






0. 论文信息
标题:Vista: A Generalizable Driving World Model with High Fidelity and Versatile Controllability
作者:Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, Hongyang Li
机构:Hong Kong University of Science and Technology、OpenDriveLab at Shanghai AI Lab、University of Tübingen、Tübingen AI Center、University of Hong Kong
原文链接:https://arxiv.org/abs/2405.17398
代码链接:https://github.com/opendrivelab/vista
1. 摘要
世界模型可以预见不同动作的结果,这对自动驾驶至关重要。然而,现有的驾驶世界模型在对未知环境的泛化、关键细节的预测逼真度以及灵活应用的动作可控性方面仍然存在局限性。在本文中,我们提出了Vista,一个通用的驾驶世界模型,具有高保真度和多方面的可控性。基于对现有方法的系统诊断,我们引入了几个关键因素来解决这些限制。为了以高分辨率准确预测真实世界的动态,我们提出了两种新的损失来促进移动实例和结构信息的学习。我们还设计了一个有效的潜在替代方法来注入历史框架作为连贯的长期部署的先验。对于动作可控性,我们通过有效的学习策略,整合了一套从高级意图(命令、目标点)到低级机动(轨迹、角度和速度)的通用控制。经过大规模的训练,Vista的能力可以无缝地推广到不同的场景。在多个数据集上的大量实验表明,Vista在超过70%的比较中优于最先进的通用视频生成器,并在FID中超过表现最好的驾驶世界模型55%,在FVD超过27%。此外,我们第一次利用Vista本身的能力,在不访问真实行动的情况下,为现实世界的行动评估建立一个可概括的奖励。
2. 引言
得益于可扩展学习技术的推动,自动驾驶在过去几年中取得了令人鼓舞的进展。然而,对于最先进的技术而言,复杂且超出分布范围的情况仍然难以处理。一个有望的解决方案在于世界模型,这些模型根据历史观测和备选动作推断出世界可能的未来状态,进而评估这些动作的可行性。它们具有在不确定情况下进行推理并避免灾难性错误的潜力,从而推动自动驾驶中的泛化能力和安全性。大多数模型仅支持单一控制模式,如转向角和速度,这不足以表达从高级意图到低级操作的多种动作格式,且与流行的规划算法的输出不兼容。此外,对未见数据集的动作可控性的泛化研究尚不充分。这些局限性阻碍了现有工作的适用性,因此迫切需要开发一种克服这些局限性的世界模型。
为此,我们引入了Vista,一个擅长跨域泛化、高保真预测和多模态动作控制的驾驶世界模型。具体而言,我们在全球驾驶视频的大型语料库上开发预测模型,以增强其泛化能力。为实现连贯的未来外推,我们将Vista建立在三个基本动态先验之上。除了仅依赖标准扩散损失外,我们还引入了两个显式损失函数来增强动态性并保留结构细节,从而提升了Vista在高分辨率下模拟现实未来的能力。为了实现灵活的可控性,我们整合了一套多功能动作格式,包括高级意图(如命令和目标点)以及低级操作(如轨迹、转向角和速度)。这些动作条件通过统一接口注入,该接口通过高效的训练策略学习得到。
3. 效果展示
尽管世界模型的主要前景之一是使系统具备对新环境的泛化能力,但现有的驾驶世界模型仍受到数据规模和地理覆盖范围的限制。如表1和图1所示,这些模型还经常被限制在低帧率和低分辨率下,导致关键细节的丢失。
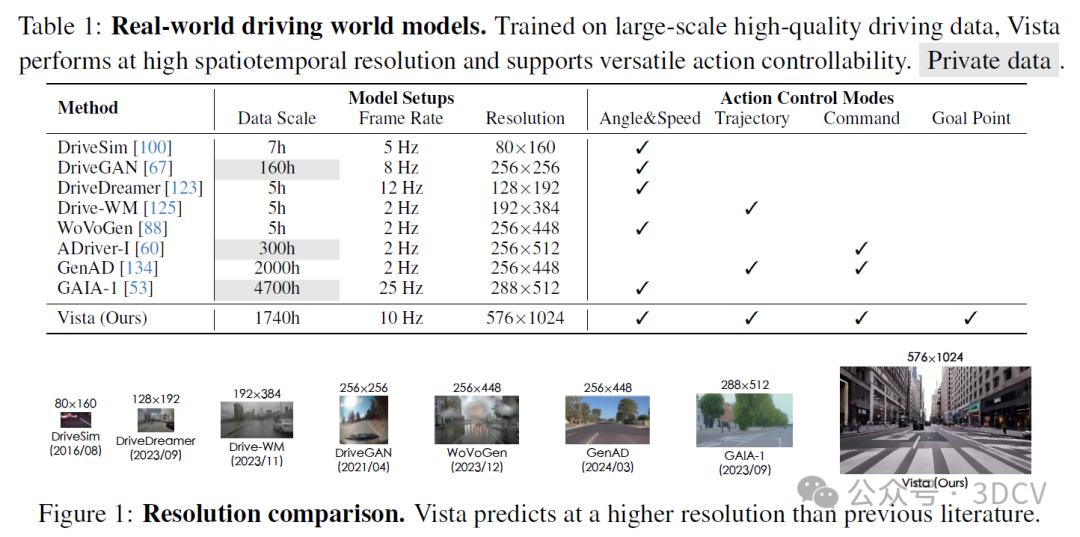
如图2所示,Vista能够以10 Hz和576×1024像素的分辨率预测现实未来,并在不同粒度级别上获得多功能动作控制能力。我们还展示了Vista作为可泛化的奖励函数来评估不同动作可靠性的潜力。

