






点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
今天自动驾驶之心今天为大家分享一篇ECCV'24最新工作ViewFormer: 高效的多视图时空建模占据网络。如果您有相关工作需要分享,请在文末联系我们!
编辑 | 自动驾驶之心
我们组最近的工作ViewFormer: Exploring Spatiotemporal Modeling for Multi-View 3D Occupancy Perception via View-Guided Transformers(https://arxiv.org/abs/2405.04299)主要讨论多视角相机时空感知问题,虽然围绕占据网格任务展开,但实施方法聚焦在时空特征建模方面,同样适用于其他主流智驾感知任务。该方法近期还获得了RoboDrive Challenge (https://robodrive-24.github.io/)Occupancy赛道冠军。观点如下:
基于Transformer的稀疏多视图特征交互方案中,主流方法主要沿用类BEVFormer的方法,先将3D参考点投影到图像上,再利用2D的deformable attn.收集特征,文中我们将该方案称为projection-first方法。受限于传感器布局,不同相机之间的共视区域通常较少,多数3D参考点本身仅能投影到单张图像内,导致该方法仅能为query收集到单图像的特征,有违多视图感知的初衷。针对该问题我们提出了learning-first方案,先学习3D局部点集,再利用局部3D点集去收集多视图特征,我们将各query的局部点集定义在各query视角坐标系下,使得点集offset量不随query坐标变化,通过引入车身四周旋转不变性来加速收敛。总的来说,在我们learning-first方案中,query能否收集到多视图的特征的过程变成了一种数据驱动的方式,不再像projection-first方法受限于传感器布局。
在temporal modeling方面,我们主要考虑工程实用性和通用性,在特征图层面实现了online video多帧交互的建模方案。为了充分发挥temporal优势,我们还引入occupancy flow的任务,在flow任务上,本文关注真正occupancy level的flow,而非object level的flow,两者的区别主要是object flow为object框内的occ.赋值了相同的flow vector,真的occupancy flow会有更加细粒度的表示。题外话,occ. flow与目标的整体性是对立的,让PnC同学看到会比较头疼...本文旨在探讨细粒度4D场景的潜力,或许可以为未来e2e框架提供更好的感知表示。
下面会就几个核心部分展开讨论。
View Attention
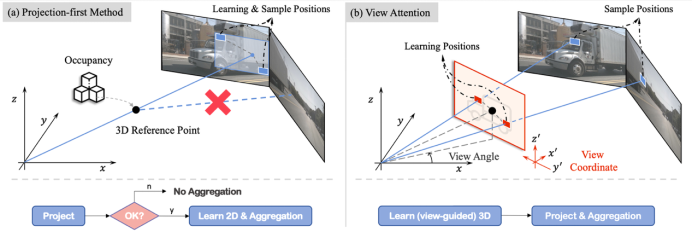
如图所示,左边图(a)是上文提到的类BEVFormer的projection-first方法,可能出现的问题是3D参考点如果不能投影到某个图像上,就不会为该query收集该图像特征。与之相对,右边图(b)是我们的learning-first view attn.,通过先学习定义在view坐标系的3D点集,再用点集收集多视图特征,使得能否收集多视图特征这件事变成了一种数据驱动的方式。
Overview
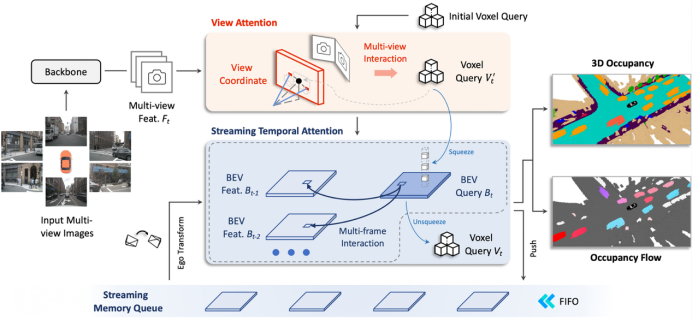
