






点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
添加微信号:CVer111,小助手会拉你进群!
扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,及最前沿应用!发论文/搞科研/涨薪,强烈推荐!

作者:1335(已授权CVer转载)
https://zhuanlan.zhihu.com/p/710727313

主页:https://openimaginglab.github.io/emm/
论文:https://arxiv.org/pdf/2402.11957
代码:github.com/OpenImagingLab/emm
数据集:https://drive.google.com/drive/
在高频小运动放大过程中(眼球扫视的频率可以达到每秒100次),如果相机的帧率不够快,无法跟上运动的最快变化,就会出现“模糊”或“失真”的现象。因此,传统的相机系统不适合用于这种需要精细放大的高频小运动。然而,这些高速相机的特点是价格昂贵、需要大量存储空间,而且空间分辨率有限。虽然高速相机可以解决这个问题,但它们价格昂贵、存储需求大,而且空间分辨率有限。因此我们将目光放在了事件相机上。
事件相机(EVS)是一种新型仿生相机。它不像传统相机那样定时拍照记录每个像素的rgb信息,而是记录每个像素点的亮度变化。具体来说,时间相机每个像素独立工作,当检测到亮度变化超过阈值时,该像素会立即生成一个事件(event),记录下变化的时间和位置。这种处理信息的方式和人眼感知世界的方式类似,会重点记录图片中运动、变化的信息,这能大大降低数据冗余。同时,事件相机的时间分辨率非常高,可以达到微秒级别。这意味着它可以捕捉到非常快速的运动而不会出现模糊。
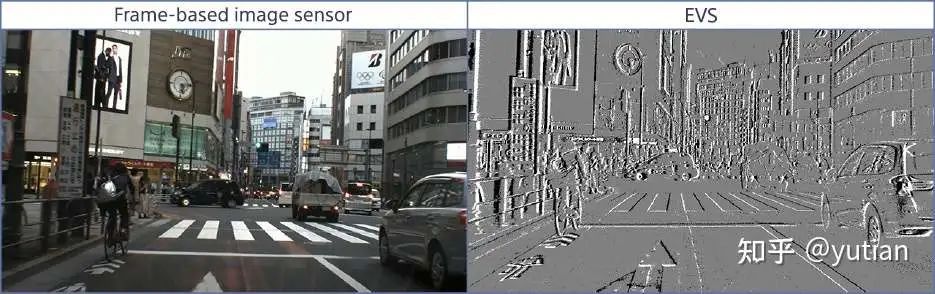
因此,从直观感受上,传统低帧率相机可以提供RGB信息,时间相机可以提供快速运动的信息,这两种相机的组合似乎是解决运动放大问题的最佳方案。同时,我们也分别通过公式推导和实验验证两种方式证明了事件相机+低帧率RGB相机的组合能给运动放大提供足够的信息,具体细节可以参考我们的论文。据我们所知,这是首个利用事件流和RGB 图像来放大高频运动的系统。
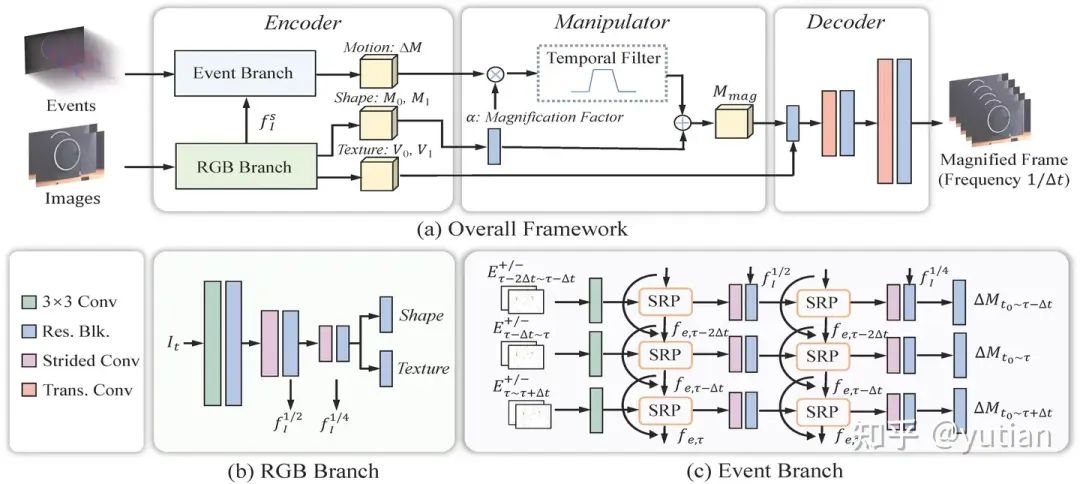
模型的设计
