驾驶至关重要。然而,现有的驾驶世界模型在泛化到未见环境、关键细节的预测保真度以及灵活应用的动作可控性方面仍存在局限性。本文提出了Vista,这是一种具有高保真度和多功能可控性的通用驾驶世界模型。基于对现有方法的系统诊断,本文引入了几个关键成分来解决这些局限性。为了在高分辨率下准确预测现实世界的动态,本文提出了两种新的损失函数,以促进对移动实例和结构信息的学习。本文还设计了一种有效的潜在替换(latent replacement)方法,将历史帧作为先验注入,以实现连贯的长时间滚动预测(rollouts)。对于动作可控性(action controllability),本文通过一种高效的学习策略,结合了从高层意图(命令、目标点)到低层操作(轨迹、角度和速度)的一套多功能控制。在大规模训练之后,Vista的能力可以无缝地泛化到不同的场景。对多个数据集的广泛实验表明,Vista在超过70%的比较中优于最先进的通用视频生成器,并在FID上超过表现最佳的驾驶世界模型55%,在FVD上超过27%。此外,本文首次利用Vista自身的能力,在不访问真实动作(ground truth actions)的情况下,建立了一个通用的奖励机制,用于真实世界动作评估。
主要贡献:
(1) 本文提出了Vista,这是一种通用的驾驶世界模型,能够在高时空分辨率下预测逼真的未来。通过捕捉动态(capture dynamics)和保持结构(preserve structures)的两种新损失函数,以及详尽的动态先验以维持长时间滚动预测(long-horizon rollouts)的一致性,其预测保真度得到了极大提升。
(2) 在高效学习策略的推动下,本文通过统一的条件接口将多功能动作可控性集成到Vista中。Vista的动作可控性还可以在零样本的情况下泛化到不同领域。
(3) 本文在多个数据集上进行了全面的实验,以验证Vista的有效性。它优于最具竞争力的通用视频生成器,并在nuScenes数据集上设立了新的最先进水平。本文的实验证据表明,Vista可以用作评估动作的奖励函数(reward function)。
网络设计:
在可扩展学习技术的驱动下,自动驾驶在过去几年中取得了令人鼓舞的进展 [17, 54, 129]。然而,对于当前最先进的技术而言,复杂和分布外的情况仍然难以处理 [77]。一种有前景的解决方案是世界模型 [53, 70],它们从历史观察和替代动作中推断出世界的可能未来状态,从而评估这些动作的可行性。世界模型有潜力在不确定性中进行推理并避免灾难性错误 [50, 70, 120],从而促进自动驾驶中的泛化和安全性。
尽管世界模型的主要前景是赋予其在新环境中的泛化能力,但现有的驾驶世界模型仍受限于数据规模 [84, 118, 120, 137, 140] 和地理覆盖范围 [50, 57]。如表1和图1所总结的那样,它们通常还局限于低帧率和低分辨率,导致关键细节的丢失。此外,大多数模型仅支持单一的控制模式,例如转向角和速度。这不足以表达从高层意图到低层操作的各种动作形式,并且与流行的规划算法的输出不兼容 [12, 14, 19, 52, 54, 60]。此外,动作可控性在未见数据集上的泛化能力研究不足。这些局限性阻碍了现有工作的适用性,因此开发一种能够克服这些局限性的世界模型势在必行。
为此,本文引入了Vista,这是一种在跨领域泛化、高保真预测和多模态动作可控性方面表现出色的驾驶世界模型。具体来说,本文在全球驾驶视频的大型语料库 [130] 上开发了预测模型,以培养其泛化能力。为了实现连贯的未来推断,本文将Vista基于三种基本的动态先验条件(见第3.1节)。不仅依赖于标准的扩散损失 [5],本文还引入了两种显式损失函数,以增强动态并保持结构细节(见第3.1节),从而提升Vista在高分辨率下模拟逼真未来的能力。为了实现灵活的可控性,本文结合了一套多功能动作格式,包括高层意图(如命令和目标点)以及低层操作(如轨迹、转向角和速度)。这些动作条件通过一个统一接口注入,并通过高效的训练策略进行学习(见第3.2节)。因此,如图2所示,Vista获得了以10 Hz和576×1024像素预测逼真未来的能力,并在各种粒度水平上实现了多功能动作可控性。本文还展示了Vista作为通用奖励函数评估不同动作可靠性的潜力。
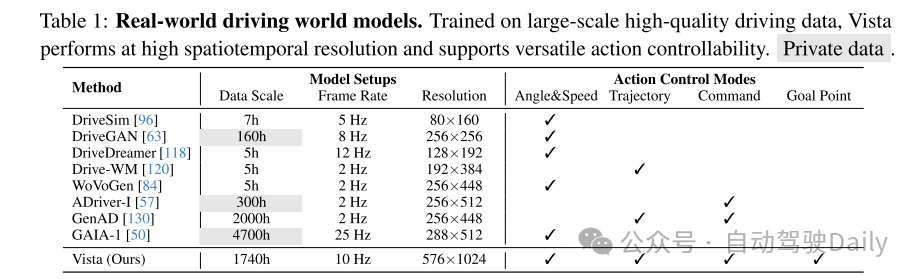
表1:真实世界的驾驶世界模型。Vista在大规模高质量驾驶数据上训练,能够在高时空分辨率下运行,并支持多功能动作可控性。