4. 主要贡献
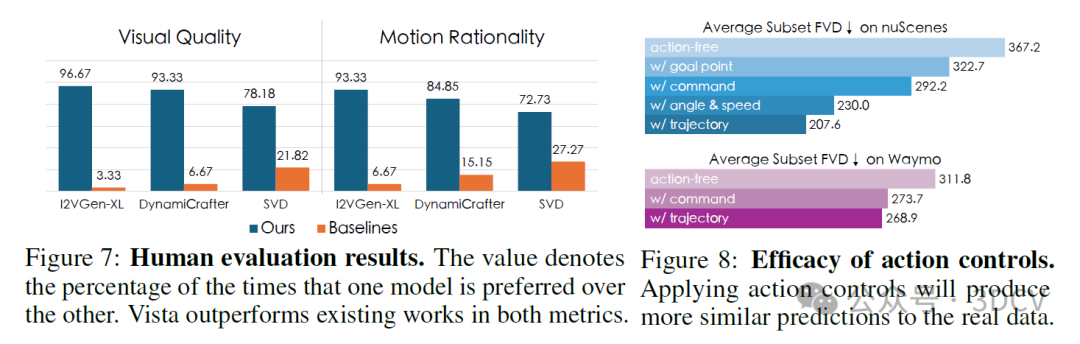
我们的贡献主要体现在以下三个方面:(1)我们提出了Vista,一个可泛化的驾驶世界模型,能够在高时空分辨率下预测现实未来。通过两个新颖的损失函数来捕捉动态并保留结构,以及详尽的动态先验来维持长期滚动预测的一致性,其预测保真度得到了大幅提升。(2)在高效学习策略的推动下,我们通过统一条件接口将多功能动作控制能力集成到Vista中。Vista的动作控制能力还可以以零样本方式泛化到不同领域。(3)我们在多个数据集上进行了全面实验,验证了Vista的有效性。其性能优于最具竞争力的通用视频生成器,并在nuScenes上树立了新的最先进水平。我们的实证证据表明,Vista可以用作评估动作的奖励函数。推荐课程:面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)。
5. 方法
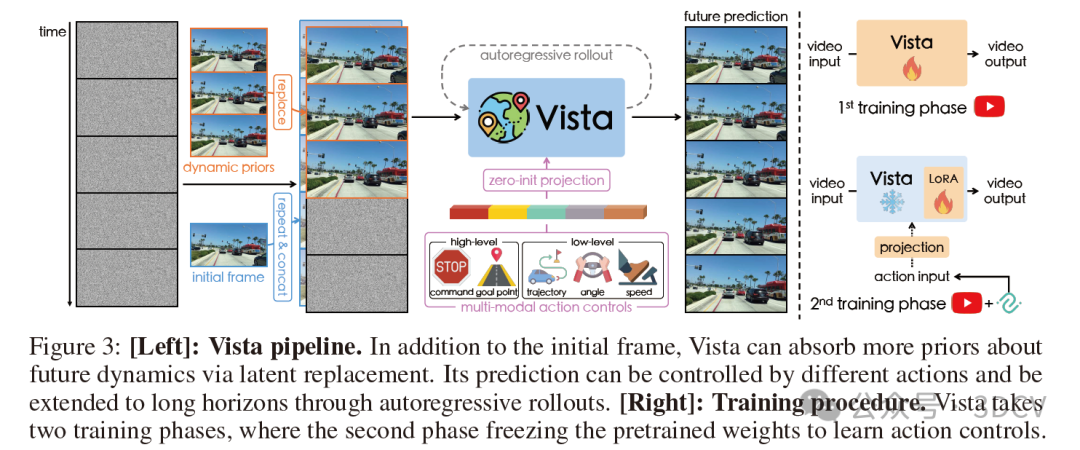
如图3所示,Vista采用了一个两阶段的训练流程。首先,我们构建了一个专用的预测模型,该模型采用了一种潜在替换方法来实现连贯的未来预测,并引入了两个新的损失函数来提高预测保真度。为了确保模型能够泛化到未见过的场景,我们利用最大的公共驾驶数据集进行训练。在第二阶段,我们结合了多模态动作,采用了一种高效且协同的训练策略来学习动作可控性。利用Vista的能力,我们进一步引入了一种可泛化的动作评估方法。
6. 实验结果

7. 总结 & 未来工作
在本文中,我们介绍了Vista,一个具有增强保真度和可控性的可泛化驾驶世界模型。基于我们的系统研究,Vista能够以高时空分辨率预测真实且连续的未来场景。它还具备可泛化到未见场景的多功能动作可控性。此外,它可以被制定为奖励函数来评估动作。我们希望Vista能够激发人们对开发可泛化自主系统的更广泛兴趣。
局限性和未来工作。作为早期尝试,Vista在计算效率、质量保持和训练规模方面仍存在一些局限性。我们未来的工作将研究将我们的方法应用于可扩展架构。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