整个ViewFormer框架流程图如上图,我们直接用voxel级别的query,在View Attn.模块中收集当前帧多视图的特征。在时序交互模块Streaming Temporal Attn.模块中,为了降低算力和存储开销,voxel query会被压缩为BEV query,当前帧的BEV query会同时和存储在Streaming Memory Queue中的历史多帧BEV特征做交互,时序这部分算子直接用的deformable attn.,时序交互完,更新后的BEV query会被升维到voxel query,最终voxel query在head部分会负责预测occ.状态和occ. flow。当前帧的BEV特征会被压入Streaming Memory Queue中成为后续帧的历史特征。训练和推理都遵循一致的online video形式。
Occupancy Flow
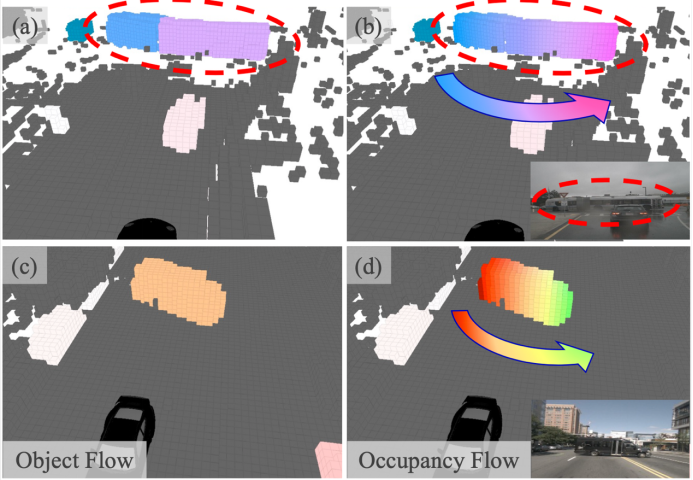
已有方法中,利用数据集目标框的标注来生成occ.的flow,但一目标框内的所有occ.都被赋了相同的值,如图中(a)和(c),这显然有违细粒度occ.感知任务的初衷。我们通过跟踪目标框内每个occ.点,制作了occ.级别的flow GT,如图(b)和(d)。通过可视化可以看到,对于旋转的车辆,细粒度的occ. flow能表示出车头和车尾不同的速度方向,这种细粒度的4D场景表示在场景感知中具备更大的潜力。
实验部分
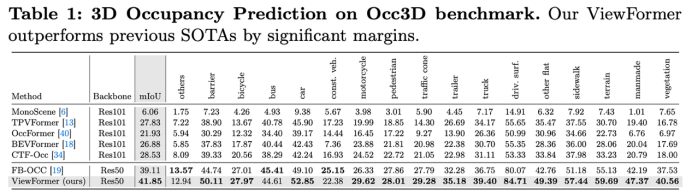
相同基准下我们超过了Occ3D数据集第一界竞赛的冠军方案FB-OCC 2.74个百分点。其他更多基准以及数据集的比较可以从文中查看。
消融实验
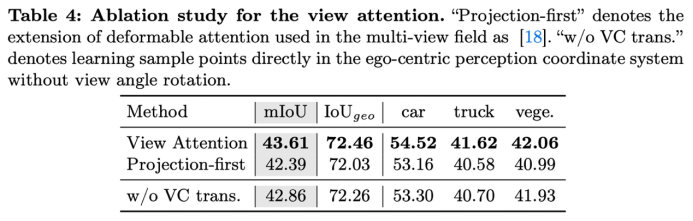
在对learning-first的view attn.消融实验中,与projection-first方法相同复杂度下,view attn. 模块能直接提升1.2个百分点。是否将可学习的点集定义在view坐标系下(VC),确实影响精度,补充材料里也详细比较了收敛速度问题。
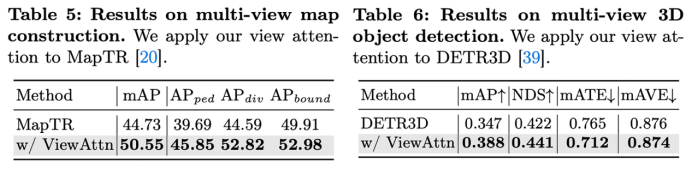
我们也将view attn.移植到了地图构建算法MapTR和3D目标检测算法DETR3D中,去分别替换掉他们方法的多视图特征提取模块(其均是类似projection-first方案),显著提升的性能表示projection-first方案确实对多种任务性能阻碍,在上述两个需求大感受野的目标级别任务上该问题会更凸显一些。
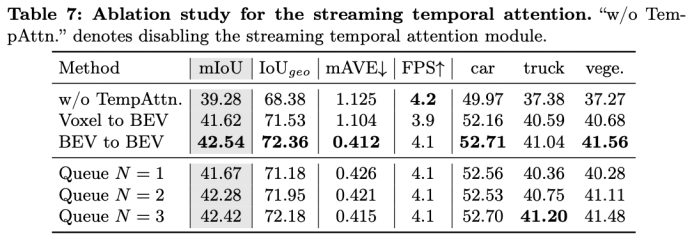
时序部分的实验,temporal modeling部分相较单帧感知提升了3.26 mIoU,可以看到同时与多帧交互能带来稳定提升,我们实验中历史帧大于4帧之后这部分带来的增益就不再增加了。由于历史帧特征都是在online video数据流中暂存在memory queue中的,与多帧交互几乎不增加训练和推理耗时。
可视化
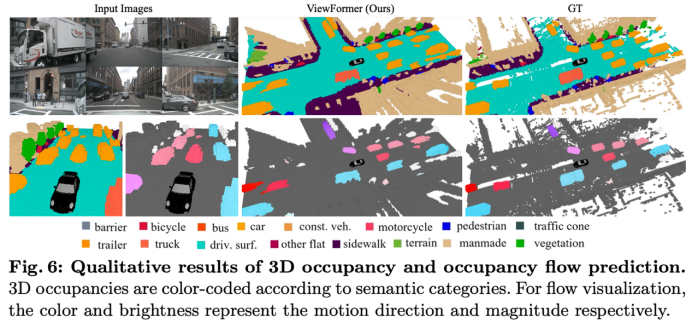
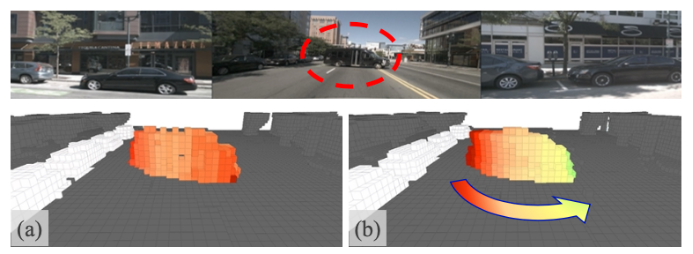
上图(a)和(b)分别是以objection flow为GT和occ. flow为GT训练的网络预测的flow结果,可以看到对于旋转的车辆,occ. flow可以更有意义的表示出车辆旋转的动态。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 网页端官网:www.zdjszx.com
网页端官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