图1:分辨率比较。Vista的预测分辨率高于以往文献中的模型。

图2:Vista的能力。Vista可以从任意环境出发,在高时空分辨率下预测逼真且连续的未来(A-B)。它可以通过多模态动作进行控制(C),并作为通用奖励函数评估真实世界的驾驶动作(D)。
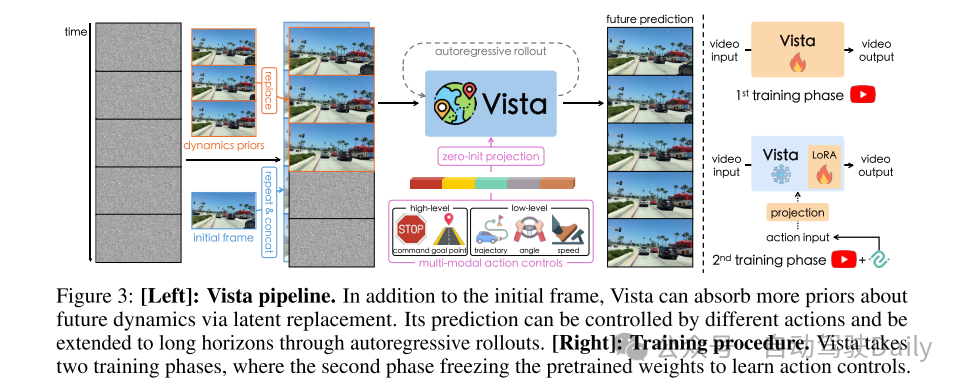
图3:[左]:Vista流程。除了初始帧,Vista还可以通过潜在替换吸收更多关于未来动态的先验知识。其预测可以通过不同的动作进行控制,并通过自回归展开扩展到长时间范围。[右]:训练过程。Vista分为两个训练阶段,在第二阶段中冻结预训练权重以学习动作控制。

图4:损失设计示意图。与标准扩散损失(b)均匀分布不同,本文的动态增强损失(d)能够自适应地集中在关键区域(c)(例如移动的车辆和道路边缘)进行动态建模。此外,通过显式监督高频特征(e),可以增强结构细节(例如边缘和车道)的学习。
实验结果:

图5:在相同条件帧下由不同模型预测的驾驶未来。本文将Vista与公开可用的视频生成模型在其默认配置下进行对比。尽管之前的模型会产生不对齐和损坏的结果,Vista则不会出现这些问题。