为了增强系统在各种复杂场景中的适应性,根据上文提到的公式,我们专门针对基于事件相机的运动放大任务设计了一个模型。我们的网络包括以下三个部分:1) 一个编码器(Encoder),用于提取纹理、形状和运动表示;2) 一个操控器(Manipulator),用于放大运动;3) 一个解码器(Decoder),用于重建高帧率的运动放大 RGB 视频。在编码器阶段,为了应对大帧数插帧的挑战并最小化伪影,采用了二阶递归传播(SRP)策略来提取特征。与之前的基于事件的插帧方法和运动放大方法相比,SRP 能更好地建模长期信息。在操控阶段,与传统的基于事件的插值方法不同,我们提取了与运动幅度具有线性关系的隐式运动表示。这种提取方法允许在测试阶段对运动表示应用时间滤波器,有效地滤除噪声并隔离运动信息,从而实现更清晰的运动放大。
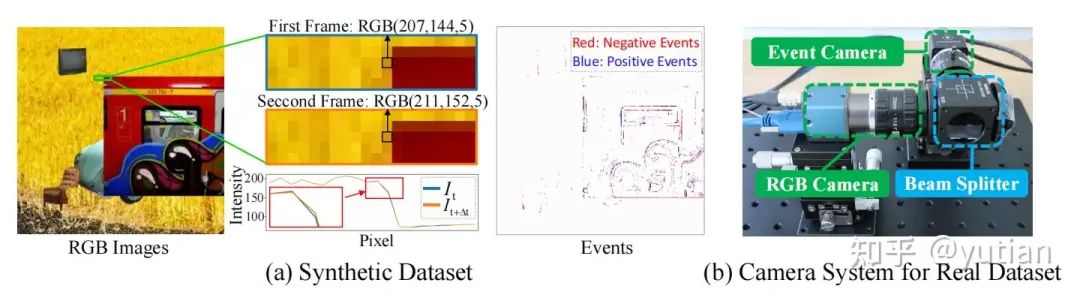
数据集的构造
为了提供用于基于事件的运动放大的训练数据,我们开发了首个包含事件信号和 RGB 信号的亚像素运动数据集,称为 SM-ERGB(Sub-pixel Motion Event-RGB Datset)。该数据集包含一个合成的数据集(SM-ERGB-Synth)和一个实拍的数据集(SM-ERGB-Real),旨在为该领域建立 benchmark。在创建 SM-ERGB-Synth 时,我们参考了 LVMM [1] 中的方法,通过将前景贴图到背景场景上,构建了包含亚像素运动的 RGB 序列及其对应的ground-truth真实放大运动序列。SM-ERGB-Synth 中的事件信号是使用 V2E 事件模拟器 [2] 生成的。为了验证我们的方法在实际场景中的效果,我们还搭建了一个双摄像头系统(如下图所示),以捕捉高质量的实际测试集SM-ERGB-Real。SM-ERGB-Real 数据集重点关注展示小型高频运动的场景,例如 512Hz 的调音叉。我们的实验验证表明,基于 SM-ERGB 的模拟数据训练的方法在实际场景中具有强大的泛化能力,能够有效而准确地恢复物体的固有频率。
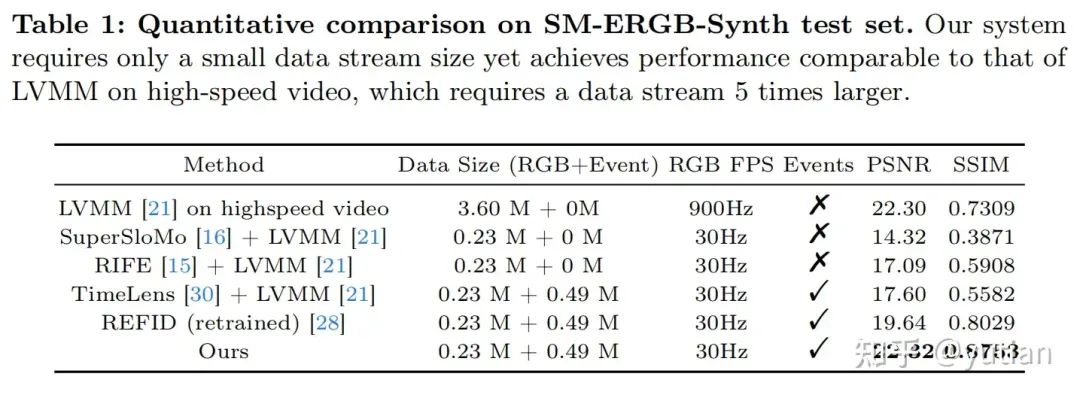
实验结果
在仿真数据集SM-ERGB-Synth,我们对不同方法进行了定量对比。从下表的数值结果中可以看出,我们提出的网络可以用最少的数据量得到最好的运动放大效果。
在真实拍摄的数据集SM-ERGB-Real上,我们进行了可视化对比。由下图可以看到,在110Hz的吉他弦上,我们的运动放大方法能恢复出正确的运动频率。

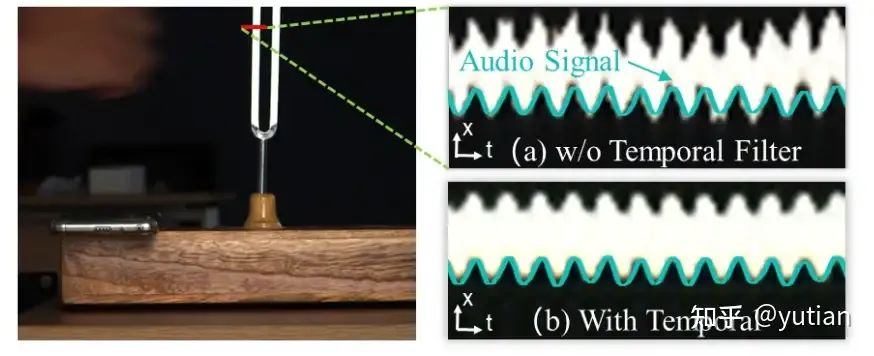
同时,在256Hz的音叉上,我们方法放大的波形和同步录制的声音波形具有很强的一致性。更多结果可以看我们的视频demo:Event-Based Motion Magnification_哔哩哔哩_bilibili。
何恺明在MIT授课的课件PPT下载
在CVer公众号后台回复:何恺明,即可下载本课程的所有566页课件PPT!赶紧学起来!
ECCV 2024 论文和代码下载
在CVer公众号后台回复:ECCV2024,即可下载ECCV 2024论文和代码开源的论文合集CVPR 2024 论文和代码下载
在CVer公众号后台回复:CVPR2024,即可下载CVPR 2024论文和代码开源的论文合集Mamba、多模态和扩散模型交流群成立
扫描下方二维码,或者添加微信号:CVer111,即可添加CVer小助手微信,便可申请加入CVer-Mamba、多模态学习或者扩散模型微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF、3DGS、Mamba等。
一定要备注:研究方向+地点+学校/公司+昵称(如Mamba、多模态学习或者扩散模型+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer111,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集上万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号
整理不易,请赞和在看
















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