图6:[顶部]:长时间预测。Vista可以在没有太多退化的情况下预测15秒高分辨率的未来,涵盖长距离驾驶。蓝线的长度表示之前工作中展示的最长预测时间。[底部]:SVD的长期扩展结果。SVD未能像Vista那样自回归地生成一致的高保真视频。
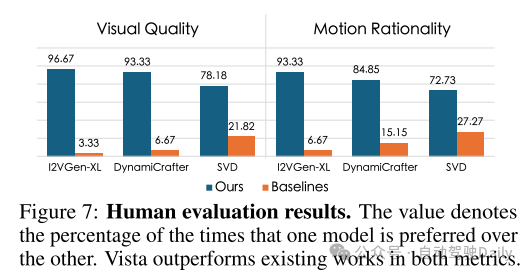
图7:人工评估结果。数值表示一个模型优于另一个模型的百分比。Vista在两个指标上都优于现有的工作。
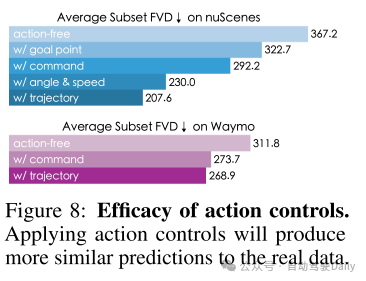
图8:动作控制的效果。应用动作控制将生成与真实数据更为相似的预测。

图9:多功能动作可控性。Vista能够在多种情景下响应多模态动作条件,预测相应的结果。更多结果请参见附录E。
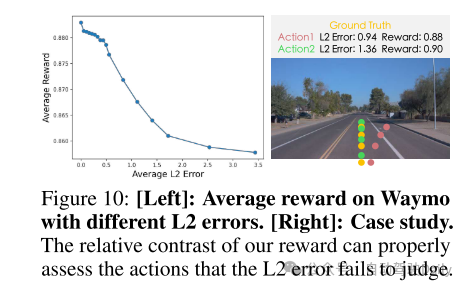
图10:[左]:在Waymo上的不同L2误差的平均奖励。[右]:案例研究。本文的奖励的相对对比可以正确评估L2误差无法判断的动作。

图11:动态先验的效果。注入更多的动态先验可以产生与真实值更一致的未来运动,例如左侧白色车辆和广告牌的运动。
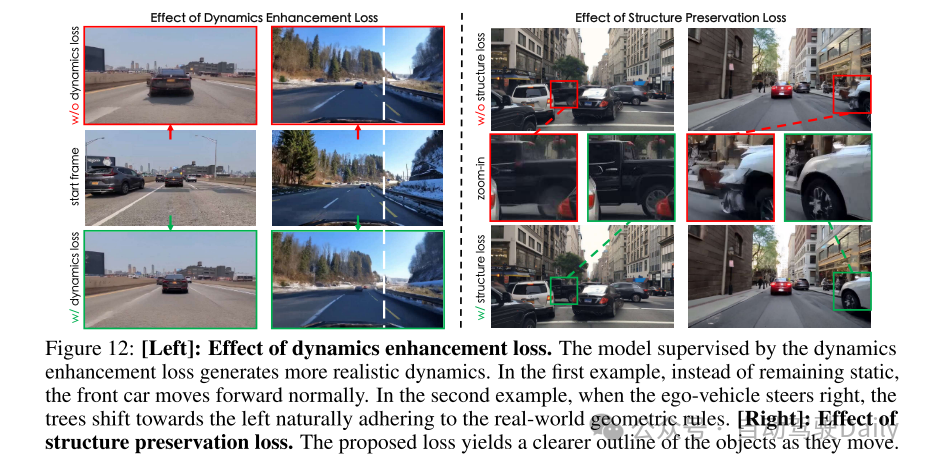
图12:[左]:动态增强损失的效果。通过动态增强损失监督的模型生成更逼真的动态。在第一个例子中,前车没有保持静止,而是正常前进。在第二个例子中,当自车向右转向时,树木自然地向左移动,遵循现实世界的几何规则。[右]:结构保持损失的效果。所提出的损失使物体在移动时轮廓更加清晰。

总结:
本文提出了Vista,这是一种具有增强保真度和可控性的可泛化驾驶世界模型。通过系统性的研究,Vista能够以高时空分辨率预测真实且连续的未来。它还具备多功能动作可控性,能够泛化到未见过的场景。此外,Vista可以被构建为一个奖励函数来评估动作。本文希望Vista能够引发更广泛的兴趣,推动可泛化自主系统的发展。
引用:
Gao S, Yang J, Chen L, et al. Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability[J]. arXiv preprint arXiv:2405.17398, 2024.
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









